【紫冬分享】基于人体骨架的行为识别


【今日聚焦】
相比图像视频,人体骨架视频可以很好地克服复杂背景、光照变化、外貌变化等不确定因素的影响,是一个重要且具有挑战性的计算机视觉任务。如何有效地从人体骨架序列中提取具有判别性的空间和时间特征是一个有待解决的问题。自动化所模式识别实验室提出基于人体骨架的行为识别方法,该成果发表在ECCV2018上。
成果论文:
Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning

Introduction
近几年基于人体骨架的行为识别已经有很多工作,这些工作在公开数据库上的精度都有很好的提升,但是仍然有一些问题没有解决:
1、人的运动是由各个part协调完成的,如行走不仅需要腿的运动,还需要手臂的运动维持身体平衡,但是大部分的工作将人体的关键点直接concatenate成vector, 然后输入到LSTM里面处理,这样是很难学习到人体结构的空间特征的。
2、现有的方法利用LSTM网络直接对整个骨架序列进行时序建模,然后利用最后一时刻的hidden state作为时序的表示,这样对于短时序是有效的,但是对于长时序序列,最后一时刻的状态很难表示整个序列的时序特征,也不能包含详细的时序动态特征。
针对上述这两个问题,自动化所模式识别实验室提出Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning [5]
Related works
Song et al. [1] 提出了spatial-temporal attention网络,在空间上利用注意机制选择人体重要的关节点信息,在时间上通过注意机制选择关键帧信息,通过spatial-temporal attention获取具有判别性的时空特征。
Zhang et al. [2] 提出了一个View adaptive recurrent neural networks,利用两个LSTM子网络回归骨架的空间旋转参数和空间平移参数,然后将骨架旋转到一个适合行为预测的角度,最后送入主LSTM网络预测行为类别。
Yan et al. [3] 提出了一个 Spatial Temporal Graph Convolutional Networks学习人体骨架序列的时空特征,这是第一个将GCN模型用着这个任务上的工作。
Li et al. [4] 提出利用一个hierarchical CNN网络学习空间上人体关节点之间的空间信息和序列之间的动态特征。
Methods
具体来说,[5]提出了通过空间推理和时序堆叠学习的方式建模鲁棒的空间和时间特征。图1是具体的网络模型:

图1 基于人体骨架行为识别的整理流程
在空间上,该模型将人体结构划分为多个身体部位,如:头、手臂、躯干、腿等结构,并提出利用一个残差图神经网络(residual graph neural network(RGNN))去建模各个身体部位之间的人体结构特征。具体流程如图2所示:

图2 空间结构划分解析流程
残差图神经网络residual graph neural network(RGNN)的详细操作如图3所示:
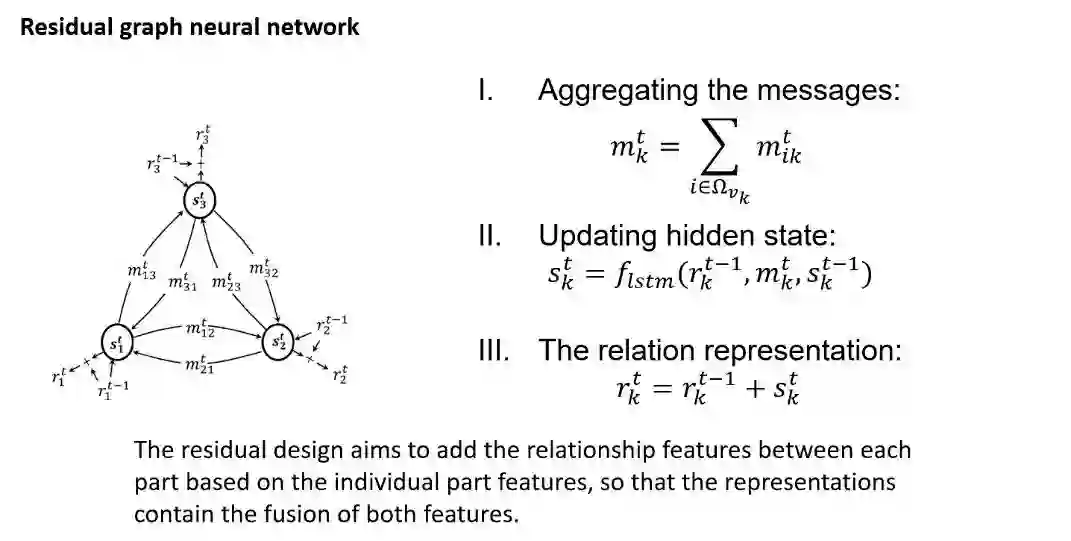
图3 残差图神经网络
在时序上,该模型包含了一个时序堆叠网络temporal stack learning network (TSLN),该网络可以获取详细的时序动态特征。
具体流程如图4所示:
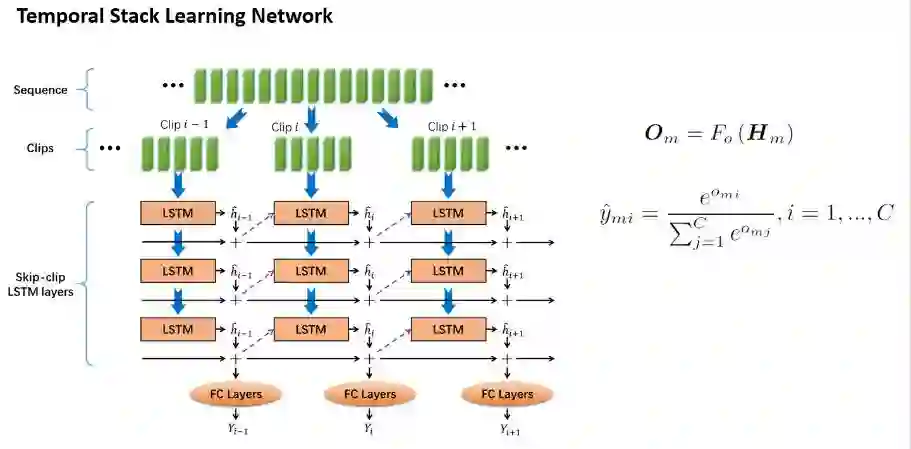
图4 时序堆叠网络结构
首先将长时序列划分成多个连续的短时clip,每个clip通过LSTM进行时序建模,不同clip之间的LSTM是参数共享的。每个短时序clip的最后一个隐含层的状态最为这个clip的表示,然后将该clip以及之前的所有clip的表示进行累加,列所包含的所有详细的动态特征。为了更好地保持表示从开始到该clip为止的长时序clip之间的时序关系,可以将这个详细的动态特征去初始化下一个clip的LSTM。
在此基础上,作者还提出一种增量式损失函数Clip-based Incremental Loss。该损失函数可以提升网络对细节行为的理解,不仅加速了网络的收敛,而且可以明显提升行为识别精度。
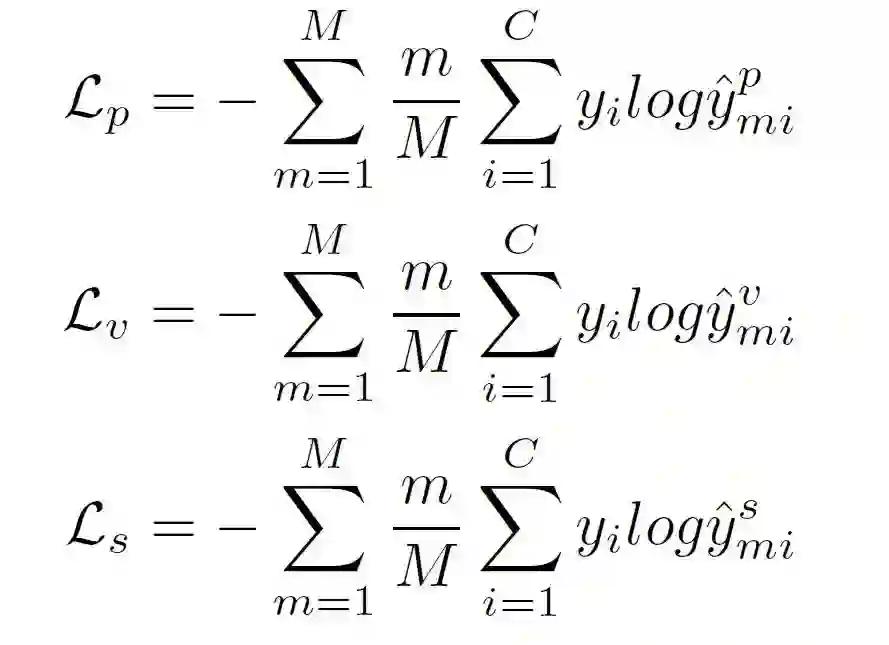
图5 损失函数的定义
Experiments
所提出的方法在以下两个行为识别数据集上验证了有效性,取得了当前最好的识别精度。
① 在NTU RGB+D数据集上的实验结果:
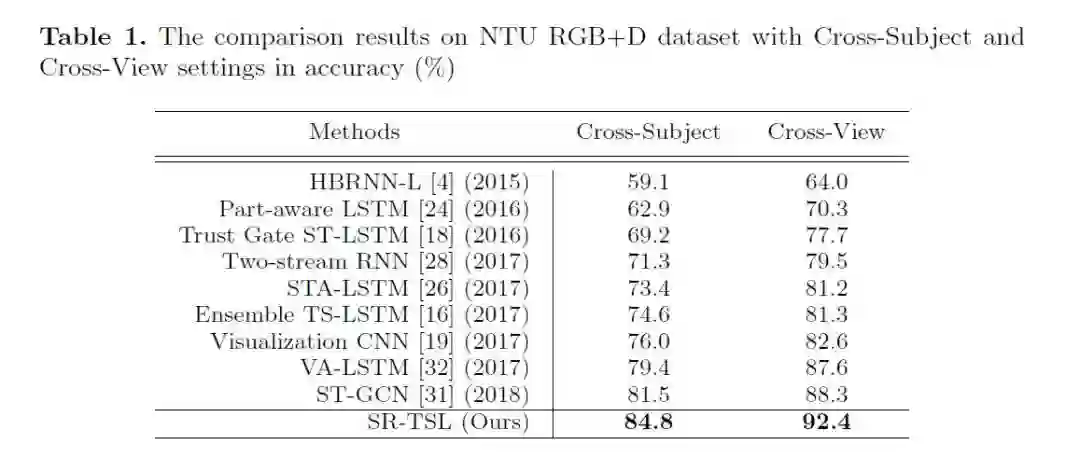
② 在SYSU 3D Human-Object Interaction dataset 上的实验结果:

Future
基于骨架序列的行为识别仍然是计算机视觉领域一个重要的研究方向,虽然这几年的算法在性能上有很大的提升,但是对于那些微小局部动作的识别还存在一些问题,仍然是非常具有挑战性的任务,存在很大的提升空间。
参考文献:
[1] Sijie Song, Cuiling Lan, Junliang Xing, Wenjun Zeng, Jiaying Liu. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In AAAI, 2018
[2] Pengfei Zhang, Cuiling Lan, Junliang Xing, Wenjun Zeng, Jianru Xue, Nanning Zheng. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In ICCV, 2017
[3] Sijie Yan and Yuanjun Xiong and Dahua Lin. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In AAAI, 2018
[4] Chao Li, Qiaoyong Zhong, Di Xie, Shiliang Pu. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. In IJCAI, 2018
[5] Chenyang Si, Ya Jing, Wei Wang, Liang Wang, and Tieniu Tan, Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning. In ECCV 2018.

Restricted Boltzmann Machine: 受限玻尔兹曼机以簧风琴(harmonium)之名(Smolensky, 1986)面世之后,成为了深度概率模型中最常见的组件之一。RBM是包含一层可观察变量和单层潜变量的无向概率图模型。RBM可以堆叠起来(一个在另一个的顶部)形成更深的模型。
AI爱新词

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
排版:松栩栩
编辑:鲁宁、欧梨成
文稿:SFFAI(人工智能前沿学生论坛)
来源:人工智能前沿讲习班

解锁更多智能之美

中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!



