【泡泡一分钟】移动平台上的实时全增量场景理解
每天一分钟,带你读遍机器人顶级会议文章
标题:Real-Time Fully Incremental Scene Understanding on Mobile Platforms
作者:JohannaWald , Keisuke Tateno, J¨ urgen Sturm, Nassir Navab, and Federico Tombari
来源:IEEE Robotics and Automation Letters
编译:王丹
审核:颜青松,陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

我们提出了一种在线RGB-D的场景理解方法,用于移动设备上实时运行的室内场景。首先,我们在全局三维模型中,通过同时定位和地图构建来逐步重建场景,并通过融合从每个输入深度图像获得的片段来计算三维几何分割。我们将这种几何分割与语义标注相结合,得到语义图形式的语义分割。为了实现有效的语义分割,我们使用快速增量的三维描述符对全局模型中的片段进行编码,并使用随机测试来确定其语义标签。然后,融合连续帧的预测以获得跨时间的可信语义类。结果,总体方法达到接近最先进的三维场景理解方法的精度,同时效率更高,实现低功耗嵌入式系统的实时执行。
与现有技术相比,本文算法非常有效和可伸缩,因其计算是完全递增的,因此与低功耗、内存受限的设备兼容。
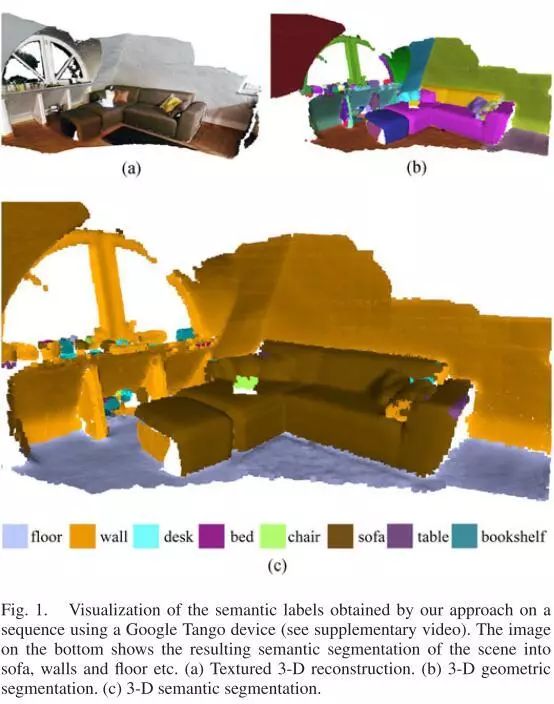
图1:使用Google Tango设备在序列上可视化通过我们的方法获得的语义标签。底部的图像显示了沙发、墙壁和地板等场景的语义分割结果。(a)纹理三维重建。(b)三维几何分割。(c)三维语义分割。
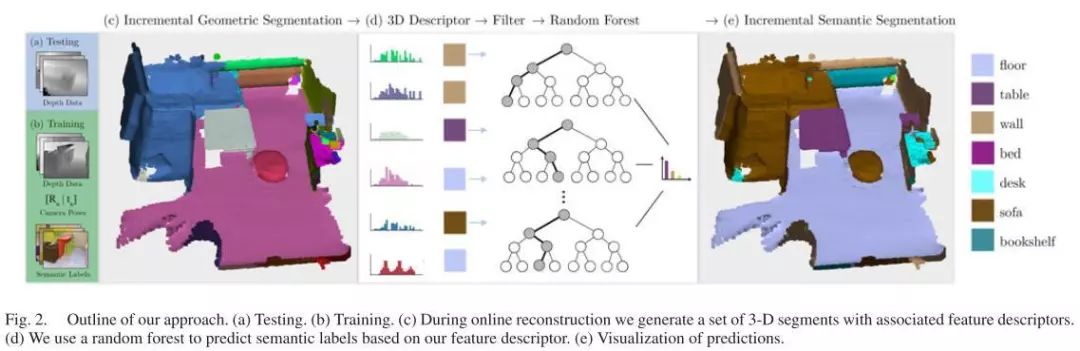
图3:本文方法概述:(a)测试(b)训练(c)在在线重建过程中,我们生成一组具有相关特征描述符的3D片段。(d)我们使用随机森林来预测基于特征描述符的语义标签。(e)预测的可视化。
这项工作的主要贡献是定义了3D点云的描述符,该描述符可以在新数据到达时增量地更新。证明了我们的描述符对于语义分类来说足够丰富,例如,可以预测一个片段是否对应于椅子、桌子或墙壁。特别是,我们在描述符上训练了一个随机森林来预测相应的片段的语义类别。通过将描述符和分类器与基于点的融合方法相结合,获得了用于全增量3D重建和场景理解的实时流水线。与现有的语义分割方法相比,本文提出的描述符循环以前的操作以每帧仅花费恒定的时间,而不管全局地图的当前大小,因此能够以每帧恒定的时间对3D片段进行编码。由于描述符只有在新点被集成时才需要更新,所以每帧的总计算时间仅取决于传感器特性,而与地图的大小无关。
本文在基准数据集ScanNet 上验证了框架的性能,表明它可以实现与某些最先进方法相当的准确性,同时显着提高效率和可扩展性 - 特别是,不需要 GPU并在移动设备上实时运行。结果见table 1。
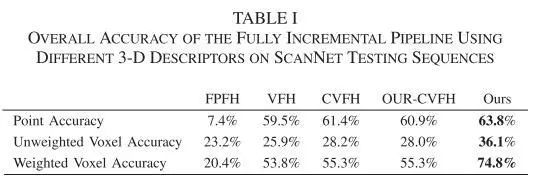
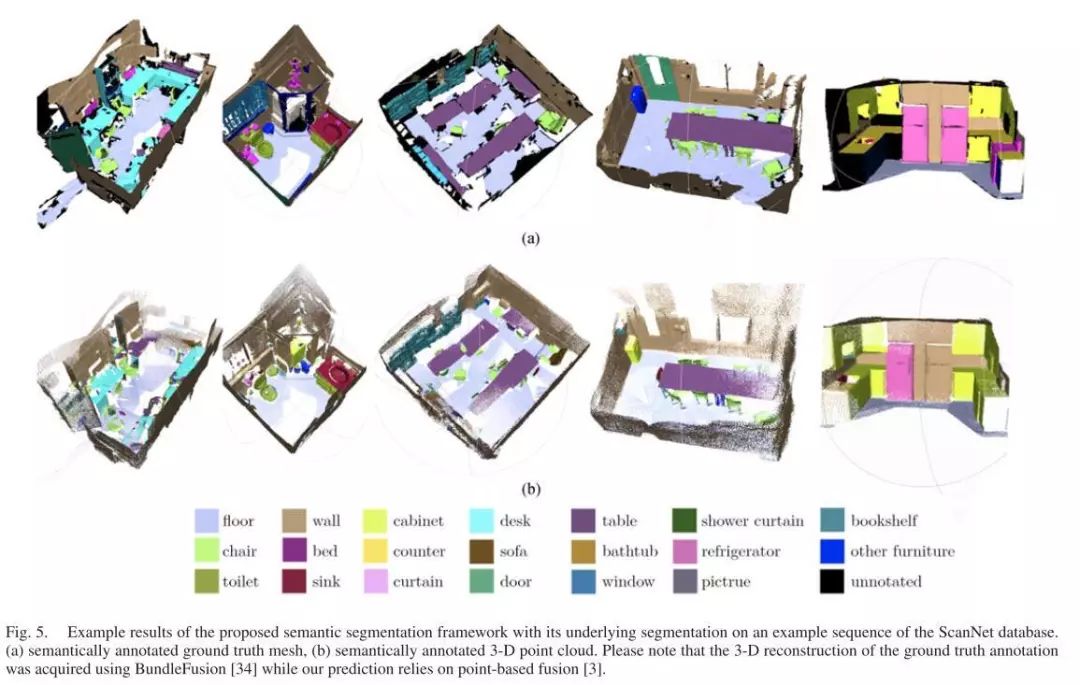
图5 在ScanNet数据集的一个示例序列上,所提出的语义分段框架及其底层分段的示例结果。(a)语义标注的地面实数网格,(b)语义标注的三维点云。
Table2 评估不同的描述符组成部分
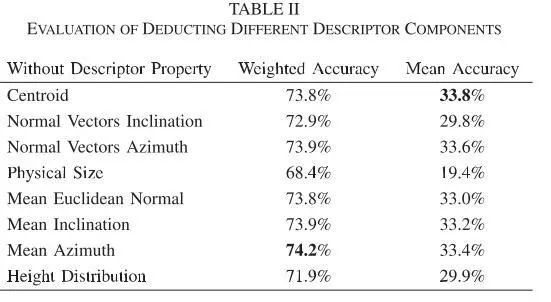
Table3 基于输入深度图不同分辨率的tango手机语义分类流水线的平均运行时间
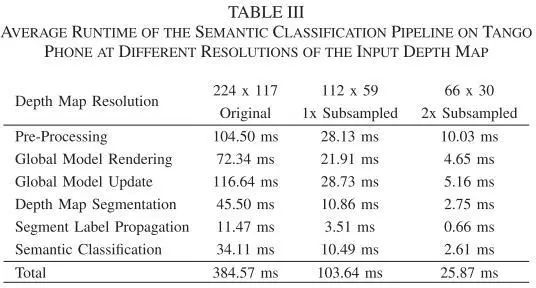
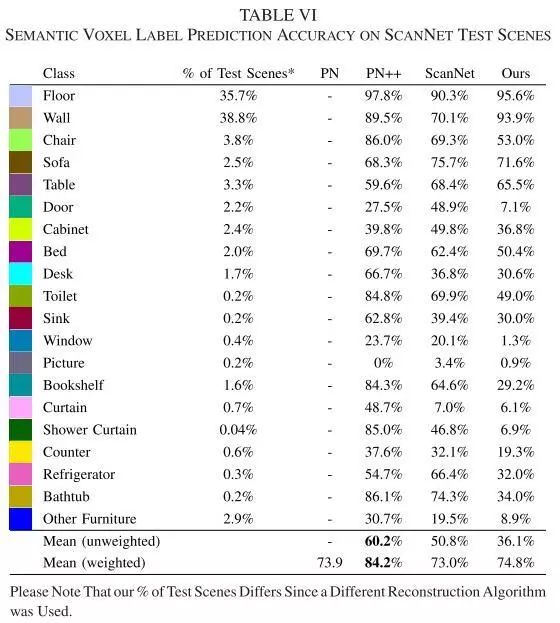
Table 6 扫描ScanNet场景语义体素标签预测精度

Abstract
We propose an online RGB-D based scene understanding method for indoor scenes running in real time on mobile devices. First, we incrementally reconstruct the scene via simultaneous localization and mapping and compute a three-dimensional (3D) geometric segmentation by fusing segments obtained from each input depth image in a global 3-D model. We combine this geometric segmentation with semantic annotations to obtain a semantic segmentation in form of a semantic map. To accomplish efficient semantic segmentation, we encode the segments in the global model with a fast incremental 3-D descriptor and use a random forest to determine its semantic label. The predictions from successive frames are then fused to obtain a confident semantic class across time. As a result, the overall method achieves an accuracy that gets close to the most state-of-the-art 3-D scene understanding methods while being much more efficient, enabling real-time execution on low-power embedded systems.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com