何恺明等最新突破:视频识别快慢结合,取得人体动作AVA数据集最佳水平
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~

译者 | Linstancy
整理 | Jane
出品 | AI科技大本营
【导语】继图像领域之后,现在的 CV 领域,大家都在研究哪些内容?近日,Facebook AI 实验室的 Christoph Feichtenhofer、何恺明等人发表一篇论文,在视频识别领域提出了一种 SlowFast 网络,并且在没有预训练模型情况下,此网络在 Kinetics 数据集上取得79.0% 的准确率,是当前该数据集上的最佳表现。在 AVA 动作检测数据集上,同样实现了 28.3 mAP 的最佳水准。
到底 SlowFast 网络是怎样的设计、有什么特征、效果如何,下面就一起来看一下~
对于图像识别任务,给定一张图像 I(x, y),对称地处理图像的空间维度 x、y 是一种很常见的做法,而自然图像的统计数据也证明了这种做法的合理性—自然图像具有各向同性(即所有方向具有相同的可能性)和平移不变性。
然而,对于视频信号 I(x, y, t)而言,我们不能这样对称地处理时空信号。因为动作是方向的时空产物,但并非所有的时空方向都拥有相同的可能性。如果这样,那么我们就不能像基于时空卷积(spatiotemporal convolutions)的视频识别方法那样,对称地处理空间和时间信息。相反,我们需要分解这种结构,并分开处理空间结构和时间事件。
受此启发,本研究提出了一种用于视频识别的 SlowFast 双路径模型,一条路径 slow pathway 更关注空间域的语义信息,以低帧率,缓慢的刷新速度运行,用于捕获图像或几个稀疏帧提供的语义信息;而另一条路径 fast pathway 以高时间分辨率、快速刷新在所有中间层运行,捕获快速变化的动作信息,轻量级,整体的计算开销小。此外,这种快慢结合的双路径二者在结构上通过侧向连接(lateral connection)进行融合,以不同的速率处理原始视频。
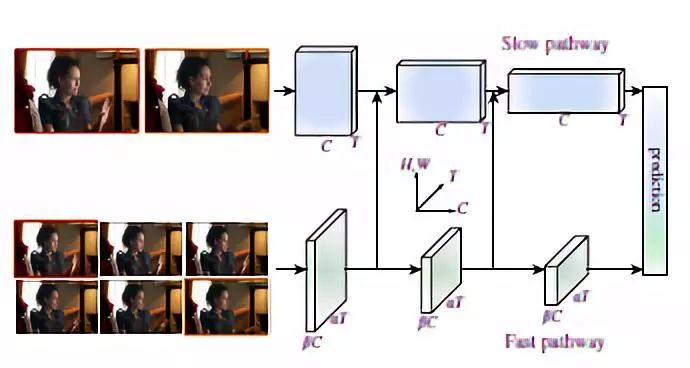
图1 SlowFast 网络由低帧率、低时间分辨率的 Slow 路径和高帧率、高时间分辨率 (是 Slow 路径时间分辨率的 α 倍) 的 Fast 路径构成。使用减少通道容量轻量化 Fast 路径,并通过侧向连接的方式连接 Slow 路径和 Fast 路径。图中该样本来自 AVA 数据集。
SlowFast 模型
如上图所示,SlowFast 网络的整体结构,包含 Slow pathway、Fast pathway 及其侧向连接(lateral connection)部分。其中,Slow pathway 可以是任意的卷积模型,用于处理视频的空间信息体量。为了与 Slow pathway 对应,Fast pathway 也是卷积结构的模型,但需要具有高帧率,高时间分辨率、低通道容量等特点。
为了将快慢两条途径的信息融合在一起,作者采用侧向连接(lateral connection)的方式来实现。侧向连接技术已被广泛用于融合基于光流的双流网络,而在图像目标检测任务中,横向连接作为一种流行的融合的技术,能够将空间分辨率和语义水平特征融合在一起。在这里作者在快慢路径之间引入一个横向连接,即每个“阶段”的两条路径(如上图1所示)。具体而言,对于 ResNets 网络,这些侧向连接分别在 pool1,res2,res3 和 res4 层之后。而对于 slow-fast 网络,由于两条路径存在差异,因此侧向连接需要通过转换过程以便匹配各自的路径,即采用单向连接的方式来将 Fast 的特征融合到 Slow 路径上。最后,在每条路径的输出后引入一个全局平均池化操作,并将两个池化特征向量连接,作为全连接分类层的输入。更多具体的信息可以查看论文中的详细介绍。
值得一提的是,这种快慢结合方法是受到灵长类视觉系统中视网膜神经节细胞的生物学研究启发的。生物学研究结果发现,在这些细胞中约 80% 是小细胞 P-cell,它能够提供良好的空间细节和颜色,但时间分辨率较低;而另外有大约 15-20% 的细胞是大细胞 M-cell,它以较高的时间频率工作,对时间变化更加敏感,但对空间细节和颜色不敏感。SlowFast 网络的提出正是受此启发,两条路径构成,分别以低时间分辨率和高时间分辨率工作,对应于 P-cell 和 M-cell 的作用。
SlowFast 是一种通用的网络框架,可以进行实例化,适配各种的主干网络。在这里,作者所采用的 SlowFast 网络参数如下图2所示:
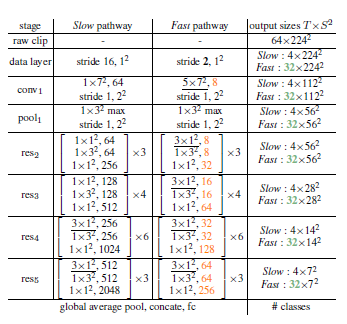
图2 SlowFast 网络的实例化。核维度表示为 {T×S^2 , C},其中 T 表示时间分辨率,S 表示空间语义而 C 表示通道数。步长表示为 {temporal stride, spatial stride^2}。此外,速度比率是α = 8,通道比率是 β = 1/8。τ = 16。图中绿色表示 Fast 路径较高的时间分辨率,橙色表示 Fast 路径较少的通道数,下划线表示非退化时间滤波器(non-degenerate temporal filter)。方括号内表示的是残差块结构。骨干网络采用的是 ResNet-50。
实验
SlowFast 网络在 Kinetics 和 AVA 数据集上具体表现如何?我们通过研究中的一些实验数据对比看一下各数据结果。
▌Kinetics 数据集的动作分类
对于视频动作分类,作者采用 Kinetics-400 数据集,其中包含约 240k 个训练视频数据和20k个验证数据,共涵盖400种动作类别。实验结果得到 Top1 和 Top5 的分类准确性,单条 Slow 网络与 SlowFast 网络的性能对比,以及 SlowFast 网络与 Kibetics-400 数据集上当前最佳模型之间的性能对比,详细结果如下图3,图4,图5所示。
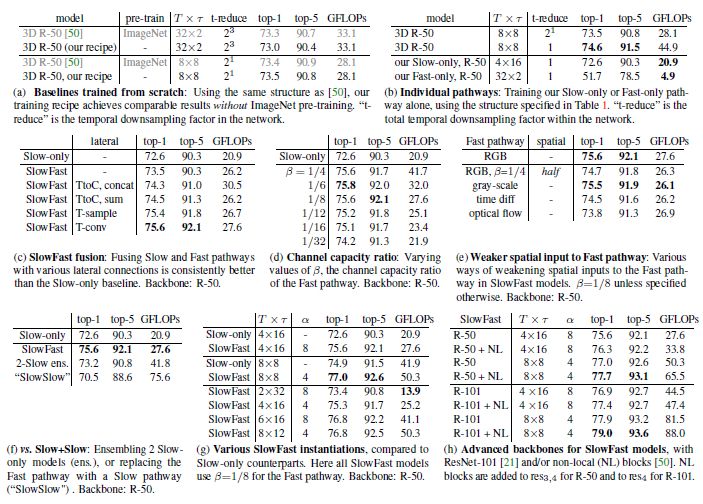
图3 Kinetics-400 数据集动作分类结果,包括 top-1 和 top-5 分类准确度,以及计算复杂度 GFLOPs。
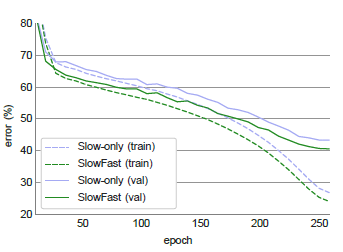
图4 Kinetics-400 数据集上 Slow-only 网络与 SlowFast 网络的性能对比;top-1 训练误差 (虚线表示) 和验证误差 (实线表示)。
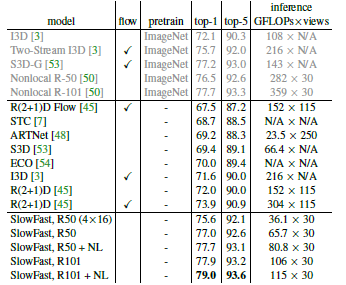
图5 Kinetics-400 数据集上当前最佳模型与 SlowFast 网络的性能对比。
▌AVA 数据集的动作检测
对于视频动作检测,作者采用 AVA 数据集,其中包含有 211k 个训练数据和 57k 个验证数据,共涵盖 60 种动作类别。实验结果得到 60 个类别的平均精度 mAP 值,SlowFast 网络与 AVA 数据集上当前最佳模型之间的性能对比,以及 AVA 数据集动作检测结果的可视化过程,详细结果如下图 6,图 7,图 8 所示。
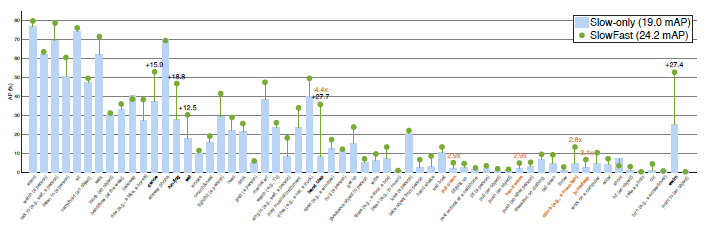
图6 AVA 数据集上每个类别的 AP:Slow-only 模型的 19.0 mAP vs. SlowFast 模型的 24.2 mAP。其中,黑色突出显示的是绝对增长最高的5个类别,而这里实例化的 SlowFast 网络并不是最佳的模型。
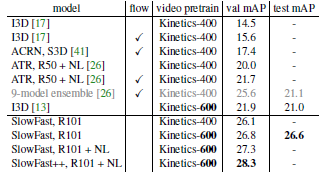
图7 AVA 数据集上最佳模型与 SlowFast 网络的性能对比。其中,++ 表示在测试过程引入了诸如水平翻转的图像增强操作。
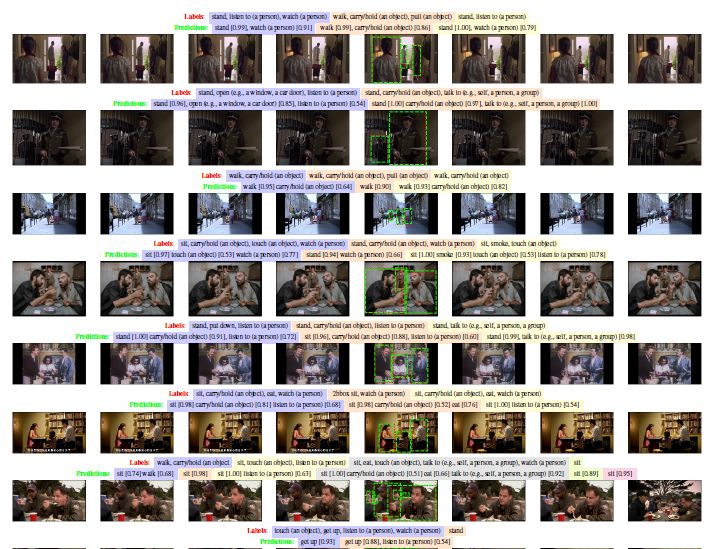
图8 可视化 AVA 数据集的动作检测结果。其中真实的标签用红色表示,而 SlowFast 模型在验证集上的预测结果用绿色表示。
总结
本文提出了一种用于视频识别的 SlowFast 网络。该模型由两部分组成:以低帧率运行以捕捉空间语义信息的 Slow pathway;以高帧率运行捕捉较好时序分辨率的运动信息的 Fast pathway。通过减少通道容量,所设计的 Fast pathway 是个非常轻量级的、同时又能够将学习到有用的时间信息用于视频识别的网络。
SlowFast 网络在视频动作分类及检测任务上展现了强大的性能,同时这种快慢结合思想的提出也为视频目标识别和检测领域做出了重要贡献。实验结果表明,在没有使用任何预训练模型的情况下,SlowFast 网络在 Kinetics 数据集上取得了 79.0% 的准确率,大大超过了以前同类方法的最佳结果。而在 AVA 动作检测数据集上,该网络同样实现了 28.3 mAP 的当前最佳水准。
总的来说,时间维度是视频任务中一个特殊的因素,本文的 SlowFast 网络框架考虑时间维度上不同的速度对时空信息捕捉的影响,实例化的 SlowFast 模型在 Kinetics 和 AVA 数据集上实现当前最佳的视频动作分类和检测结果,希望这种快慢结合的设计理念能够促进视频识别领域未来的研究。有关的项目代码将会在近期开源。
论文地址:
https://arxiv.org/abs/1812.03982
*推荐文章*
更侧重工业的应用:PRCV2018美图短视频实时分类挑战赛冠军技术方案
重磅!ImageNet 并非必要?何恺明新作:Rethinking ImageNet Pre-training 论文详解及问答
一文看尽2018全年计算机视觉大突破
CVPR2018 目标检测算法总览(最新的目标检测论文)
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~




