CubeSLAM:单目3D目标SLAM算法,已开源!
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:原野寻踪
https://zhuanlan.zhihu.com/p/69683253
本文已授权,未经允许,不得二次转载
前言
上一篇文章调研了RGBD相机的动态物体追踪的工作 MaskFusion:
https://zhuanlan.zhihu.com/p/62059382
文章的尺度主要还是限制在桌面上,拿起一些物体测试跟踪效果。离我所理解的物体级的SLAM还有一些差距。近期开始调研物体级的SLAM,这篇文章还不错: CubeSLAM: Monocular 3D Object SLAM, 它发表在 2019年 最近一期的 IEEE Transactions on Robotics上(2018年挂在arXiv上)。CubeSLAM用单目相机实现了物体级的建图、定位、和动态物体跟踪。

而这位华人作者Shichao Yang在CMU Robotics Institute实验室的导师指导下做工作。列一下他的其他工作:
Pop-up SLAM:一个很优秀的室内面slam work, IROS2016
Monocular Object and Plane SLAM in Structured Environments: 将CubeSLAM和 Pop-up-SLAM结合起来出的一篇 ,有时间再做它的分析。
我觉得他的探索思路是非常合理的:传统基于特征点的SLAM基本已没啥可做的了(有做的赶紧告诉我),点之上的高维表达包括线、面、物体,这些先验暂时无法做到通用,但在室内的结构环境下有不少可以尝试的点。必然需要解决这些物体的观测模型、地图中的表达、在BA中的融合数学模型等等。
对于语义SLAM来说,我们的前端有检测或分割图像的输入,而地图中物体的表达方式是什么呢?ICRA2019一篇:Structure Aware SLAM using Quadrics and Planes 探讨了用双曲面表达物体的方式。室内先验下 面、物体 如何在地图中表达,并以此形成一套观测、融合的体系,是至少目前还在研究的东西。
我们先回过头看CubeSLAM,CubeSLAM里则提出用立方体来建模物体,这是我们最直观的物体理解方式。它提出了整套观测误差函数,并放入ORBSLAM2的BA过程中统一优化。这里面提出几点很有价值的想法是:
如何从单目利用2D bounding box, 辅助Vanish Points(消影点) 来恢复三维立方体结构
如何在传统SLAM的静态假设上,将动态物体(车辆等)也追踪起来。实现相机位姿估计和运动物体位姿估计。
论文在室内SUN RGBD数据集和室外KITTI数据集做了完善的实验。
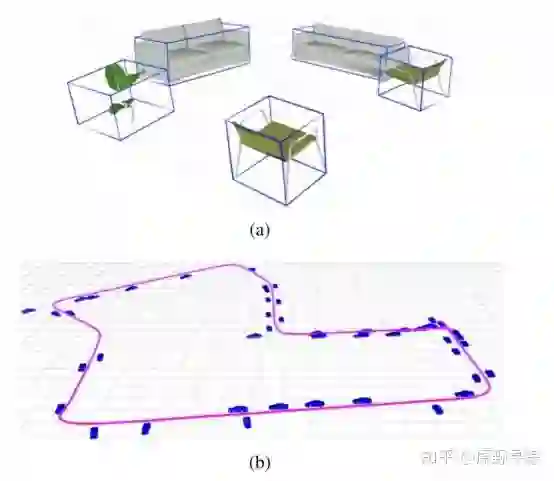
我将论文核心理论部分整理如下,欢迎一起讨论,也欢迎私信我指出错误。
代码开源情况
目前在github开放源码:https://github.com/shichaoy/cube_slam
亲测可用。然而开放的是纯物体级的SLAM代码,并没有如论文中整合ORB features的版本。作者给了室内数据集一个纯立方体的demo,跑起来很带感.

理论核心部分
III. Single Image 3D Object Detection
A. 3D box proposal generation
1) Principles
3Dbox用9个自由度描述,除了6维刚体变换外,还增加了3个dimension: 即长宽高.
由于一个前端矩形检测的四个端点只能提供4个约束,因而需要其他的信息。如:提供或预测的物体大小,以及朝向。(在许多车辆检测算法中用到)
我们使用VP来改变和减少回归参数,而不去预测依赖的维度。VP是平行线的相交点。一个3D cuboid有三个正交轴,因此可以形成3个VPs,而且只与物体旋转有关!

2) Get 2D corners from the VP
由于最多能看到3个立体面,我们考虑三种可能性。
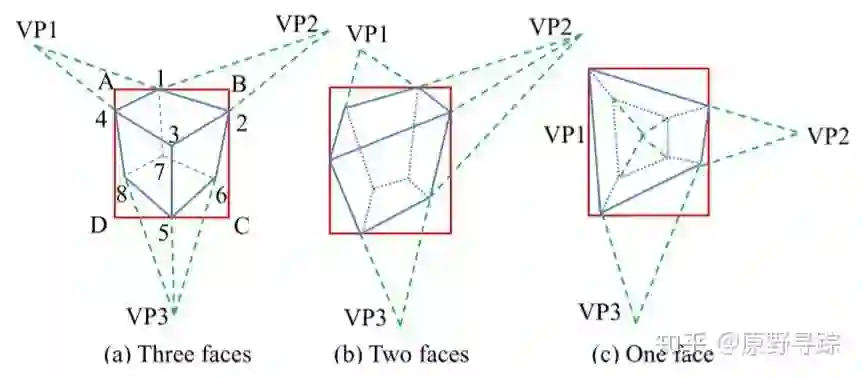
图中只要已知VP和其中一个端点,其他端点都能被算出来。图:比如当已知VP,图a)中给定1点,则2、4点可以通过线相交确定。
3) Get 3D box pose from 2D corners
得到了2D平面内的立方体顶点后,我们要估计其三维位姿。将物体分成两类。
任意位姿物体: 使用PnP solver来求解通常的立体3D位姿和大小,由于单目尺度不确定性,我们需要确定一个尺度因子。数学上来说,立体的八个3D顶点在物体坐标系下是可描述的: 


因此每个点可以贡献两个约束,4个点即可估计9DOF的pose,除了scale.
地面物体: 地面物体的roll/pitch都是0. 可以大大简化上述计算。我们不再需要用复杂的PnP Solver去求解,而是可以直接反向投影地面的顶点到三维地平面上,然后计算其他垂直的顶点。比如上述在三维地平面上的顶点5,可以表达为 [n,m] ( 相机帧里的向量和距离 ), 相对应的三维顶点 


该公式应该是空间直线与平面交点的表示公式,在 MVG 书里或许有。
更详细地投影过程在论文27中描述。尺度由相机高度决定。
4) Sample VP and Summary
由于VP通过物体旋转矩阵R决定。通过深度网络,可以直接预测VP。我们手动sample它们,并且根据评分排序它们。( 这部分到底是如何生成的?意思是否是通过神经网络预测物体的旋转矩阵R来预测VP?)
这里有一点提醒:在本文的实验中,作者仅仅考虑了那些位于地面的物体.! 包括KITTI中的车辆也满足这个假设.
其实仔细一想,正常情况哪个物体不在地面上呢?
B. Proposal scoring
示意获取最佳的三维立方体假设。

在图中,左图先提取了一些直线,右图分别是根据不同的直线生成的立体矩形假设,左上角是最佳的假设。每个不同假设可以得到不同的代价函数值。由下式计算:

其中 
1) Distance error 
2D立体边界应该与真实图像的边界匹配。通过Canny边缘检测,并生成 DT变换,对于每个可见的立体边,均匀sample 10个点,并综合计算所有距离值,然后除以2d矩形的对角线长度。
2) Angle alignment error 
距离误差与false positive的边很敏感,比如物体表面的纹理。因此,我们也检测长线条段(用LSD检测),然后测量它们的角度是否跟VP点匹配。这些直线首先与3个VP点之一关联,基于点-线支撑关系。对于每个VP,可以找到最远的两条线段,它们有最小和最大的倾角。

这里的含义应该是这两条线的交点应该是消影点VP. 那么关键在于为何点-线支撑关系能找到这样的两条最远线段呢. 参考文献给的[11]
3) Shape error

前两个的误差可以在2D图像平面内计算。但是,相似的2D立体端点可能生成完全不一样的3D立方体。我们添加一个误差来惩罚有巨大倾斜( 长宽比 ) 的比率。也可以添加更严格的先验,比如某些特殊种类物体的固定长宽值或比例。

IV. Object SLAM
我们延伸单图像三维物体检测到多物体SLAM,来联合优化物体位姿和相机位姿。系统基于ORBSLAM2搭建,包含前端相机追踪和后端BA。
我们主要的挑战是完善BA来联合物体、点和相机位姿,本部分将详细介绍。其他SLAM应用细节可以见VI-B, 静态物体在本部分介绍,动态物体将在下一节强调。
A. Bundle Adjustment Formulation
先放出完整的BA公式:
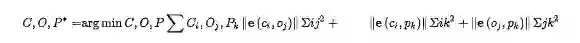
分别代表相机-物体,相机-点,物体-点的约束。
B. Measurement Errors
1) 相机-物体测量
物体和相机之间的测量误差有两种:
a ) 3D测量: 第一种是在3D物体检测是准确的时候使用的3D测量,比如使用RGBD相机时。检测的物体位姿,作为物体在当前相机帧的测量。为了计算测量误差,我们转换路标物体到相机帧,然后比较测量误差:

其中 log 将 SE3的误差映射到 6DOF的切向量空间,因而 
注意这里在没有先验时有歧义,无法分清前向和后向。因而在优化时要沿着高度方向旋转0 +-90 180度来获得最小误差。
b) 2D测量: 对于2d测量,我们将立方体路标投影到图像平面来获得2D的bbox,然后与检测的bbox之间比较。简单来说,就是将8个顶点投影到平面内,寻找最小和最大的投影像素x,y坐标来建立一个矩形:



c和s分别是矩形框的中心和边长。定义两个矩形框之间的误差为:

即直接让4D参数相减。这个测量比起上述的3D测量不确定性更小,因为一般2D检测更加准确。但不同的三维实体也可能有相同的2D投影。
2)物体-点测量
若点P属于物体,则应该在3D物体内部。我们首先将点转换到立体坐标系,然后与立方体的大小比较来获得三维误差:

使用max是鼓励点在立方体内部而非正好在表面。
3) 相机-点测量
我们在基于特征的SLAM中使用标准3D点重投影误差。不多赘述。
C. Data association
使用帧间的点跟踪来跟踪检测框。考虑哪些检测框内离中心在10像素以内的点。哪些匹配点最多,则关联谁。同时,对于匹配上的点过少的框( 使用对极几何搜索),它们可以认为是动态物体而去除掉!!
V. DYNAMIC SLAM
下面将同时估计相机位姿和动态物体的轨迹。基于几个基本假设:
刚体假设: 即物体上的点不会运动。
运动假设: 如速度模型; 对于车辆还有非完整轮式模型(nonholonomic wheel model),即限制侧面滑动.
动态物体跟踪是一个大的话题。在这里简单提到,其核心仍然是追踪动态的点,只是将点聚集一组,彼此之间增加速度约束。相机位姿也可以被动态元素约束。
1) 物体运动模型
使用 nonholonomic wheel model.

2) Dynamic point observation
动态点与关联的物体绑定,因而首先被变换到世界系,然后投影到图像平面。

C. Dynamic data association
由于匹配动态物体很麻烦,所以静态物体的关联方式不适用。典型方法是预测其投影位置,然后在附近搜索。但是对于单目动态场景,准确预测物体运动很难,对极几何也不准。特征点直接用2D KLT 稀疏光流算法来跟踪,不需要3D点位置。像素跟踪后,动态特征的3D位置通过考虑物体运动完成三角化。
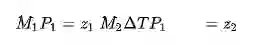
这是标准的两视图三角化问题.
KLT跟踪在像素位移太大时容易失败。因此我们直接使用视觉物体跟踪算法[40],上一帧的检测框将被跟踪,并在这一帧预测位置。
VI. IMPLEMENTATIONS
A. Object detetion
使用 YOLO detector在室内,概率阈值0.25;使用MS-CNN在室外KITTI数据集,概率阈值0.5.它们在GPU上实时。
关于误差函数中各部分权重的调节,使用手动调节。因为物体检测的协方差不好测定。这里也是一个futrue work.
详细的实验不赘述,大家可以自行看论文。
一些有价值参考文献
知乎编辑器解析不了Markdown表格,我截图在此.


最后
目前来看,物体级的SLAM两个方向比较明显,一个是CubeSLAM为代表的用立方体描述;另一条线是 QuadricSLAM等代表的用椭球体(特殊双曲面)描述。目前来看后者的阵容更强大,还有Towards semantic SLAM等文章在做,而且基于多视图几何那本书里的理论,有扎实的几何基础。
立方体描述在理论上并没有自成一派,研究者目前似乎仅有CMU RI的这位华人作者,当然他本身也很强,前面还有pop-up slam做面的支撑。
两条线有主要区别在于,立方体的slam是基于单目的,而椭球体基于RGBD相机,且作者在最后表示我们的future work是探索一下只用单目(哈哈哈)。毕竟单目就实现物体级slam谁不爱呢。
总之,语义slam中,作为很重要的语义元素的物体,在地图中的几何表达到底是立方体还是双曲面呢,或许解是二者之一,也可能二者都不是最好的解。只能让时间给我们答案了。
接下来有时间我会再写一下双曲面的解析。
CVer-SLAM交流群
扫码添加CVer助手,可申请加入CVer-SLAM群。一定要备注:研究方向+地点+学校/公司+昵称(如SLAM+上海+上交+卡卡)

▲长按加群
这么硬的论文分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!




