如何评价ST-GCN动作识别算法?
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
香港中大-商汤科技联合实验室的 AAAI 会议论文「Spatial Temporal Graph Convolution Networks for Skeleton Based Action Recognition」,提出了一种新的 ST-GCN,即时空图卷积网络模型,用于解决基于人体骨架关键点的人类动作识别问题,本文是对这一工作的解读分析。
作者 | 纵横
论文 | https://arxiv.org/pdf/1801.07455.pdf
来源 |
https://www.zhihu.com/question/276101856/answer/638672980
质胜文则野,文胜质则史,文质彬彬,然后君子。
GCN 升温的这两年里,动作识别领域出了不少好文章。这也不奇怪,毕竟动作识别以前就有 Graph 的相关应用,套用一下 GCN 总是会有提升的。不过,一年过去了,超过 Spatial Temporal Graph Convolution Networks for Skeleton Based Action Recognition 的工作仍然寥寥可数。我等屁民还是挺佩服的~
还在这个领域耕耘的同学们也不用灰心丧气,ST-GCN 作为一篇开山作(或者说占坑文),很多地方都从简了。要想提升不太困难~ 用大粗话来说,作者的主要工作就两点:
使用 OpenPose 处理了视频,提出了一个数据集
结合 GCN 和 TCN 提出了模型,在数据集上效果还不错
但是,这篇文章在工程和学术上都做到了文质彬彬:
从质上讲,文中针对性的改进着实有效,结果比较令人满意
从文上讲,故事讲的很棒,从新的视角整合了卷积、图卷积和时间卷积
从代码讲,结构清晰、实现优雅,可以当做模板
很多同学比较关心 st-gcn 到底做了什么,这里用个简单的思路说说我的理解。
OpenPose 预处理
OpenPose 是一个标注人体的关节(颈部,肩膀,肘部等),连接成骨骼,进而估计人体姿态的算法。作为视频的预处理工具,我们只需要关注 OpenPose 的输出就可以了。

总的来说,视频的骨骼标注结果维数比较高。在一个视频中,可能有很多帧(Frame)。每个帧中,可能存在很多人(Man)。每个人又有很多关节(Joint)。每一个关节又有不同特征(位置、置信度)。
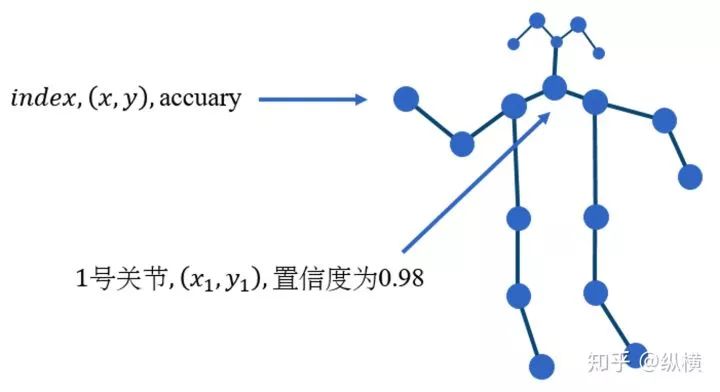
对于一个 batch 的视频,我们可以用一个 5 维矩阵 
代表视频的数量,通常一个 batch 有 256 个视频(其实随便设置,最好是 2 的指数)。
代表关节的特征,通常一个关节包含
等 3 个特征(如果是三维骨骼就是 4 个)。
代表关键帧的数量,一般一个视频有 150 帧。
代表关节的数量,通常一个人标注 18 个关节。
代表一帧中的人数,一般选择平均置信度最高的 2 个人。
所以,OpenPose 的输出,也就是 ST-GCN 的输入,形状为
。







想要搞 End2End 的同学还是要稍微关注一下 OpenPose 的实现的。最近还有基于 heatmap 的工作,效果也不错~
ST-GCN 网络结构
论文中给出的模型描述很丰满,要是只看骨架,网络结构如下:

主要分为三部分:

首先,对输入矩阵进行归一化,具体实现如下:
N, C, T, V, M = x.size()# 进行维度交换后记得调用 contiguous 再调用 view 保持显存连续x = x.permute(0, 4, 3, 1, 2).contiguous()x = x.view(N * M, V * C, T)x = self.data_bn(x)x = x.view(N, M, V, C, T)x = x.permute(0, 1, 3, 4, 2).contiguous()x = x.view(N * M, C, T, V)
归一化是在时间和空间维度下进行的( 
这个操作是利远大于弊的:
关节在不同帧下的关节位置变化很大,如果不进行归一化不利于算法收敛
在不同 batch 不同帧下的关节位置基本上服从随机分布,不会造成不同 batch 归一化结果相差太大,而导致准确率波动。

接着,通过 ST-GCN 单元,交替的使用 GCN 和 TCN,对时间和空间维度进行变换:
# N*M(256*2)/C(3)/T(150)/V(18)Input:[512, 3, 150, 18]ST-GCN-1:[512, 64, 150, 18]ST-GCN-2:[512, 64, 150, 18]ST-GCN-3:[512, 64, 150, 18]ST-GCN-4:[512, 64, 150, 18]ST-GCN-5:[512, 128, 75, 18]ST-GCN-6:[512, 128, 75, 18]ST-GCN-7:[512, 128, 75, 18]ST-GCN-8:[512, 256, 38, 18]ST-GCN-9:[512, 256, 38, 18]
空间维度是关节的特征(开始为 3),时间的维度是关键帧数(开始为 150)。在经过所有 ST-GCN 单元的时空卷积后,关节的特征维度增加到 256,关键帧维度降低到 38。
个人感觉这样设计是因为,人的动作阶段并不多,但是每个阶段内的动作比较复杂。比如,一个挥高尔夫球杆的动作可能只需要分解为 5 步,但是每一步的手部、腰部和脚部动作要求却比较多。

最后,使用平均池化、全连接层(或者叫 FCN)对特征进行分类,具体实现如下:
# self.fcn = nn.Conv2d(256, num_class, kernel_size=1)# global poolingx = F.avg_pool2d(x, x.size()[2:])x = x.view(N, M, -1, 1, 1).mean(dim=1)# predictionx = self.fcn(x)x = x.view(x.size(0), -1)
Graph 上的平均池化可以理解为对 Graph 进行 read out,即汇总节点特征表示整个 graph 特征的过程。这里的 read out 就是汇总关节特征表示动作特征的过程了。通常我们会使用基于统计的方法,例如对节点求 
插句题外话,这里的
GCN
从结果上看,最简单的图卷积似乎已经能取得很好的效果了,具体实现如下:
def normalize_digraph(A):Dl = np.sum(A, 0)num_node = A.shape[0]Dn = np.zeros((num_node, num_node))for i in range(num_node):if Dl[i] > 0:i] = Dl[i]**(-1)AD = np.dot(A, Dn)return AD
作者在实际项目中使用的图卷积公式就是:

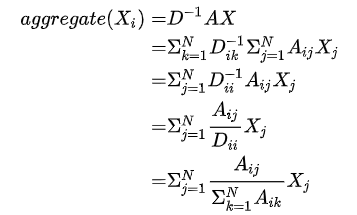
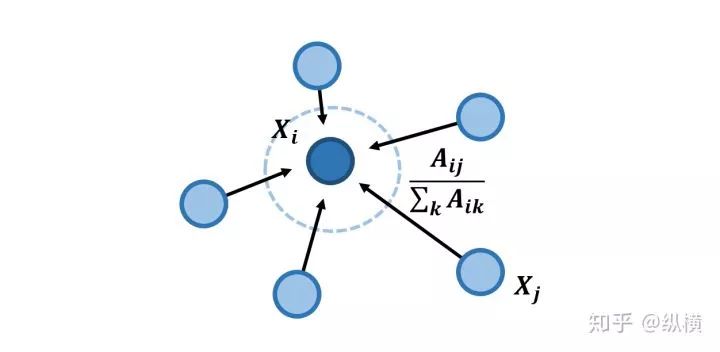
其实就是以边为权值对节点特征求加权平均。其中, 
Multi-Kernal
考虑到动作识别的特点,作者并未使用单一的卷积核,而是使用『图划分』,将 

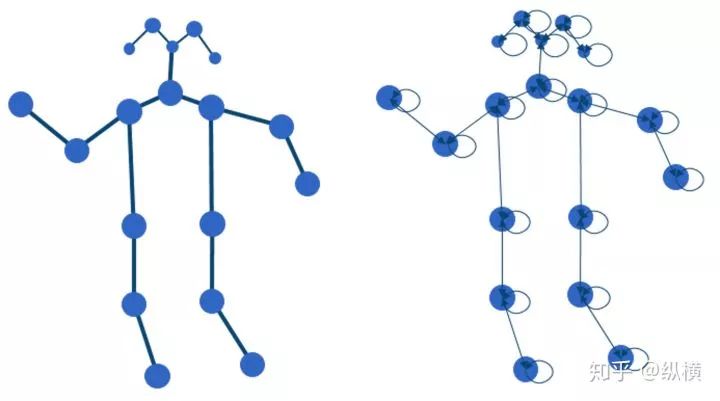
两个节点之间有一条双向边
节点自身有一个自环
作者结合运动分析研究,将其划分为三个子图,分别表达向心运动、离心运动和静止的动作特征。
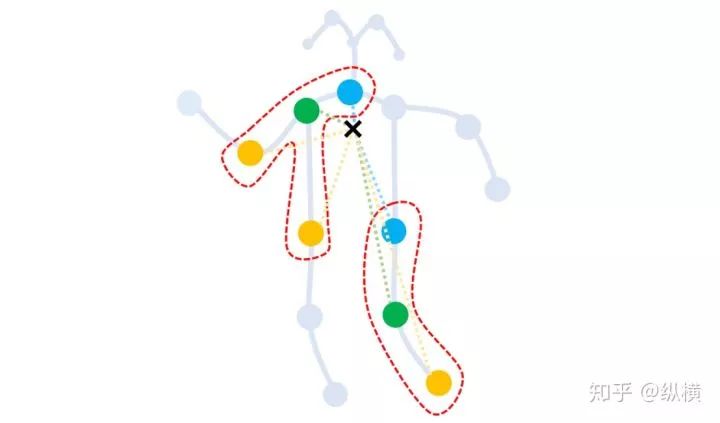
对于一个根节点,与它相连的边可以分为 3 部分。
第 1 部分连接了空间位置上比本节点更远离整个骨架重心的邻居节点(黄色节点),包含了离心运动的特征。
第 2 部分连接了更为靠近重心的邻居节点(蓝色节点),包含了向心运动的特征。
第 3 部分连接了根节点本身(绿色节点),包含了静止的特征。
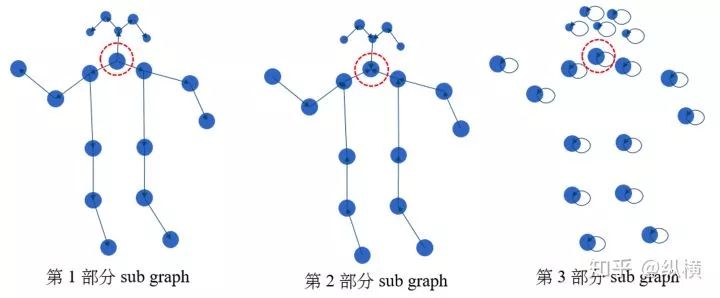
使用这样的分解方法,1 个图分解成了 3 个子图。卷积核也从 1 个变为了 3 个,即 

具体实现如下:
A = []for hop in valid_hop:a_root = np.zeros((self.num_node, self.num_node))a_close = np.zeros((self.num_node, self.num_node))a_further = np.zeros((self.num_node, self.num_node))for i in range(self.num_node):for j in range(self.num_node):if self.hop_dis[j, i] == hop:if self.hop_dis[j, self.center] == self.hop_dis[i, self.center]:a_root[j, i] = normalize_adjacency[j, i]elif self.hop_dis[j, self.center] > self.hop_dis[i, self.center]:a_close[j, i] = normalize_adjacency[j, i]else:a_further[j, i] = normalize_adjacency[j, i]if hop == 0:A.append(a_root)else:A.append(a_root + a_close)A.append(a_further)A = np.stack(A)self.A = A
Multi-Kernal GCN
现在,我们可以写出带有 

表达式可以用爱因斯坦求和约定表示 
表示所有视频中的人数(batch * man)
表示卷积核数(使用上面的分解方法 k=3)
表示关节特征数(64 ... 128)
表示关键帧数(150 ... 38)
和
表示关节数(使用 OpenPose 的话有 18 个节点)




对 
# self.conv = nn.Conv2d(# in_channels,# out_channels * kernel_size,# kernel_size=(t_kernel_size, 1),# padding=(t_padding, 0),# stride=(t_stride, 1),# dilation=(t_dilation, 1),# bias=bias)x = self.conv(x)n, kc, t, v = x.size()x = x.view(n, self.kernel_size, kc//self.kernel_size, t, v)x = torch.einsum('nkctv,kvw->nctw', (x, A))return x.contiguous(), A
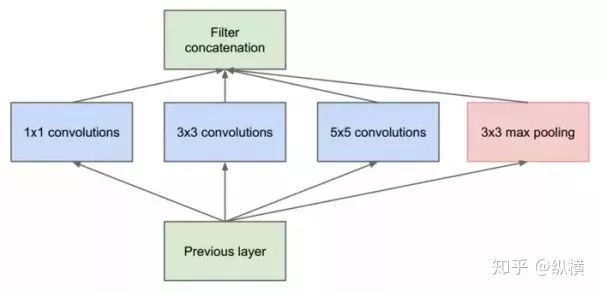
如果要类比的话,其实和 GoogleNet 的思路有些相似:
都在一个卷积单元中试图利用不同感受野的卷积核,提取不同分量的特征。
TCN
GCN 帮助我们学习了到空间中相邻关节的局部特征。在此基础上,我们需要学习时间中关节变化的局部特征。如何为 Graph 叠加时序特征,是图网络面临的问题之一。这方面的研究主要有两个思路:时间卷积(TCN)和序列模型(LSTM)。
ST-GCN 使用的是 TCN,由于形状固定,我们可以使用传统的卷积层完成时间卷积操作。为了便于理解,可以类比图像的卷积操作。st-gcn 的 feature map 最后三个维度的形状为 

图像的通道数
对应关节的特征数
。
图像的宽
对应关键帧数
。
图像的高
对应关节数
。


在图像卷积中,卷积核的大小为『w』
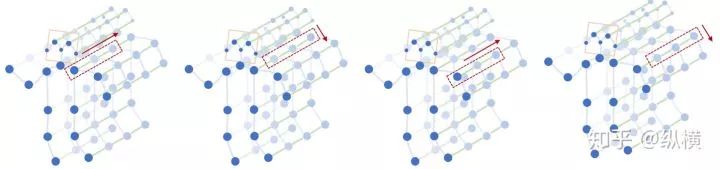
在时间卷积中,卷积核的大小为『temporal_kernel_size』
具体实现如下:
padding = ((kernel_size[0] - 1) // 2, 0)self.tcn = nn.Sequential(nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True),nn.Conv2d(out_channels,out_channels,(temporal_kernel_size, 1),(1, 1),padding,),nn.BatchNorm2d(out_channels),nn.Dropout(dropout, inplace=True),)
再列举几个序列模型的相关工作,感兴趣的同学可以尝试一下:
AGC-Seq2Seq 使用的是 Seq2Seq + Attention。
ST-MGCN 使用的是 CGRNN。
DCRNN 使用的是 GRU。
Attention
作者在进行图卷积之前,还设计了一个简易的注意力模型(ATT)。
# 注意力参数# 每个 st-gcn 单元都有自己的权重参数用于训练self.edge_importance = nn.ParameterList([nn.Parameter(torch.ones(self.A.size()))for i in self.st_gcn_networks])# st-gcn 卷积for gcn, importance in zip(self.st_gcn_networks, self.edge_importance):print(x.shape)x, _ = gcn(x, self.A * importance)
其实很好理解,在运动过程中,不同的躯干重要性是不同的。例如腿的动作可能比脖子重要,通过腿部我们甚至能判断出跑步、走路和跳跃,但是脖子的动作中可能并不包含多少有效信息。
因此,ST-GCN 对不同躯干进行了加权(每个 st-gcn 单元都有自己的权重参数用于训练)。
结束
上面的内容主要是在讲『文质彬彬』中的『质』,其实我感觉『文』才是比较难的部分。在写论文的过程中,找到一个好的视角,流畅地表达出模型的可解释性是非常可贵的。
研一这一年,导师都在教我如何讲好一个故事,与君共勉吧~
*延伸阅读
从CNN到GCN的联系与区别——GCN从入门到精(fang)通(qi)
何恺明等最新突破:视频识别快慢结合,取得人体动作AVA数据集最佳水平
极市干货|孙书洋 CVPR 2018论文详解:光流导向特征在视频动作识别中的应用
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~

