NeurIPS'22 Spotlight|华为诺亚GhostNetV2出炉:长距离注意力机制增强廉价操作

极市导读
本文提出了一种对硬件友好的 DFC 注意力机制,并借助它和 GhostNet 模型提出了一种针对端侧设备的GhostNetV2 架构。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 GhostNetV2:长距离注意力机制增强廉价操作
(来自北京华为诺亚方舟实验室)
1.1 GhostNetV2 论文解读
1.1.1 GhostNet 回顾和本文动机
1.1.2 重新思考 Attention 对模型架构的影响
1.1.3 用于移动端架构的解耦全连接注意力机制 DFC Attention
1.1.4 借助 DFC 注意力机制增强 Ghost 模块
1.1.5 特征下采样
1.1.6 实验结果
1 GhostNetV2:长距离注意力机制增强廉价操作
论文名称:
GhostNetV2: Enhance Cheap Operation with Long-Range Attention (NeurIPS 2022 Spotlight)
论文地址 GhostNetV2:
https://openreview.net/pdf/6db544c65bbd0fa7d7349508454a433c112470e2.pdf
1.1.1 GhostNet 回顾和本文动机
GhostNet 是一种轻量级卷积神经网络,是专门为移动设备上的应用而设计的。其主要构件是 Ghost 模块,一种新颖的即插即用模块。Ghost 模块设计的初衷是使用更少的参数来生成更多特征图 (generate more features by using fewer parameters)。 我们知道,深度神经网络的每个卷积层都有一定数量的输出特征图。给定输入特征 分别是特征图的高度,宽度和通道数),Ghost 模块将输出通道分成了两个部分 (一般是对半分):
第一部分是常规的卷积,这部分就是正常的实现,没有任何区别。唯一不同的是输出特征图的数量将会严格控制,因为不能让计算量太大:

式中, 代表卷积操作。 是 point-wise 卷积, 是部分输出特征。
第二部分是廉价操作 (cheap operation),目的是得到另外一些特征图,只是不再采用常规的卷积进行实现,而是通过简单的线性变换 (Linear Transformation) 来生成,最后把两个部分的结果 concat 在一起得到最终的输出:
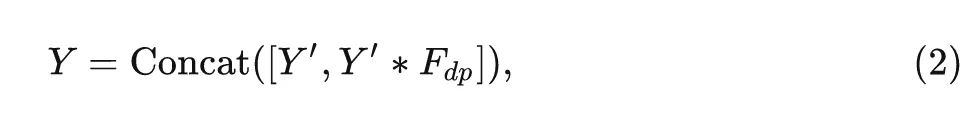
式中, 是 depth-wise 卷积, 是最终的输出特征。
按照这样的两个步骤实现的卷积模块,就称之为 Ghost 模块 (Ghost module)。与普通卷积模块相比,在同样的输入和输出特征图数量的情况下,Ghost 模块所需要的参数量 (Param) 和计算量 (MACs) 都得到了降低。
一个 GhostNet Block 通常会堆叠两个 Ghost 模块,类似于 MobileNetV2 的[1]Inverted bottleneck 的设计思路,第一个 Ghost 模块用来增加输出 channel 数,第一个 Ghost 模块再把输出 channel 数减小回原来的值,使之匹配 shortcut path。更详细设计细节可以参考原论文:
GhostNet:适用于 CPU 和 ARM 端的 GhostNet (CVPR 2020 Oral)
论文地址:https://arxiv.org/pdf/1911.11907.pdf
G-GhostNet:适用于 GPU 和 NPU 端的 GhostNet (IJCV 2022)
论文地址:https://arxiv.org/pdf/2201.03297.pdf
Ghost 模块的局限性
尽管 Ghost 模块可以大幅度地减少计算代价,但是其特征的表征能力也因为 "卷积操作只能建模一个窗口内的局部信息" 而被削弱了。在 GhostNet 中,一半的特征的空间信息被廉价操作 (3×3 Depth-wise Convolution) 所捕获,其余的特征只是由 1×1 的 Point-wise 卷积得到的,与其他像素没有任何信息上的交流。捕捉空间信息的能力很弱,这可能会妨碍性能的进一步提高。本文介绍的工作 GhostNetV2 是 GhostNet 的增强版本,被 NeurIPS 2022 接收为 Spotlight。
1.1.2 重新思考 Attention 对模型架构的影响
Self-attention 的优点是长距离建模的能力,但是计算复杂度与输入的分辨率大小呈二次方增长的关系,这对于高分辨率的图片而言是非常不友好的。而一些检测和分割任务都需要高分辨率的输入,使得 Self-attention 无法扩展。
针对这个问题,一种常见的做法是把图片分成一系列的不重叠的 windows,在每个 window 内部,代表性的工作有 Swin[2] 。或者把图片分成一系列的不重叠的 patches,在 patches 之间做 Self-attention,代表性的工作有 MobileViT[3]。
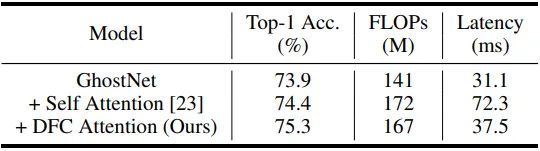
无论是上述哪一种方法,都有很多对二维特征图的 reshape 和 transpose 操作。其理论计算复杂度可以忽略不计。在一个大模型中 (例如有几十亿 FLOPs 的 Swin-B ) ,这些操作只占总推理时间的很小一部分。但是对于对于轻量级的模型,它们的部署延迟就不再能被忽视了。如下图1所示是在 Huawei P30 (Kirin 980 CPU) 加上 TFLite tool 的实测结果。作者使用 MobileViT 中的 Self-attention 在 GhostNet 上做了实验,输入是 224×224 大小的 ImageNet 图片。从结果中可以看到,attention 模块明明只占 20% 左右的理论计算复杂度,但是在移动端设备上却需要2倍以上的推理时间。理论计算复杂度和实际的推理速度延时的巨大差异表明,有必要设计一个对硬件友好的注意力机制,以便在移动设备上快速实现。
1.1.3 用于移动端架构的解耦全连接注意力机制 DFC Attention
这里作者阐述如何设计一种针对端侧架构的 attention,一个预期的注意力机制应该具有以下特性:
-
长距离: 注意力机制应该遵循原始的 Self-attention,具有捕捉长程空间信息的能力,以增强其表征能力。在一些轻量级的 CNN (例如 MobileNet,GhostNet) 中通常采用小卷积滤波器以节省计算成本,这就导致它们这样的能力偏弱。
-
高效率部署: 注意力模块应该高效,以避免拉低整体模型的推理速度。FLOPs 很高的,或者对于硬件不友好的操作的不可取。
-
简单: 为了保持模型在不同任务上的通用性,注意力模块应该是简单的,没有什么精致的设计。
虽然原始的 Self-attention 可以很好地模拟长程相关性, 但它却不满足高效率部署这一点, 因为其 计算复杂度与图片分辨率呈二次方的关系。本文作者因此希望采用更简单, 更容易实现的具有固定权重的全连接层 (FC) 生成具有全局感受野的注意力图。 给定输入特征 , 它可以被视为是 个 token, 即 。
一种使用 FC 层实现注意力图的方式是:
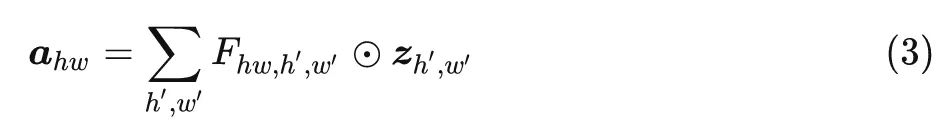
式中, 代表 element-wise 的乘法, 是可学习权重, 是得到的注意力图。
上式可以通过将所有 token 与可学习的权重结合在一起来捕捉全局信息, 为什么呢?
因为在计算每个位置注意力输出 的过程中, 都融合了所有位置的信息 (在 中体现)。
这个计算过程比 Self-attention 简单得多, 但是它的计算复杂度仍然与图片分辨率呈二次方的关系 。这在实际的应用场景中是不可接受的, 尤其是当输入图像具有高分辨率的时候。比如 GhostNet 第4层的特征图大小是 3136 (56×56 的 token), 这导致非常高的计算复杂度。
而事实上,CNN 中的特征图通常是低秩的,因此其实没有必要密集地连接不同空间位置的所有输入和输出 tokens。作者认为,CNN 特征是 2D 的,这个 2D 的形状自然地提供了减少 FC 层计算量的一个视角,即分解式3。具体而言,作者将式3分解成2个 FC 层,并分别沿水平和垂直方向聚集特征。它可以表述为:
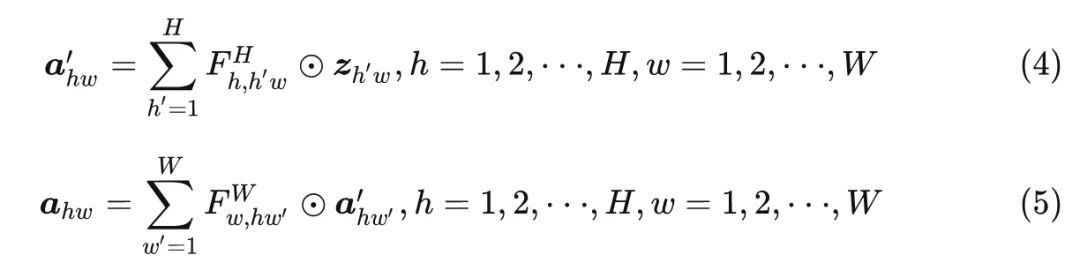
式中, 和 是权重。输入是原始特征 ,式4和5顺序作用在特征上面,分别捕获沿着两个方向的长程相关性。作者将这种注意力机制称为解耦全连接注意力机制 (decoupled fully connected, DFC) 。如下图2所示,

由于水平和垂直变换的解耦,注意力模块的计算复杂度可以降低到 。
在原始的 Self-attention 中,每个 patch 的注意力值的计算涉及所有 patch。而在 DFC 中,每个 patch 的注意力值的计算直接与它水平或垂直位置的 patch 有关,而这些水平或垂直位置的 patch 的计算又与它们水平或垂直位置的 patch 有关。因此每个 patch 的注意力值的计算也一样涉及到所有 patch。
上式4和5表示注意力的一般公式,分别沿水平和垂直方向聚集不同位置的像素。这个过程还是借助 FC 实现的。通过共享一部分权重,其实也可以方便的使用卷积来实现,这也省去了影响实际推理速度,以及很耗时的张量 reshape 和 transpose 操作。为了处理具有不同分辨率的输入图像,滤波器的大小可以与特征图的大小解耦,即使用两个 Kernel Size 为 和 的 depth-wise 卷积分别作用在特征上面。
当用卷积实现时,DFC 注意力的理论复杂度为 。这种策略得到了 TFLite 和ONNX 等工具的良好支持,可以在移动设备上进行快速推理。
1.1.4 借助 DFC 注意力机制增强 Ghost 模块
借助上节介绍的 DFC attention 实现的 GhostNet 称之为 GhostNetV2。DFC attention 是为了配合 Ghost 模块使用, 以捕捉长距离空间位置的依赖关系。具体而言, 对于输入特征 , 它被送到2个分支里面, 一个是 Ghost 分支, 得到输出特征 , 一个是 DFC 分支, 得到注意力矩阵 , 在典型的 Self-attention 中, 常用到 linear transformation。所以作者在这里也使用 卷积, 将模块的输入 转化成 DFC 的输入 。
最终输出是将两个分支的结果进行点乘, 即:
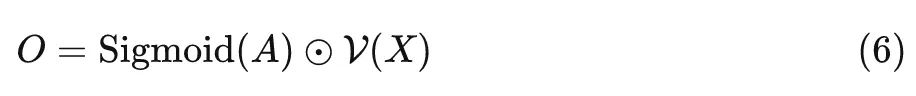
式中, Sigmoid 的目的是将注意力矩阵的输出结果标准化到 之间, 信息的流动过程如下图3所示。
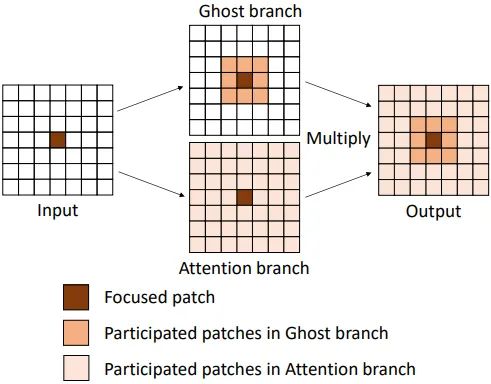
1.1.5 特征下采样
由于 Ghost 模块是一个非常高效的操作,相比而言,DFC attention 就没有那么简洁,直接将 DFC attention 与之并行会引入额外的计算成本。因此作者通过在水平和垂直方向上向下取样来减小特征的大小,这样 DFC 注意力中的所有操作都可以在较小的特征上进行。默认情况下,特征的宽度和高度都被缩放为原始长度的一半,这减少了DFC 注意力的 75% 的 FLOPs。然后再把得到的特征图通过上采样到原始的大小,以匹配 Ghost 分支特征的分辨率大小。作者使用 average pooling 和 bilinear interpolation 进行下采样和上采样。注意到直接实现 Sigmoid (或hard sigmoid) 函数会产生较长的延迟,所以作者在下采样的特征上部署了 sigmoid 函数,以增加实际的推理速度。尽管这样做以后,最终的注意力矩阵的值不会被严格限制在 (0,1) 的范围内,但是实验发现,对最终性能的影响是可以忽略不计的。
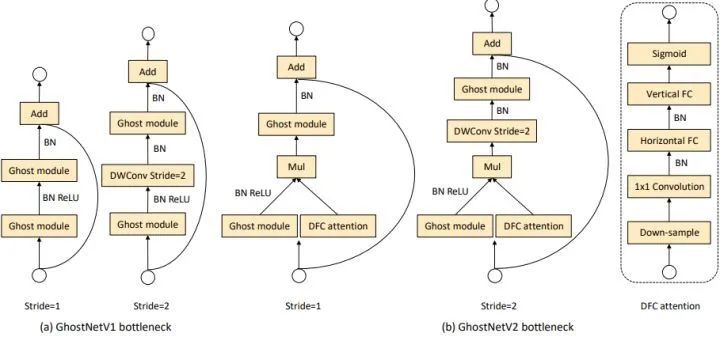
GhostNet 采用 Inverted bottleneck 设计,就是使用两个 Ghost 模块,其特征的维度先上升后下降。这种设计方式自然地解耦了模型的 "expressiveness" 和 "capacity"。前者由扩展的特征来衡量,而后者则由一个块的输入/输出来反映。原始的 GhostNet 通过廉价操作得到部分特征,但是这损害了模型的 "expressiveness" 和 "capacity"。而 DFC attention 与第一个 Ghost 模块并行,增强了模型的表达能力。
如下图4所示是 GhostV2 bottleneck 的示意图,DFC 注意力分支与第一个 Ghost 模块并行,以增强扩展的特征。然后,增强后的特征被输入到第二个 Ghost 模块,以产生输出特征。它捕捉到了不同空间位置的像素之间的长距离依赖性,增强了模型的表达能力。
1.1.6 实验结果
ImageNet 实验结果
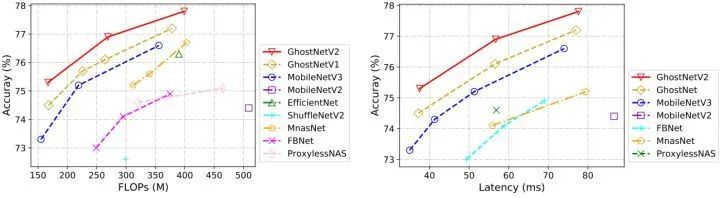
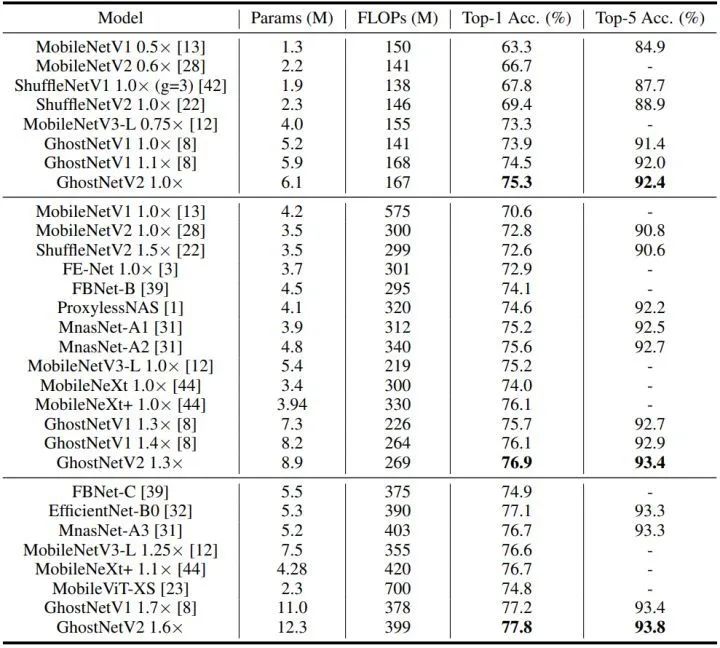
如上图5和图6所示是 ImageNet 实验结果,延时数据是使用 TFLite 工具在 Huawei P30 (Kirin 980 CPU) 上实测得到。通过结合 CNN 和 Transformer 得到的 MobileViT 是最近提出的一个新的骨干。与 MobileViT 相比,GhostNetV2 以较低的计算成本实现了较高的性能。比如 GhostNetV2 仅用 167MFLOPs 就达到了 75.3% 的 top-1准确率,这大大超过了 GhostNet V1 (74.5%),而二者的计算成本相近。
考虑到轻量级模型是为移动端应用而设计的,作者使用 TFLite 工具实测了不同模型在移动电话上的推理延迟。DFC 注意力机制的部署效率较高,使得 GhostNetV2 也在准确性和实际速度之间实现了良好的平衡。比如,在相似的推理延迟下 (如37毫秒),GhostNetV2 达到了 75.3% 的准确率。
COCO 目标检测
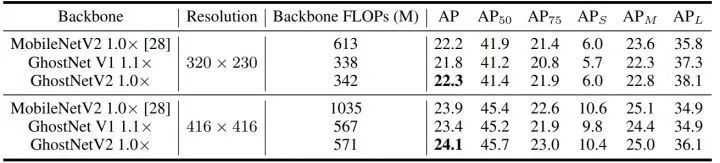
如下图7所示是以 GhostNetV2,GhostNetV1 和 MobileNetV2 为 Backbone,加上 YOLO V3 检测头的 COCO 目标检测实验结果。在不同的输入分辨率下,GhostNetV2 都展示出了比 GhostNetV1 更好的性能。比如,在相似的计算成本下 (320×320 输入分辨率) 的 GhostNetV2 实现了 22.3% 的 mAP,也就是说,长距离建模对于下游任务而言也是至关重要的。本文所提出的 DFC 注意力可以有效地赋予一个大的感受野给 Ghost 模块,使之成为一个更强大、更高效的模块。
ADE20K 语义分割
如下图8所示是以 MobileNetV1 和 MobileNetV2 为 Backbone,加上 DeepLabV3 分割头的 ADE20K 语义分割实验结果。在语义任务中,GhostNetV2 也取得了明显高于 GhostNetV1 的性能。

与其他模型的适配性
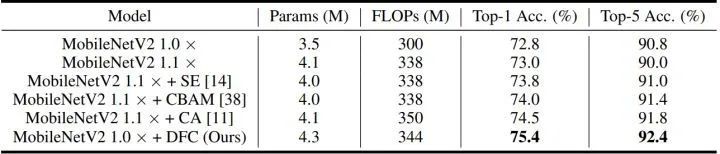
如下图9所示为 DFC 注意力机制与其他模型的适配性,是 obileNetV2 使用不同注意力模块的结果。可以看到 DFC 注意力也可以被嵌入到其他架构中以提高其性能。SE 和 CBAM 是两个注意力模块,CA 是最近提出的一种 SOTA 方法。本文所提出的 DFC 注意力取得了比这些现有方法更高的性能。例
DFC attention 卷积核大小的影响
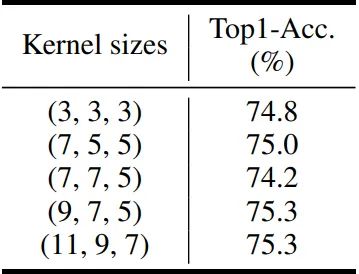
作者将 GhostNetV2 的结构按特征的大小分成3个阶段,并在不同的核大小下应用 DFC 注意。如下图10所示,Kernel Size 大小为 1×3 和 3×1 时不能很好地捕捉长距离的依赖性,使得性能最差。增加内核大小以捕捉长距离信息可以显著提高性能。
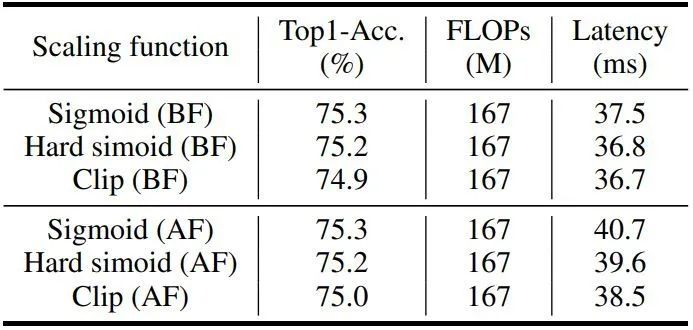
Scaling 函数的影响
对于一个注意力模块而言,通常的做法是将特征矩阵的值的范围调整到 (0,1),以稳定训练过程。虽然理论上的复杂性可以忽略不计,但这些元素的操作仍然会产生额外的延迟。如下图11所示为 Scaling 函数对最终性能和延迟的影响。尽管 Sigmoid 和 Hard sigmoid 函数带来了明显的性能改善,但在大的特征图上直接实现它们会产生很长的延迟。可以看到,在上采样之前实现它们的效率要高得多,但结果是类似的精度。所以,默认情况下使用 Sigmoid 函数,并把它放在上采样操作之前。
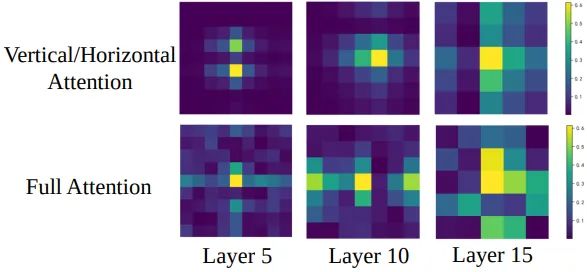
Full attention 和 Decoupled attention 可视化结果
如下图12所示是 Full attention 和 Decoupled attention 的可视化结果。在低层,Decoupled attention 显示出一些十字形的图案,表明来自垂直/水平线的斑块参与更多。随着深度的增加,注意力矩阵的模式扩散,变得与 Full attention 更相似。
总结
本文提出了一种对硬件友好的 DFC 注意力机制,并借助它和 GhostNet 模型提出了一种针对端侧设备的GhostNetV2 架构。DFC 注意力可以捕捉到远距离空间位置的像素之间的依赖性,这大大增强了轻量化模型的表达能力。DFC 注意力机制将 FC 层分解为水平 FC 和垂直 FC,分别沿两个方向具有较大的感受野。配备了这种计算效率高、部署简单的模块之后呢,GhostNetV2 就可以在准确性和速度之间实现更好的权衡。作者 ImageNet 和下游任务上进行的大量实验验证了 GhostNetV2 的优越性。
参考
-
^Mobilenetv2: Inverted residuals and linear bottlenecks -
^Swin transformer: Hierarchical vision transformer using shifted windows -
^Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer
公众号后台回复“速查表”获取
21张速查表(神经网络、线性代数、可视化等)打包下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选




