CVPR 2022 | 浙大提出Oriented RepPoints:旋转目标检测网络
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
作者:小海马 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/511356711
一般物体相比,空中目标通常是非轴对准的,具有杂乱的环境。与主流的包围盒方向回归方法不同,本文提出了一种有效的自适应点学习方法,该方法利用自适应点表示,能够捕捉任意方向实例的几何信息。为此,本文提出了三种定向转换函数,以便于分类和定位。此外,我们提出了一种有效的自适应点学习质量评估和样本分配方案,用于在训练过程中选择具有代表性的点样本,能够从相邻物体或背景噪声中捕获非轴对齐特征。在自适应学习中,引入空间约束来惩罚离群点。

Oriented RepPoints for Aerial Object Detection
论文:https://arxiv.org/abs/2105.11111
代码(已开源):
https://github.com/LiWentomng/OrientedRepPoints
1.1 Introduction

介绍:首先我们来看图1了解一下航空目标检测与传统的目标检测有什么不同;左图的传统的目标检测的数据,右图是航空目标检测的数据。很明显可以看出,1.传统的检测框是垂直的矩形框,而右图是斜着的带有方向的矩形框。2.航空图中的目标一般要比传统的目标更密集。【这里先铺垫一句,传统目标检测的GT box是4个值-左上角和右下角的(x,y)坐标,共四个值;而航空目标检测(也可说旋转目标检测)是有8个值来表示GT box-矩形框四个角点的(x,y)坐标,共8个值】

动机:在航空目标检测任务中主流的方法是将此类任务视为(旋转目标检测,1.对目标框进行定位,2.对目标进行分类,3.回归预测处一个框的旋转角度),虽然定位比较准确,但是旋转方向的回归很多时候是不太准确的。作者就考虑,基于旋转角度的方向预测是不准的,选择不适用角度值预测方向。使用RepPoints点集表示目标框架使用点集对目标进行定位和结构的的表示,通过点集表示的目标结构直接回归处带有方向的检测框。这样避免了对角度的预测,通过目标结构预测定向更准确。
想要从零看懂这篇论文需要有知识框架的铺垫,1.理解可变形卷积。2.理解RepPoint点集表示目标检测框架。有兴趣可以自行查看原文:1. Deformable Convolutional Networks 2. RepPoints: Point Set Representation for Object Detection
1.2 Introduction:可变形卷积
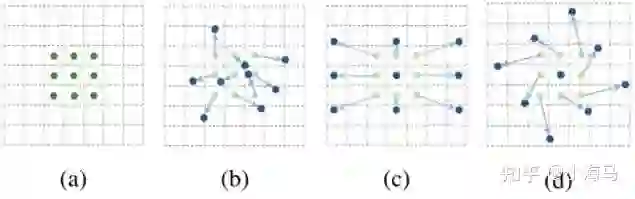
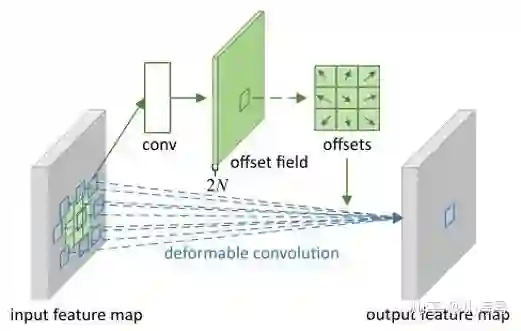
首先要先理解一下可变形卷积,现在来看图3,这是可变形卷积想要表达的采样形式,a是代表普通的卷积核是3*3的,所示采样的点数是9个,b,c,d都是可变形卷积(c、d只是一种特殊的形式),可以看出a普通卷积采样的位置是固定的,而可变形卷积做的事情就是给9个采样点,每一个点加一个偏移量得到9个点新的采样坐标(偏移量是小数,例如原一个采样点坐标(3,4)加上偏移量可能为(3.6,5.8)坐标变成了小数,这个时候就用双线性插值法为该点取值),把新的9个位置作为可变形卷积采样点的位置,进行常规的卷积加权的操作。只是改变了采样点的位置。
在来说一下可变形卷积的结构,先从输入的特征图中,单独用一个小的卷积分支对特征图中的每一个点都学习一组偏移量的信息offset field(这里的通道数是2N,N表示采样点的个数3*3的卷积核N在这里表示9,2表示每个采样点都有x坐标偏移值和y坐标的偏移值),用来表示当卷积核的走到特征图该点的时候应该偏移到哪个位置来计算。这个偏移量没有具体的取值范围,offsets学出来值的应该是有正有负的小数(正负代表方向),代码中有后处理是的在加上偏移量的新采样的位置不会超过特征图的范围。这个offsets就是点集表示目标的关键。
1.3 Introduction:RepPoints
RepPoints点集表示的目标检测和CenterNet其实是同一时期的文章都是2019年的属于anchor free的表示。在看这篇文章的时候网上的很多解读都是非常模糊,细节不清楚这就导致很难理解2022年的这篇Oriented RepPoints。自己仔细阅读梳理了一下这篇RepPoints文章,了解之后再看2022年的就很容易理解。(这里涉及了很多的细节,可能文章设置的逻辑有一点乱。不理解细节对不太熟目标检测框架的朋友很不友好)
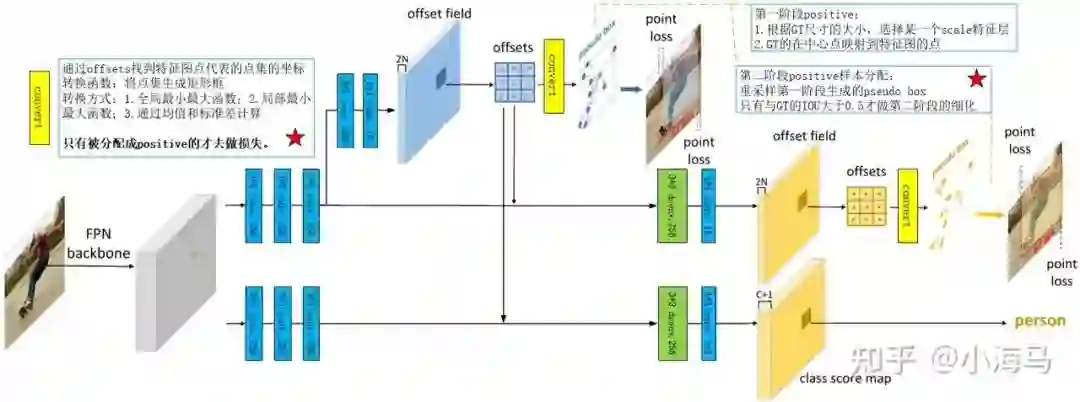
论文中给出的流程图实际上不容易理解,这我在论文中的基础之上又重新画了一下。首先我们先从整体上来看这个网络,目标检测通常是分为定位目标位置和分类两个内容。这个网络的训练定位是分为两个阶段,分类是一个阶段。首先这个网络的backone是用的FPN,出来的是5个层级的Scale的特征图,在此处只对一个特征图出来的head举例子。一层特征图出来被分为两个分支,一个用来做目标的定位,另一个用来做分类。
定位分支首先是从一层特征图中做三次3*3的卷积,然后分为两个支路,上边的支路用作学习可变形卷积的offsets,通过offsets可以得到点集各个点的位置,可以从位置转换成边框,相当于两阶段的网络提出proposal的过程。下边的分支是用来对第一阶段的提出proposal做一个细化的定位。
上边的分支是典型的可变形学习产生Offsets的操作,先用一个3*3的卷积学习一下特征,然后1*1的卷积用来改变通道产生offsets,offsets的特征图是2N,N代表的是卷积核采样点的个数,乘以2的意思是说每一个采样点的的偏移量对应x方向的偏移和y方向的偏移,特征图的每一个点就代表一个点集(也可以说是代表一个目标或者代表一个anchor,此处的点集的个数默认是9,因为3*3的卷积核对应9个采样点),偏移量的取值是有正有负的小数(没有对取值范围进行限制,但是会对超出边界的采样点进行处理),偏移量加上特征图中点的位置可以得到采样点的位置,9个点按照scale的倍率映射回原图中的坐标,这个时候我们得到了一组点集9个点的坐标,在通过转换函数Convert即可以生成pseudo box,至此可以说是为特征图中的每个点都生成了一个ancher/pseudo box/proposal。(个人觉得在这里这三种叫法都说的过去) 第二阶段产生pseudo box的方式和第一阶段相同。
定位分为两个阶段:对于这两个阶段,在训练中只有positive目标被分配成为RepPoin作为正样本去做定位损失。两个阶段的定位损失都是smooth L1 loss对pseudo box的左上角和右下角的点做(这里可以看出实际上做损失监督的方式应该算是弱监督---不是直接对点集中点的位置做,而是对通过点集生成的pseudo box做损失。)一阶段正样本的选择方式1.通过GT的尺寸和下采样的倍率关系找出目标应该出现在特征图的哪一层(哪个scale,FPN出来了五层不同大小的特征图应该属于哪一层);2.满足GT的中心点映射到特征图中点的位置。第二阶段细化阶段是先用一个可变形卷积学习一下然后是1*1的卷积,产生一组offsets,细化阶段指对正样本进行细化。第二阶段选择正样本的方式,在第一阶段产生的所有pseudo box中与GT的IOU的值大于0.5才去做细化的损失。
分类:分类分支也是对positive pseudo box(有目标的框)做分类,第一阶段产生的pseudo box与GT的IOU大于0.5认为有目标的框做分类损失,用的是focal loss。
转换函数Convert有三种:1.Min-max function.通过点集所有点的x,y坐标的最大最小值画框。2.Partial min-max function.通过点集部分点(代码中是前四个点)的x,y坐标的最大最小值画框。3.Moment-based function.通过一组点集中点位置的均值和标准差回归出框的位置。////////三种准换函数选择一种来应用,都是可导的再网络中可以反传。
分配positive总结:定位一阶段,根据GT的尺寸 s(B) = ⌊log2(√wBhB/4)⌋,选择给某一个scale的特征层;GT的中心点对应到特征图里的位置的一个feature map bin。满足这两个条作为positive。定位二阶段,第一阶段生成的box,与GT的IOU大于0.5的时候才拿去第二阶段作为positive进行细化。分类阶段,只对第一阶段生成的pseudo box进行分类,与GT的IOU大于0.5表示有目标作为positive再进行分类(特征图的通道C+1,是类别数+背景),小于0.4认为无目标,0.4-0.5之间的pseudo box被忽略。
思想理解:1.通过第一阶段的offsets产生点集定位,将offfsets作为分类和定位中可变形卷积(绿色的卷积快)中的偏移量,巧妙的将位置信息和类别特征结合起来,再网络反推学习的过程中可以联合监督。2.第一阶段的损失实际上只选择了一个positive(为一个目标选择了一个尺度中的一个pseudo box),这样可以在第一阶段就监督正确尺度和位置应该有最大特征响应。
理解Oriented RepPoints需要关注的地方:两个标注五角星的地方。1. RepPoints中的转换函数是转换成垂直的矩形框,而Oriented RepPoints需要的是定向框。2.第二阶段重采样的positive样本方式---第一阶段生成的pseudo box与GT的IOU值大于0.5才做第二阶段的细化。作者认为这种只用IOU衡量的方式是丢失了很多的信息(例如pseudo box的分类质量、方向质量没有有效来利用),需要更好的选择样本的方式。3.定位的smooth L1 loss是实际上在做定向目标检测时会有问题(下文会详细的探讨),作者对定位的损失也做了适用性的改进。
2. Flow chart:Oriented RepPoints
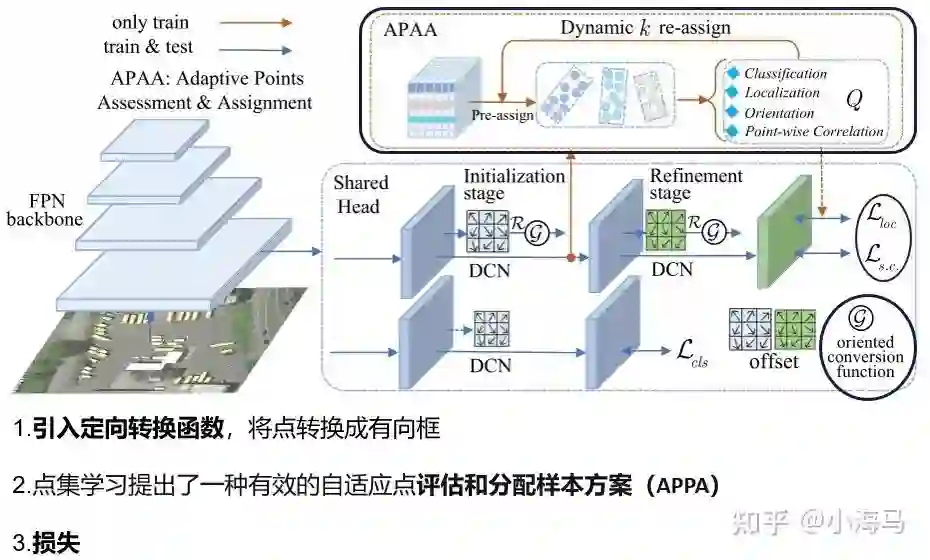
至此所有的铺垫基本完成,下面来看我们正文。这是今天的主要内容Oriented RepPoints.这张图是文章中的原图,这张图只是画图的表示方式不同。(除了用框标注出来的三处不同其他网络结构完全一致。注意reppoint中的数据是垂直box,GT的组成是四个值,左上x左上y右下x右下y;而Oriented RepPoint是用8个值表示GT框,四个角点的(x,y)总共8个值)。下面来看3个方面的变化,
1.引入定向转换函数,将每个特征图中一个点代表的点集(9个点),转换成有向的框。(对应reppoint中的生成框的部分,reppoint中是通过9个点映射回原图的位置画出了垂直矩形框。针对定向目标数据的不同改了转换函数)
2.点集学习提出了一种有效的自适应点评估和分配样本方案APPA,(此处对应的是reppoint中的第二阶段拿去细化的positive样本的分配。)
3.为了匹配定向目标数据和转换函数,提出了损失函数的改进。
下面来具体解释一下这三个方面的改进。
3.1 Method:oriented conversion function(定向转换函数)
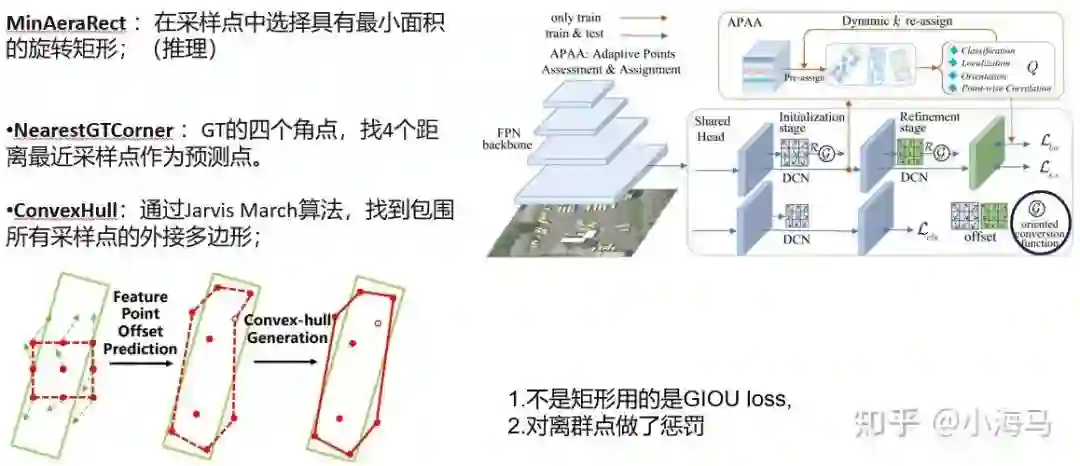
关于转换函数,作者是尝试了3种表示。MinAeraRect、 NearestGTCorner、ConvexHull,因为输出需要时矩形框所以预测和推理的时候只用MinAeraRect;训练网络的时候用NearestGTCorner、ConvexHull中的一种。
1.MinAeraRect :在采样点中选择具有最小面积的旋转矩形;(该函数不可导在网路中训练参数不可以反传,所以只在推理的时候应用,此处是用cuda代码写的如果不做此方面的改进可以不必深究)
2.NearestGTCorner :GT的四个角点,找4个距离最近采样点作为预测点。
3.ConvexHull:通过Jarvis March算法,找到包围所有采样点的外接多边形。
这里可以看出来,NearestGTCorner 和ConvexHull转换函数实际上生成的不是一个规则的矩形,而是一个不规则的四边形和多边形。所以这个时候就能用GT的角点来衡量loc的损失,这里是用的GIOU的损失,也对分布在GT范围以外的离群点做了惩罚。惩罚项就是对超出GT的离群点做惩罚,让所有的点分布在GT box之内。【这样其实不难理解,在刚训练网络的初期时候可能多边形是很乱的,但是经过一次次的迭代训练(GIOU和离群点惩罚的监督)多边形框就会越来越接近标准的矩形】
3.2 Method:Adaptive Points Assessment and Assignment(自适应点集评估和分配样本方案)

这里是对于RepPoint中第二阶段选择positive样本方式的改进,原来是只要一阶段产生的pseudo box与GT box的IOU>0.5就被选为positive来做细化。作者认为直接按照IOU的标准是丢失了很多点集所表示的信息,所以作者提出了一个自适应点集评估和分配样本方案(Adaptive Points Assessment and Assignment)。该方案是在pseudo box与GT box的IOU>0.5的基础上,对这些pseudo box再从四个方面来衡量质量的好坏,然后按照质量分数对其进行排序,通过一个采样率选择质量分数Top前几的作为positive样本进行细化,通过此方式训练的网络可以更好
自适应点集评估和分配样本方案(APPA)从四个方面来衡量点集框的质量
1.分类质量:该点集与GT的分类损失focal loss来衡量分类质量。
2.定位质量:点集生成的多边形与GT的GIOU损失值来作为衡量定位的质量。
3.定向质量:定向质量实际上是通过倒角距离(Chamfer distance)来衡量,实际上这个距离的衡量方式是点集集合或者3D点云的思想。这里也不放具体的公式了感兴趣可以翻一下原文,只是简单说一下思想。首先对pseudo box和对应的GT box框一条边上等距离的分别采样40个点作为一个集合,形成pseudo box点集合和GT集合。倒角距离来衡量两个集合中点的距离。作为该边上定向的质量分数。(四条边每一条都这样做)
4. 逐点相关性质量:这个衡量的其实是点集中的一个点与整个点集所表示的特征的关联性。ei,k 表示第i组自适应点的第k点特征向量;ei 表示第i组特征向量的平均特征。而 e*i,k 和 e*i 分别表示进行规范化之后的特征向量,衡量这两个特征向量的余弦距离。
动态TOP K标签分配:按照质量分数排序最前面的质量最高。Nt 表示参与质量评估的所有点集,也就是和GT的IOU>0.5的点集; σ是采样率。意思很简单就是选择质量分数排在前面k的点集生成的pseudo box去做第二阶段的细化。
3.3 Method:Loss function
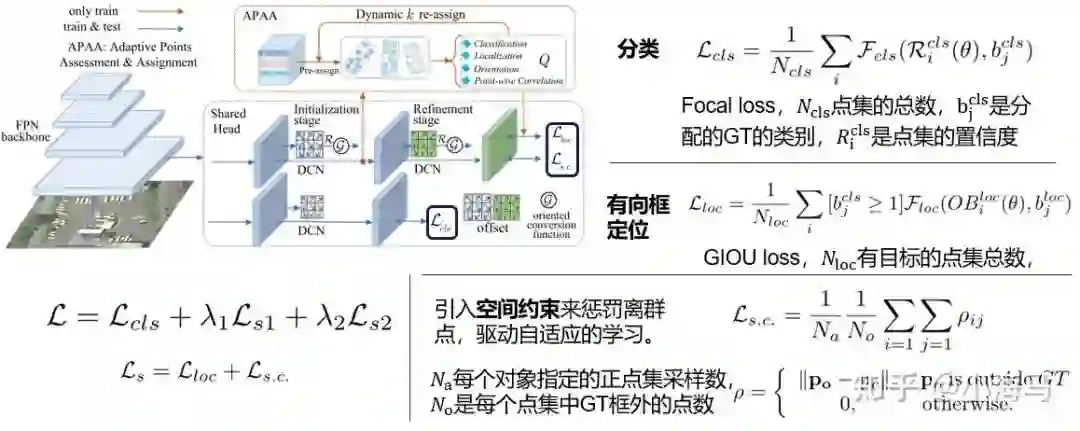
这里应该都是很好理解的,只有个别的参数不是很清楚。首先是分类和定位损失中的 θ 这个参数论文里其实没有介绍和描述很难理解。通过对这个架构的理解,还有他再定位和类中都有出现,感觉理解成一个阈值比较合理就是定位和分类选择样本的IOU的0.5。Po 表示点集中不在对应GT中的点的坐标(out GT), Pc 是指GT中心点的位置。
4. Experiment
思想已经很清晰了,实验以后再补吧。
喜欢的点赞,希望收藏的朋友随手给个赞吧。(收藏数比赞同数可多太多了)

点击进入—> CV 微信技术交流群
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
![]()
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()