华为轻量级神经网络架构GhostNet再升级,GPU上大显身手的G-GhostNet(IJCV22)

极市导读
本文围绕网络部署时面临的内存和资源问题,分享了如何从可视化和大量实验结果中得到Ghost特征的思想。作者设计出相比C-Ghost更适用于GPU等设备的G-Ghost,在实际延迟与性能之间取得了良好的权衡。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一、写在前面的话

二、导读
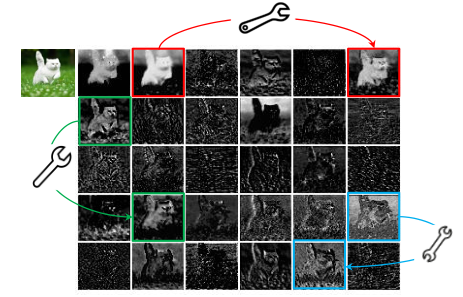
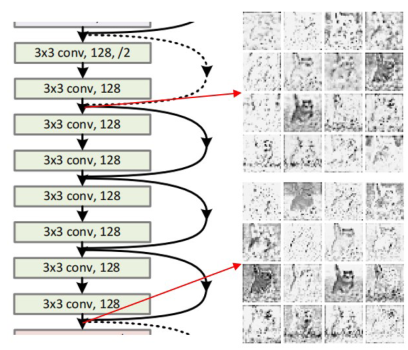
三、C-GhostNet回顾
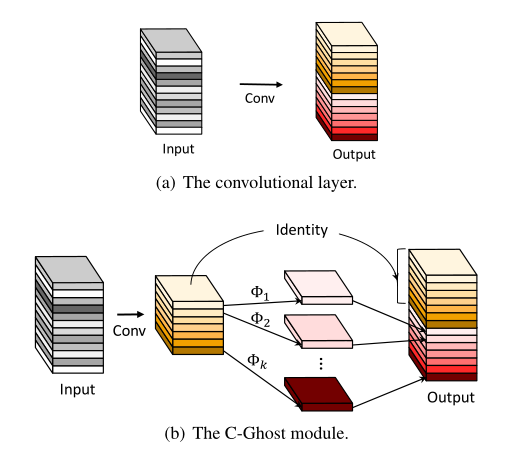
class GhostModule(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.out_channel = out_channel
init_channels = math.ceil(out_channel / ratio)
new_channels = init_channels*(ratio
-1)
# 生成内在特征图
self.primary_conv = nn.Sequential(
nn.Conv2d(in_channel, init_channels, kernel_size, stride, kernel_size//
2, ),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=
True)
if relu
else nn.Sequential(),
)
# 利用内在特征图生成Ghost特征
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size,
1, dw_size//
2, groups=init_channels),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=
True)
if relu
else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=
1)
return out[:,:self.out_channel,:,:]
四、G-GhostNet
Radosavovic等人引入激活度(所有卷积层的输出张量的大小)来衡量网络的复杂性,对于GPU的延迟来说,激活度比 FLOPs更为相关。
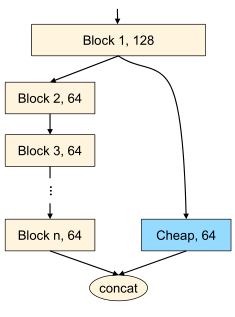
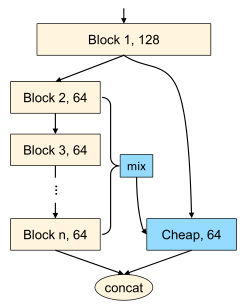
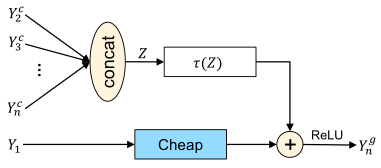
self.cheap = nn.Sequential(
nn.Conv2d(cheap_planes, cheap_planes,
kernel_size=
1, stride=
1, bias=
False),
nn.BatchNorm2d(cheap_planes),
# nn.ReLU(inplace=True),
)
五、性能对比
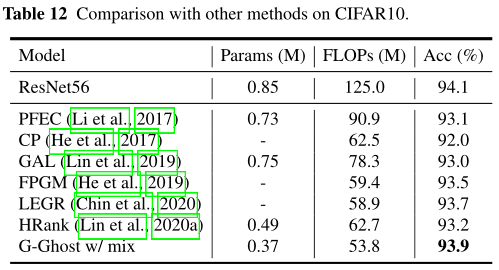
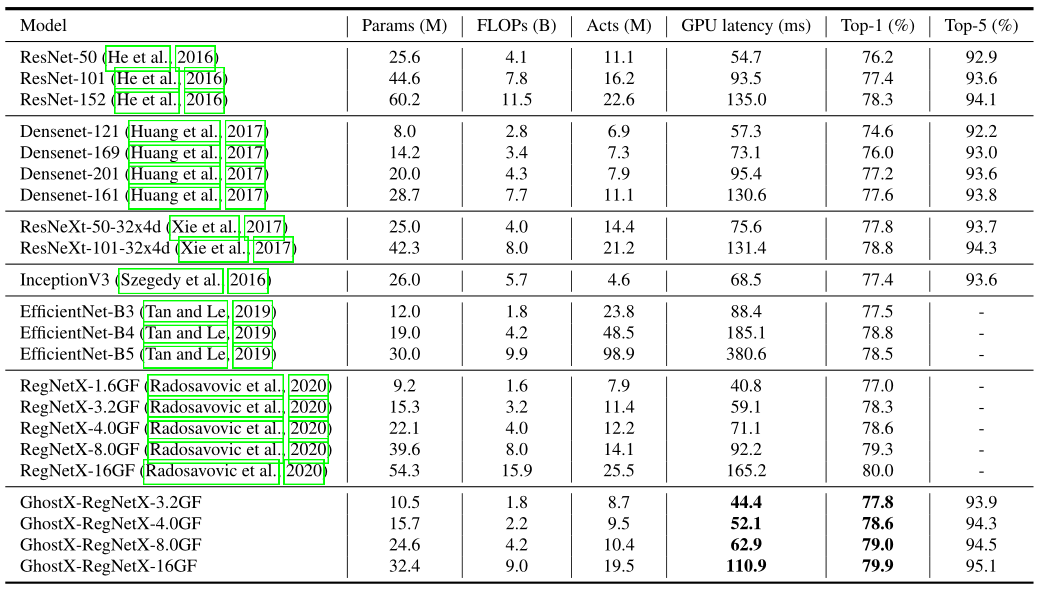
六、总结与思考
公众号后台回复“七夕”获取综述论文合集打包下载~

# 极市平台签约作者#

Ziyang Li
知乎:Ziyang Li
东电机器人专业在读,一个努力上进的CVer,一个普普通通的学生。
研究领域:先进传感技术、模式识别、深度学习、机器学习。
希望将路上的收获分享给同样前进的你们,共同进步,一起加油!
作品精选:
CVPR 2022 Oral|百度&中科院开源新的视觉Transformer:卷积与自注意力的完美结合
性能远超ConvNeXt?浅析谷歌提出的「三合一」transformer模型MaxViT+伪代码分析
ICPR 2022|3DUNet:卷积+胶囊强强联手,医学图像分割的新良方

“
点击阅读原文进入CV社区
收获更多技术干货
登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文