朝着卷积进一步迈进!PAIR等开源NAT:新分层注意力Transformer ,超越ConvNeXt

极市导读
本文提出了Neighborhood Attention Transformer,一种由Neighborhood Attention组成的高效、准确、可扩展的新型分层Transformer。实验表明,NAT的性能优于Swin Transformer和ConvNeXt,NAT-Tiny模型在ImageNet上仅用4.3 GFLOPs和28M参数就能达到83.2%的top-1精度。>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文:https://arxiv.org/abs/2204.07143
代码:https://github.com/SHI-Labs/Neighborhood-Attention-Transformer
简单介绍

在我看来,本文的核心在于将Swin中的局部Attention操作进行朝着卷积的方向更进一步扩展。作者们更强调本文的设计是从卷积的角度获得启发的。
本文的核心内容主要集中在三个方面:
-
提出了一个neighborhood attention操作。顾名思义,其以query对应的位置为中心来设定局部窗口,从而提取key和value进行计算。这是一种概念上更加简单、灵活和自然的的注意力机制。 -
基于提出的neighborhood attention构建了一个完整的vision transformer模型。模型延续始终分层的金字塔结构,每一层跟着一个下采样操作来缩减一半的尺寸。不同于现有的Swin等模型中采用的等效于非重叠卷积的操作,这里使用小尺寸且带重叠的卷积操作来进行特征嵌入和下采样。同时对于Stem阶段,同样采用了重叠卷积的操作。这些设定也带来了良好的效果,虽然会引入更多的计算成本和参数量,但是通过合理配置模型的结构,仍然可以获得足够优异的表现。 -
分类、检测、分割上都获得了良好的表现,超过了现有的众多方法,包括Swin和ConvNeXt等。对于28M参数这个近似于ResNet50的量级,在ImageNet1K上都可以达到83.2%的Top1的分类表现,确实效果很好。
核心操作

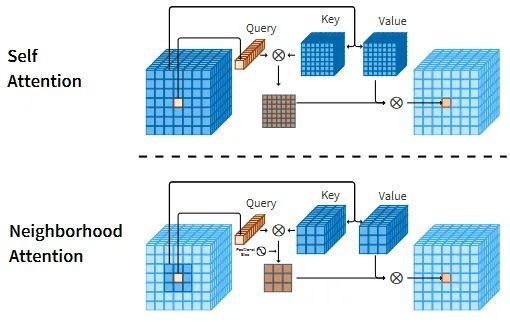
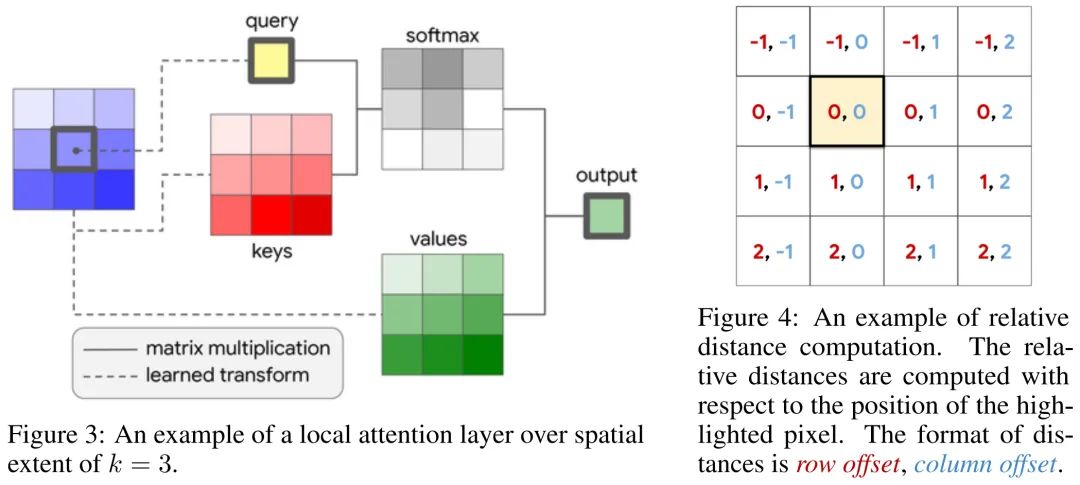
这个插图展示了自注意力操作和本文提出的NA之间的运算差异。
-
自注意力操作允许每个token去和全局所有token之间进行交互; -
NA中会强制要求k,v的选择来自于以q为中心的邻域,即这里同时强调了两点, 一个是局部区域,一个是以q为中心。
同时这里也体现出了和Swin这类的直接将原始的全局注意力机制约束到局部窗口内的局部注意力形式上的差异。
-
二者相同之处在于对于每个q都是和一个局部的窗口内的k和v来计算attention计算,这也因此使得二者之间的理论上的计算量是一致的,都是有着线性的计算复杂度和内存使用。 -
但是,本文的NA却有着一点额外的优势,即直接将注意力操作范围限制到了每个像素的邻域,而这些领域的计算天然地实现了一种类似于卷积那样的“滑动窗口”式的带重叠区域的交互,而不需要再像Swin那样需要额外借助于偏移操作来引入窗口的交互。同时更实际的一点是,也不再限制输入必须要能被窗口大小整除了。
也就是说,从原本局部Attention操作的窗口内部计算标准Attention操作改为了特定点上的q和其局部范围内的kv计算Attention,即原本的固定等分的窗口变成了以q为中心的滑动窗口。
通过这样的形式,对Attention操作引入更多的局部偏置属性,从而针对视觉任务获得更好的表现。
对于提出的Neighborhood Attention而言,如果邻域窗口超出或者正好等于特征图大小,那么就可以等效为标准的Self Attention了。
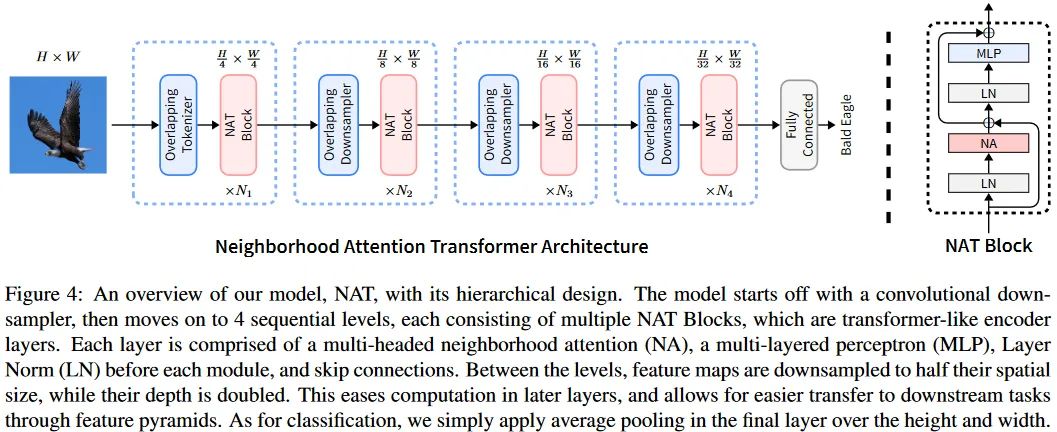
NAT中,在下采样特征图和Stem阶段都使用的是重叠的跨步卷积操作。这不同于Swin。虽然可能引入更多的计算和参数,但是通过模型整体的配置,是可以得到更少计算量的结构的。

从公式来看,这里也对Attention Map上引入了局部的相对位置嵌入。
计算量和存储占用分析
对于角落的像素,在NAT的设定中,此时的局部邻域不再以其为中心,而是选择同样以其为角落的等大的局部邻域。具体可见本文开头引自代码仓库的动图。
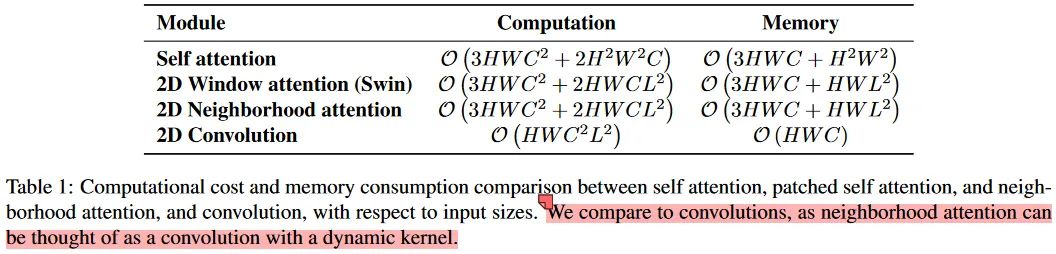
文章对比了标准卷积、窗口注意力、文章提出的NA,以及标准的自注意力的计算和内存占用。卷积本身在内存占用上有着明显的优势,而且与窗口大小无关。而在计算量上,卷积与通道数量和方形窗口边长都呈二次关系。通过仔细对比二者的公式可知,在常用的通道和窗口配置下(例如L=3,C>3时),提出的NA在计算量上是可以小于标准卷积操作的。只是会有更多的内存占用。
就理论计算量和内存使用而言,和Swin实际上是没有太大区别的,因为从更广的角度来看,都是每个q和一个局部窗口内的k和v计算。而在实际的运算中,对于Swin这样的非重叠窗口的划分方式,在特征图尺寸无法被窗口尺寸整除的时候,是需要进行padding操作的。而本文的NA中,因为不会padding,所以由此造成的无用计算却是可以避免的。所以有时会出现相较于Swin,NT具有更少的FLOPs。
具体实现
就具体实现而言,不考虑效率的情况下是可以使用PyTorch自带的unfold操作和replicated_pad搭配来实现。
但是这并不是很有效,因为其需要存储每个提取出来的窗口的数据,并且要在非常大的张量上执行两个独立的CUDA核的调用。另外,这种设计也不够灵活,并且会使得添加相对位置编码的时候非常复杂。
于是本文是通过自定义CUDA核函数进行优化。但是当前的性能仍然有待进一步优化。
实验结果
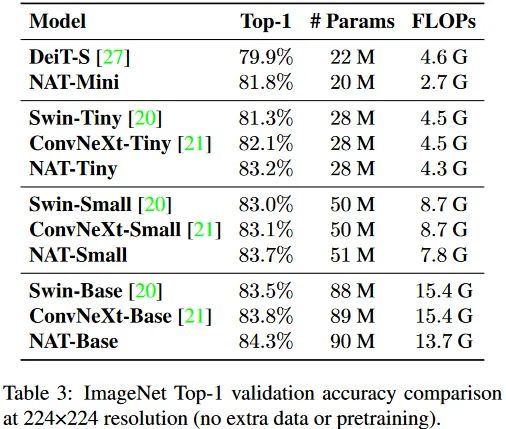
就性能而言,本文的效果确实不错,在28M这个近似于ResNet50的参数量级上已经实现了83.2的top1,确实比较强了。
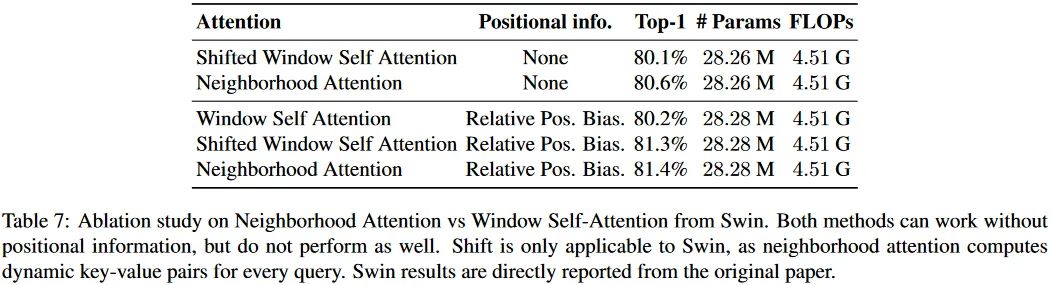
可以看到相对位置编码确实非常有用。
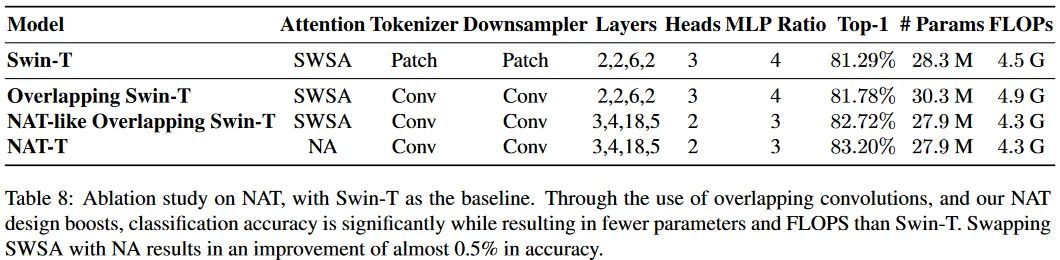
这里涉及到两个实验,可以看到Conv Tokenizer和Downsampler,以及提出的NA是更有效的。
-
注意力部分:将Swin的局部Attention改为本文提出的NA形式。 -
tokenizer和downsampler部分:This change only involves using two 3 × 3 convolutions with 2 × 2 strides, instead of one 4 × 4 convolution with 4 × 4 strides, along with changing the downsamplers from 2×2 convolutions with 2×2 strides to 3 × 3 convolutions with the same stride.

在可视化部分,作者们可视化了部分验证集数据的Salient Map。可以看到图中对于目标边缘的反应比较清晰。这可能是因为提出的NA良好的局部偏置特性以及卷积Tokenizer和Downsampler带来的。也就是说,够强的局部偏置带来的效果。
相似文章
文章提出的策略实际上和另一篇google在2019年的文章非常相似:Stand-Alone Self-Attention in Vision Models(https://arxiv.org/abs/1906.05909)。这类结构确实看起来非常自然,因为是在延续着卷积的思路,但是实现起来确实比较麻烦。不像卷积有着良好的基础框架的支持。
在问到与这篇工作的相似的时候,作者有如下回复,我大致翻译了下:(https://github.com/SHI-Labs/Neighborhood-Attention-Transformer/issues/1)。其中,主要着重于两点,一点是邻域定义方式的不同,另一点是应用角度的不同。
我们已经引用了SASA这篇文章作者同组的更靠近当下的另一篇文章HaloNet。
正如论文中所述,局部化注意力的想法并不新,就如同注意力并非是一个新的想法一样。Swin也在局部化注意力,其他的工作也在做类似的事情。但是不同点在于感受野的选择。
NA和SASA之间的一个关键的差异在于邻域的定义不同。 NA是基于每个像素去和其最近的邻域交互,而SASA则是仍然延续“same”形式的卷积,是基于每个像素仅和其周围的像素发生关联的形式。这两种定义形式在边缘部分是非常不同的,并且边缘会随着窗口大小而增长。(可以看论文的图6或者前面那个动图。)另外,不论是SASA或是HaloNet都没有开源,并且很难直接比较。而且在HaloNet的表1中,似乎暗示着SASA甚至有着和NA不同的计算复杂度和内存使用。因此可能有其他我们不知道的差异存在。 另一个大的差异是NA和SASA的应用形式不同。 SASA目的是替换显存模型中的空间卷积操作,像是具有较小的内核大小的 ResNets。而我们的想法是去使用具有大邻域的NA来构建有效的分层Transformer,其在图像分类和其他的下游视觉应用中工作的很好,类似于Swin做的那样。这就是为什么我们的相关部分没有关注 SASA 和 HaloNet 等工作的原因,因为虽然它们的注意力机制有相似之处,但论文的重点和应用却大不相同。我们的 NAT 直接与现有的最先进的分层模型(例如 Swin)竞争。
-
Vision Transformer:https://www.yuque.com/lart/architecture/nmxfgf#F9gus
原始文档:https://www.yuque.com/lart/papers/dgoe6a
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

Lart
知乎:人民艺术家
CSDN:有为少年
大连理工大学在读博士
研究领域:主要方向为图像分割,但多从事于二值图像分割的研究。也会关注其他领域,例如分类和检测等方向的发展。
作品精选





