AAAI 2018 | 时空图卷积网络:港中文提出基于动态骨骼的行为识别新方案
选自arXiv
作者:Sijie Yan、Yuanjun Xiong、Dahua Lin
机器之心编译
参与:陈韵竹
近日,香港中文大学提出一种时空图卷积网络,并利用它们进行人类行为识别。这种算法基于人类关节位置的时间序列表示而对动态骨骼建模,并将图卷积扩展为时空图卷积网络而捕捉这种时空的变化关系。
近年来,人类行为识别已经成为一个活跃的研究领域,它在视频理解中起着重要的作用。一般而言,人类行为识别有着多种模态(Simonyan and Zisserman 2014; Tran et al. 2015; Wang, Qiao, and Tang 2015; Wang et al. 2016; Zhao et al. 2017),例如外观、深度、光流和身体骨骼(Du, Wang, and Wang 2015; Liu et al. 2016)等。在这些模态当中,动态人类骨骼通常能与其他模态相辅相成,传达重要信息。然而,比起外观和光流建模,动态骨骼建模受到的关注较少。在这项工作中,我们系统地研究这种模态,旨在开发一种原则性且有效的方法模拟动态骨骼,并利用它们进行人类行为识别。
在 2D 或 3D 坐标形式下,动态骨骼模态可以自然地由人类关节位置的时间序列表示。然后,通过分析其动作模式可以做到人类行为识别。早期基于骨骼进行动作识别的方法只是在各个时间步骤使用关节坐标形成特征向量,并对其进行时序分析 (Wang et al. 2012; Fernando et al. 2015)。但这些方法能力有限,因为它们没有明确利用人类关节的空间关系,而这种空间关系对理解人类行为而言至关重要。最近,研究者开发了试图利用关节间自然连接的新方法 (Shahroudy et al. 2016; Du, Wang, and Wang 2015)。这些方法的改进令人鼓舞,表明了骨骼连通性的重要性。然而,现有的大多数方法依赖手动划分的部分或手动设定的规则来分析空间模式。因此,为特定应用设计的模型难以在其他任务中推广。
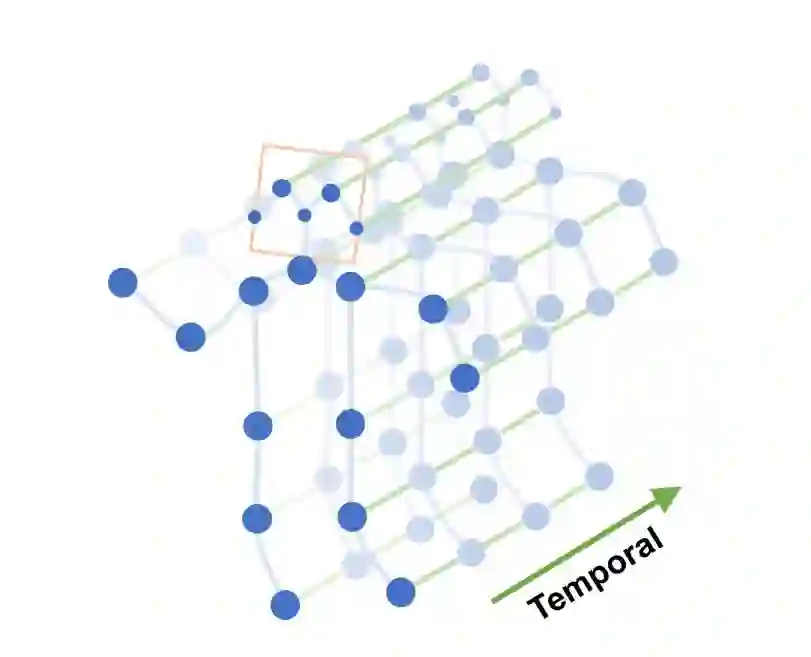
图 1:以上是本文所提出的骨骼序列的时空图,其中用到了所提出的 ST-GCN 操作。蓝点代表身体关节。身体关节之间的体内边(intra-body edge)根据人体自然连接定义。帧间边(inter-frame)连接相邻帧之间的相同关节。ST-GCN 中输入的是联合坐标。
为了跨越上述限制,我们需要一种新方法自动捕捉关节的空间构型、时间动态中所嵌入的模式。这就是深度神经网络的力量。然而,如前所述,骨骼并未以 2D 或 3D 网格的方式展现,而是以图像的形式展现。这就使得使用诸如卷积网络等已证实的模型变得困难。最近,将卷积神经网络(CNN)泛化到任意结构图形的图卷积网络(GCN)得到了越来越多的关注,而且被成功应用于图像分类 (Bruna et al. 2014)、文献分类 (Defferrard, Bresson, and Vandergheynst 2016)、半监督学习 (Kipf and Welling 2017) 等领域。但是,顺着这条思路,大部分前人的工作都把输入假定为一个固定的图形。GCN 在大规模数据集上的动态图模型应用,例如人类骨骼序列,还有待探索。
在本文中,我们通过将图卷积网络扩展到时空图模型,设计用于行为识别的骨骼序列通用表示,称为时空图卷积网络(ST-GCN)。如图 1 所示,该模型是在骨骼图序列上制定的,其中每个节点对应于人体的一个关节。图中存在两种类型的边,即符合关节的自然连接的空间边(spatial edge)和在连续的时间步骤中连接相同关节的时间边(temporal edge)。在此基础上构建多层的时空图卷积,它允许信息沿着空间和时间两个维度进行整合。
ST-GCN 的层次性消除了手动划分部分或遍历规则的需要。这不仅能获得更强的表达能力和更高的性能(如我们的实验所示),而且还使其易于在不同的环境中推广。在通用 GCN 公式化的基础上,我们还基于图像模型的灵感研究设计了图卷积核的新策略。
这项工作的主要贡献在于三个方面:1)我们提出 ST-GCN,一个基于图的动态骨骼建模方法,这是首个用以完成本任务的基于图形的神经网络的应用。2)我们提出了在 ST-GCN 中设计卷积核的几个原则,旨在满足骨骼建模的具体要求。3)在基于骨骼动作识别的两个大规模数据集上,我们的模型与先前使用的手动分配部分或遍历规则的方法相比,需要相当少的手动设计,实现了更优越的性能。ST-GCN 的代码和模型已公开发布 1。
流程概览
基于骨骼的数据可以从运动捕捉设备或视频的姿态估计算法中获得。通常来说,数据是一系列的帧,每一帧都有一组联合坐标。给定 2D 或 3D 坐标系下的身体关节序列,我们就能构造一个时空图。其中,人体关节对应图的节点,人体身体结构的连通性和时间上的连通性对应图的两类边。因此,ST-GCN 的输入是图节点的联合坐标向量。这可以被认为是一个基于图像的 CNN 模拟,其中输入由 2D 图像网格上的像素强度矢量形成。对输入数据应用多层的时空图卷积操作,可以生成更高级别的特征图。然后,它将被标准的 SoftMax 分类器分类到相应的动作类别。整个模型用反向传播进行端对端方式的训练。现在,我们将介绍 ST-GCN 模型的各个部分。
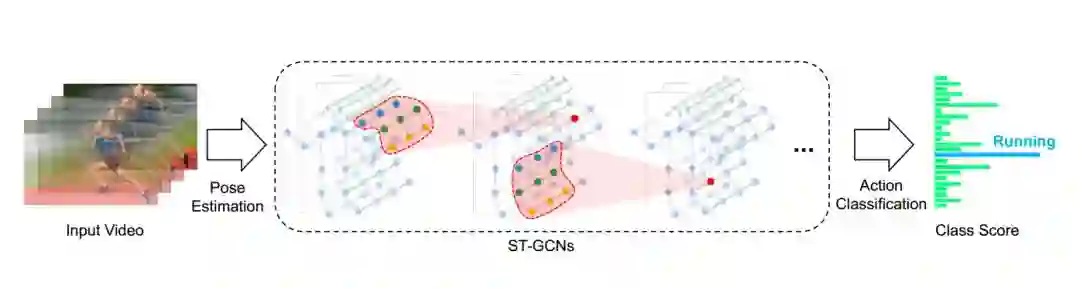
图 2:我们对视频进行姿态估计,并在骨骼序列上构建时空图。此后,对其应用多层时空图卷积操作(ST-GCN),并逐渐在图像上生成更高级的特征图。然后,利用标准的 Softmax 分类器,能将其分类到相应的操作类别中。
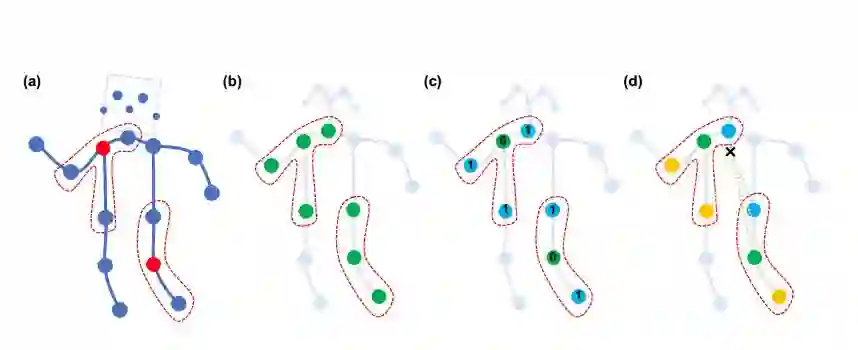
图 3:本文提出的用于构建卷积操作的分割策略。从左到右:(a)输入骨骼的框架示例。身体关节以蓝点表示。D=1 的卷积核感受野由红色的虚线画出。(b)单标签划分策略。其中近邻的所有节点标签相同(绿色)。(c)距离划分。这两个子集是距离为 0 的根节点本身,和距离为 1 的根节点相邻节点(蓝色)。(d)空间构型划分。根据节点到骨架重心(图中黑色十字)的距离和到根节点(绿色)的距离的比较进行标记。向心节点(蓝色)到骨架重心的距离比根节点到骨架重心的距离短,而离心节点(黄色)到骨架重心的距离比根节点长。

表 2:基于骨骼的模型在动力学数据集(Kinetics dataset)中的动作识别性能。在表格顶部,我们列出了基于帧的方法的性能。
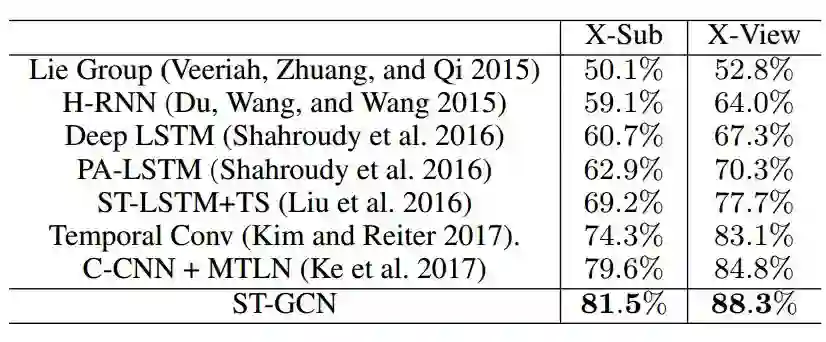
表 3:基于骨骼的模型在 NTU-RGB+D 数据集上的动作识别性能。本文根据交叉主题(X-Sub)和交叉视图(X-View)的基准进行准确率计算。
论文:Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition

论文链接:https://arxiv.org/abs/1801.07455
人体骨骼动力学为人类行为识别提供了重要信息。传统的骨骼建模方法通常依赖手动划分部分或遍历规则,导致模型表达能力有限、泛化困难。在这项工作当中,我们提出了一个名为时空图卷积网络(ST-GCN)的新型动态骨骼模型,它通过自主学习数据中的时间、空间模式,超越了以往方法的局限性,具有更强的表现力和泛化能力。在 Kinetics 和 NTU-RGBD 两大数据集中,本模型与主流方法相比有了很大的提高。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


