目标检测最新方向:推翻固有设置,不再一成不变Anchor
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | Tenacious
来源 | https://zhuanlan.zhihu.com/p/56228320
前言
目标检测是计算机视觉中的一项基本任务,从图像中定位出物体,并给出其具体的类别。在深度学习“一统江湖”下的目标检测算法,大量依赖于Anchor机制。简单来说,即在图像上设置巨量的先验框,学习怎么变换它们来定位和分类物体。基于Anchor的目标检测器在 Faster R-CNN(2015)提出之时兴起,到如今,它的弊病已经越来越明显,改进Anchor机制的方法层出不穷。本文紧跟前沿趋势,遴选出了有代表性的方法,并配合细致的解读以飨读者。
目录
回顾Anchor机制
·Anchor是什么?
·Anchor机制又是什么?
·Anchor机制的优缺点
改进Anchor机制的各类方法
·变静为动,让Anchor动起来
·摒弃Anchor,使用关键点完成定位
·融合Anchor与关键点的方法
总结与展望
回顾Anchor机制
Anchor 是什么?
在检测任务中,输入图像经过骨干网络提取得到特征图,该图上的每个像素点,即为anchor锚点。
Anchor机制又是什么?
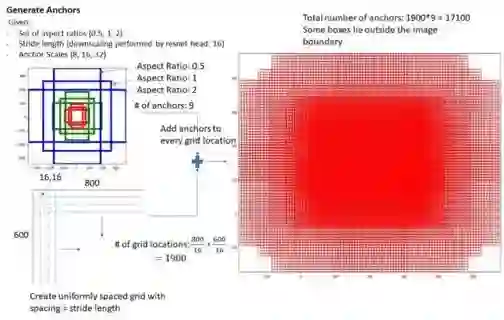
以每个anchor为中心点,人为设置不同的尺度(scale)和长宽比(aspect ratio),即可得到基于anchor的多个anchor box,用以框定图像中的目标,这就是所谓的anchor 机制。如下图所示,左侧显示了基于一个anchor点生成的9个anchor box(红、绿、蓝三种颜色),右侧显示了该特征图上密集分布的所有anchor box。
Anchor机制的优缺点
知道了anchor和anchor机制是什么,那接下来就说说它在检测任务中起到的优缺点。这里我们总结了以下几个方面:
1. 优点:
(1)使用anchor机制产生密集的anchor box,使得网络可直接在此基础上进行目标分类及边界框坐标回归;
(2)密集的anchor box可有效提高网络目标召回能力,对于小目标检测来说提升非常明显。
2. 缺点:
(1)anchor机制中,需要设定的超参:尺度(scale)和长宽比( aspect ratio)是比较难设计的。这需要较强的先验知识。
(2)冗余框非常之多:一张图像内的目标毕竟是有限的,基于每个anchor设定大量anchor box会产生大量的easy-sample,即完全不包含目标的背景框。这会造成正负样本严重不平衡问题,也是one-stage算法难以赶超two-stage算法的原因之一。
(3)网络实质上是看不见anchor box的,在anchor box的基础上进行边界回归更像是一种在范围比较小时候的强行记忆。
(4)基于anchor box进行目标类别分类时,IOU阈值超参设置也是一个问题,0.5?0.7?有同学可能也想到了CVPR2018的论文Cascade R-CNN,专门来讨论这个问题。感兴趣的同学可以移步:Naiyan Wang:CVPR18 Detection文章选介(上)
https://zhuanlan.zhihu.com/p/35882192
问题出现了,接下来我们将介绍针对Anchor机制的不足,涌现出的大佬们的解决方案,并且尝试去解读他们。
改进Anchor机制的各类方法
变静为动,让Anchor动起来
MetaAnchor: Learning to Detect Objects with Customized Anchors (NIPS2018, 旷视科技 & 复旦大学)
paper: http://cn.arxiv.org/pdf/1807.00980v2
文章解决检测任务中anchor box超参设计难及训练过程中anchor box尺寸固定两个问题。建模G(bi; w)函数,用以动态生成anchor box。其中bi虽仍需要“用户”设定,但对先验知识的要求已大大降低,且网络学习过程中 anchor box 不再fixed更灵活,可适用网络学习状态达到更佳的检测效果。
网络结构框架:
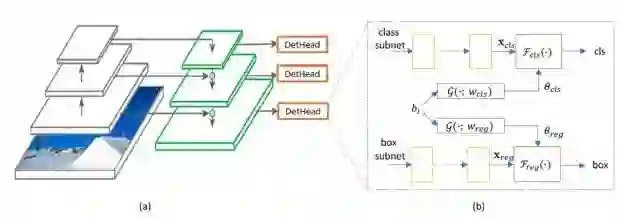
网络延用RetinaNet结构,在P3~P7 5个特征层上做检测。作者解释建模 customized box prior bi的细节:anchor box 需要包含目标的坐标,类别,尺寸等信息。由于网络是全卷积的,所以坐标信息很容易从feature map 映射回原图得到;至于类别信息,作者将其建模于G(.;Wcls)中学习;最后是坐标信息,作者采用log(ahi/AH)传递bi的宽高与anchor box宽高间的关系,其中AW,AH为standard anchor box的宽高,起归一化作用。
以上是对MetaAnchor算法的简单介绍,创新点在于把anchor box建模到网络中学习。其解决的是anchor box 的超参设定和尺寸固定两个痛点,但anchor box的冗余问题仍未解决...
摒弃Anchor,使用关键点完成定位
CornerNet: Detecting Objects as Paired Keypoints (ECCV2018, 密歇根大学)
paper: arxiv.org/pdf/1808.0124
Anchor机制的局限性在前文已经有所介绍。所谓目标检测不就是要检测出方框吗?那其实两个点就可以确定一个框了。而CornerNet正是这一思路,把检测任务转化为key-point任务来处理。通过检测目标的左上角点和右下角点,框定出目标。
网络结构框架:
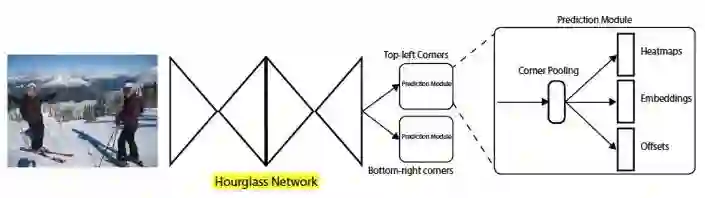
输入图像首先进入Hourglass网络部分进行关键点提取,而后通过左上角和右下角两个并行的预测模块来定位物体。这里的Hourglass网络广泛应用于人体关键点检测领域。我们分别来看Hourglass后的几个关键部分:
1. Corner Pooling 辅助提取角点特征
多数情况下,目标的角点都是在目标之外的,故角点处的特征缺乏语义及上下文信息,难以定位。故作者提出Corner Pooling来确定一个角点。简单来说,使用两个边界上响应最大的信息,经传递后叠加起来肯定也是全局最大的信息,即可确定左上角或者是右下角。
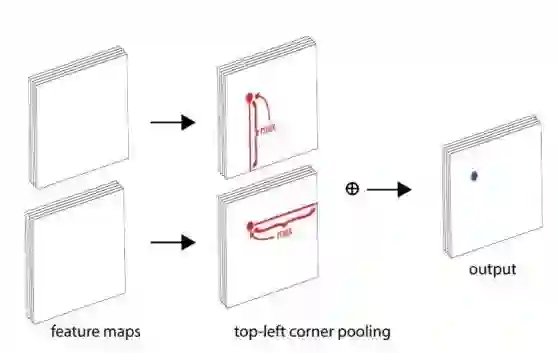
作者通过消融试验发现,使用corner pooling辅助可以得到2个点左右的提升,这个方法还是十分科学的。
2. 产生3个输出分支:heatmap、embedding、offsets
(1)heatmap,顾名思义,在特征图的分辨率下,角点的热力图。
(2)embedding,用于分清楚哪两个点属于同一个目标。
(3)offsets,完成对heatmap上的坐标修正。
添加offsets模块的原因在于,角点出自于低分辨率的特征图,这些key-points映射回原图后会产生一定的偏差,这样的偏差对于小物体的定位影响非常大。
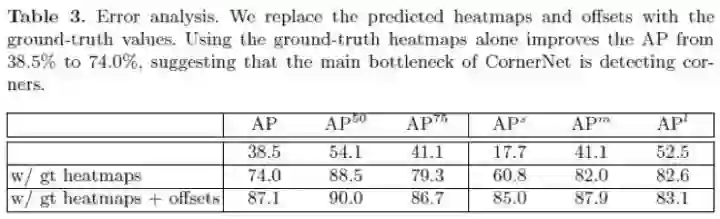
通过实验作者也验证了offsets模块可带来约10个点的提升,主要贡献来自于小物体的检测。另外呢,上表还透露出一个信息,那就是corner point的精准定位是算法的瓶颈问题,使用ground truth point 代替预测的corner point,AP从38.5提升至74.0。
那么思考下,为什么corner point定不准呢?在这里我们认为,corner point定位需要的语义信息并不充足。角点并不像人脸的关键点、人体骨骼点那样,特征表达明显且语义及上下文信息充分。那么我们接下来介绍的这篇文章,同样是摒弃了Anchor的方法,并且其检测的关键点也是有明确的意义的。
Bottom-up Object Detection by Grouping Extreme and Center Points (arxiv’19,德克萨斯大学奥斯汀分校)
paper: arxiv.org/pdf/1901.0804
文章的创新点在于:
1. 引入extreme point辅助检测
所谓extreme point就是在某个方向上的一个极大坐标边界,文章即在目标的left、right、top、bottom四个方向上预测4个extreme points
2. 采用Center Grouping策略组合points
除去4个extreme points,算法会再预测一个“几何中心”,这个几何中心担任了将extreme point分隔到不同物体上去的任务。算法采用Center Grouping策略完成点到目标的组合配对。
3. 算法在Detection和instance segmentation任务上均取得较好的表现
算法结构框架:

算法延用了CornerNet除corner point embedding外的大部分结构,point embedding部分则使用Center Grouping代替。Center Grouping其实并不神秘,流程如下:
1. 针对extreme point和center point分别设定阈值Tp、Tc;
2. 利用4个extreme point计算目标的几何中心点(cx, cy),根据中心点坐标取得center point预测结果处的概率值
3. 概率值大于阈值Tc的(extreme point, center point)组合即被定义为一个bounding box。
可以发现Center Grouping本质是一种暴力枚举方法,好像不是很优雅,但效果又还行的样子..
文章的其他tricks就不在此赘述了,感兴趣的同学可以移步原文慢慢推敲哦。Sense的点在于不要corner point,center point这类语义及上下文信息不充分的“easy point”,而是找到extreme point这种天然就依附在目标上的点,这使得网络在找点阶段的任务轻松许多。但是插播一句,对于extreme point检测,算法是需要使用segmentation label的,这种“辅助”操作是不是有点unfair啊...
融合Anchor与关键点,面面俱到
Region Proposal by Guided Anchoring (arxiv’19,香港中文大学-商汤科技联合实验室,香港中文大学)
paper: arxiv.org/pdf/1901.0327
极市之前推送过来自作者的官方解读:陈恺:Guided Anchoring: 物体检测器也能自己学 Anchor
文章使用全新的思路完成目标检测任务:
1. 首先定位可能的目标中心点
2. 基于中心点,设置最优anchor box完成目标定位及识别
网络结构框架:
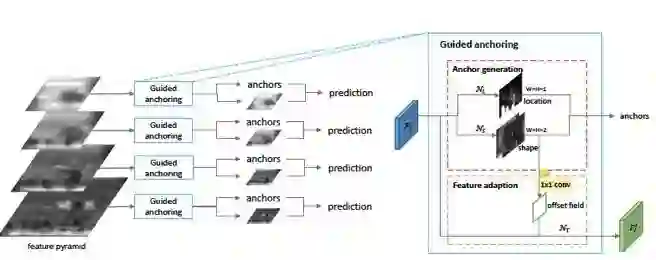
1. Anchor Location Prediction
即目标中心点定位。首先检测目标的中心点,完成对图像内目标的初步定位,这可大大减少后续设置冗余的anchor boxes,文章使用一个简单的1x1卷积实现。
2. Anchor Shape Prediction
针对每个检测出的中心点,设计一个最佳的anchor box。最佳anchor box的定义为:与预测的候选中心点的邻近ground truth box产生最大IOU的anchor box。
作者认为,直接预测anchor box的宽高的话,范围太广不易学习,故将宽高值使用指数及比例缩放(w=alpha*s*exp(dw))进行压缩,将搜索范围从[0,1000]压缩至[-1,1]。
3. Anchor Guided Feature Adaptation
这是文章非常sense的一个点:当目标中心点确定,会在此基础上设定一个best anchor box。再细想一步,这个中心点上可能存在的目标的尺度和长宽比是多变的,是因点而异的。那么我们希望该中心点映射回原图的那部分区域的特征fi具有适应目标多形态的“能力”。故对fi进行encode:
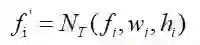
其中NT(*)为3x3的deformable convolution,wi、hi为best anchor box的宽高。
以上是对center point guided anchor算法的简单介绍,创新点在于结合了anchor和point在检测任务中的不同优势。首先确定目标中心点实现目标的粗定位,然后在此基础上创建anchor box框定目标,避免了CornerNet中的角点配对问题。并且基于点设置anchor box指代明确,一个box就对应检测一个物体。算法在coco数据上达到减少90%的anchor box量且获取9.1%的recall提升。算法迁移至Fast R-CNN, Faster R-CNN 和 RetinaNet上可分别获得2.2%, 2.7% 和1.2%的提升。耐心读到这里的亲可以思考下,低分辨率特征图上产生的中心点,是否存在将原图中临近目标中心重叠的问题呢?
结语
在本文中,我们对Anchor机制做了一个简短的回顾,并对当前最新的方法做出了概述和解读。可以发现,无论是对anchor box建模学习的MetaAnchor算法,或是使用corner point以及extreme point实现检测任务,或是结合center point及anchor box两者优势完成目标检测等创新算法,均没能“尽善尽美”~ 相信会有更鲁棒的算法解决检测任务中的各个痛点,我们也会跟进学习并尝试创新,敬请期待~~~ 最后,文末再次感谢您的阅读。文中出现的错误,还请不吝批评指正,也欢迎在评论区与我们共同交流进步 >ω<~
本文保持持续更新,不断完善,欢迎各种“指教”~~~
cooperated with @ChenJoya
our team: 腾讯/PCG/感知智能组
*延伸阅读
Guided Anchoring: 物体检测器也能自己学 Anchor
CVPR2019 | 目标检测新文:Generalized Intersection over Union
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~



