【技术分享】基于双流递归神经网络的人体骨架行为识别
行为识别主要研究视频序列中人的行为。传统的基于RGB视频的行为识别研究受光照、场景和摄像机镜头移动等因素影响很大,因此很难描述序列中人体的运动。由于深度传感器(比如Kinect)的成本的降低和实时的人体骨架关键点估计(pose estimation)算法的出现,基于人体骨架的行为识别研究越来越受欢迎。基于骨架的行为的输入为人体关键点的坐标的序列,可以很好的分析行为中人体的运动。
早期基于骨架的行为识别方法主要基于手工设计对行为分析有用的特征。这些手工特征的表达能力有限,不能适应大规模行为识别的任务。最近两年出现了一些端到端的基于递归神经网络(Recurrent Neural Networks, 简称RNN)的算法,可以直接处理原始数据并预测行为。这些方法把每个时刻的关键点坐标拼接成一个向量,不同的时间的坐标向量组成一个序列,然后采用RNN网络学习特征的表达并直接预测行为。实际上,人体不同关键点的数据是具有空间结构关系的。之前基于RNN的方法只考虑了骨架坐标随着时间的动态演变,而忽略了它们在某一个时刻的空间关系。
双流递归神经网络
因此,我们提出一种基于双流递归神经网络(Two-stream RNN)的方法,分别对骨架坐标的时间动态特性和空间相对关系建模,方法示意图如下图所示。
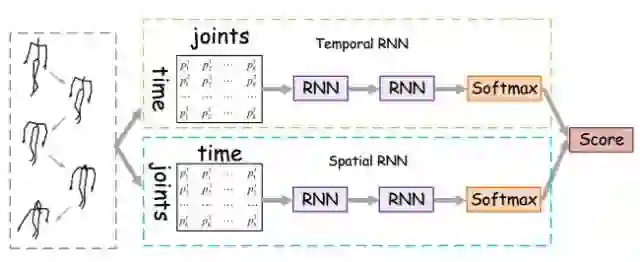
我们的方法采用两个RNN网络(时间通道的Temporal RNN和空间通道的Spatial RNN)处理人体骨架关键点数据,最后在分数层采用加权平均的方式融合。这两个网络可以作为一个端到端训练的整体。
时间通道
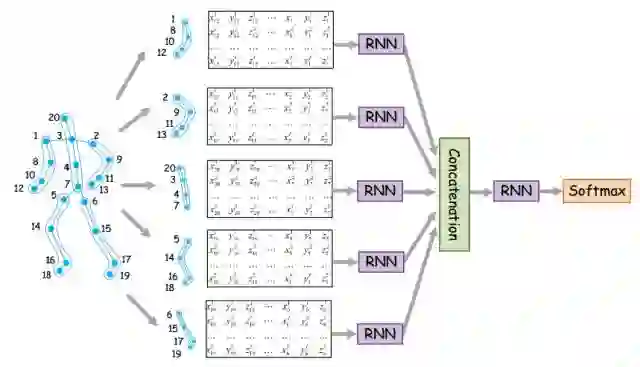
对于时间通道,Temporal RNN的处理方式和之前基于RNN的方法是一样的。也就是,把每个时刻的关键点坐标拼接成一个向量,采用RNN网络学习坐标随着时间的变化。这里,我们探索了两种不同的结构:多层RNN(Stacked RNN)和层次化RNN(Hierarchical RNN)。多层RNN就是简单的把单层RNN堆叠起来,上一层RNN的输出作为下一层RNN的输入。我们发现堆叠2~3层的时候,结果最好。层次化RNN是受到前有工作的启发,即把人体关键点分为5个部分(躯干,先对于每一部分的坐标点,把同一个时刻的坐标拼接成一个向量,采用RNN学习这一部分的运动。然后把不同部分在同一时刻RNN的输入拼接起来,再采用RNN网络学习整个人体的运动规律。层次化RNN的示意图如下图所示。
空间通道
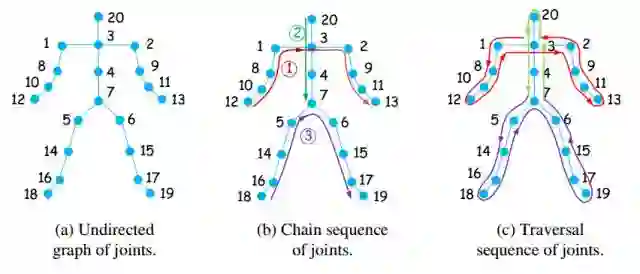
对于空间通道,Spatial RNN目的在于学习不同坐标点之间的连接关系。为了便于RNN处理,我们需要把关键点的图的结构转化为一个序列。举个例子,对于Kinect v1的数据,共有20个关键点,结构如下图(a)所示。我们尝试两种方法把把关键点的图的结构转化为一个序列。第一种方法(chain sequence),如下图(b)所示。根据物理连接关系,我们发现人体关键点可以划分为三个序列,即双手,躯干和双脚。于是我们简单的把这三个序列串联成一个序列。第二种方法(traversal sequence),如下图(c)所示。我们从人体中心点出发,采用遍历的方法,把所有的关键点都访问一遍。根据节点访问的先后顺序,输出一个序列。为了和chain sequence做对比,遍历的时候,我们先遍历双手,然后躯干,最后双脚。
坐标变换
对于基于骨架的行为识别,输入为人体关键点的三维坐标。为了增强网络的泛化能力和防止网络训练过程中出现过拟合,我们探究了基于三维坐标变换的数据增强技术,包括旋转、缩放和希尔变换。
我们只在训练的时候做坐标变换,测试的时候不做变换。旋转变换得到不同角度的坐标数据,可以增强模型对跨视角的识别能力。缩放变换改变坐标的大小,可以适应不同升高和体型的拍摄的人。希尔变换改变坐标的形状,可以增强模型的鲁棒性。
实验结果
NTU RGB+D是当前基于Kinect数据的行为识别研究最大的数据库,标准实验设置有两种,一种是cross subject,即测试集中的人和训练集中的人没有交集,另一种是cross view,即测试数据的拍摄角度和训练数据不同。SBU Interaction是交互式行为识别研究中常用的一个数据库。我们首先比较了不同RNN结构的方法的实验结果。
转自:智能感知与计算研究中心