【NeurIPS22】大图上线性复杂度的节点级Transformer
如何构建大图上的线性复杂度Transformer?本文将要介绍的发表于NeurIPS22的工作对这一开放问题给出了探索性的思路,这项工作也入选了会议的Spotlight Presentation(比例约5%)。
论文题目:NodeFormer: A Scalable Graph Structure Learning Transformer for Node Classification
作者信息:吴齐天,赵文滔,李泽楠,David Wipf,严骏驰
论文地址:https://openreview.net/pdf?id=sMezXGG5So
项目地址:https://github.com/qitianwu/NodeFormer
简介
尽管图神经网络(以下简称GNN)目前已成为对图结构数据建模和表征的主流范式,其“沿着固定输入图结构进行信息传递”的设计思想也暴露出了诸多不足。由于每层聚合只考虑相邻节点间的信息传递,这种有限的感受野(receptive field)设计使得GNN无法有效利用来自其他节点的全局信息。此外,在很多下游任务中,输入数据可能并不包含图结构(如图片分类中,每张图片样本是独立的),此时GNN对输入图结构的依赖性导致其无法正常工作。
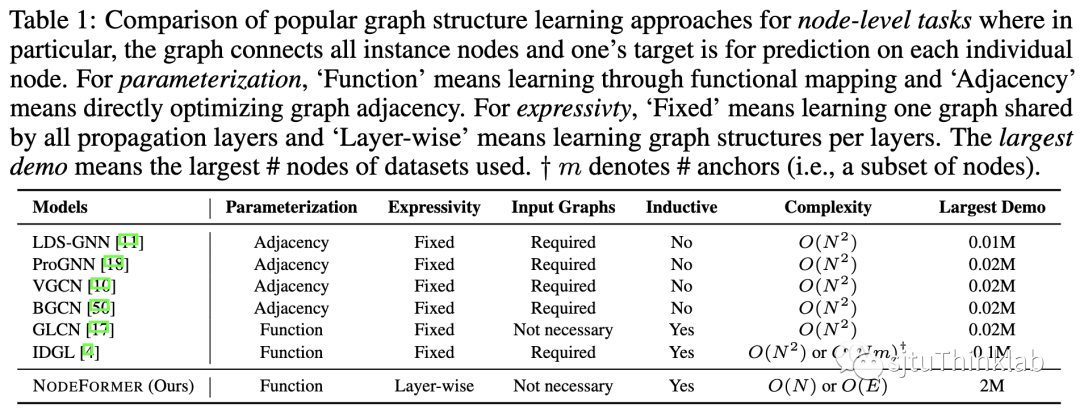
本文提出了一种新型的图表征模型架构,称为NodeFormer,它实现了每层任意两两节点间的信息传递,即在每层的信息聚合中会考虑图中所有其他节点对当前节点的影响。NodeFormer设计思想的直观理解就是把GNN定义在了一个两两节点潜在相连且每层的图拓扑可学习的计算图上。 然而,这种简单直接的设计思想却带来了令人望而却步的计算复杂度(节点数目的平方级复杂度),使其无法扩展到大规模节点分类图上。为此本文提出了一种具有线性复杂度的可变图结构信息传递方法,使得上述思路首次成功扩展到了百万级规模的节点分类图上,这一方法还能被用于处理没有输入图的问题。
研究背景
虽然GNN在众多图数据建模的任务上都取得了优异的表现,但其在很多场景下暴露出的不足目前也备受关注。例如,GNN对于图中“遥远”的节点会过度挤压(over-squashing),在聚合过程中稀释掉这部分信息;GNN有限的感受野使其难以捕捉长距离依赖(long-range dependence);GNN聚合邻居信息的设计不能很好兼容包含异配关系(heterophily)或连边残缺的图;以及在极端的没有输入图的情况下,GNN就无法正常工作了。
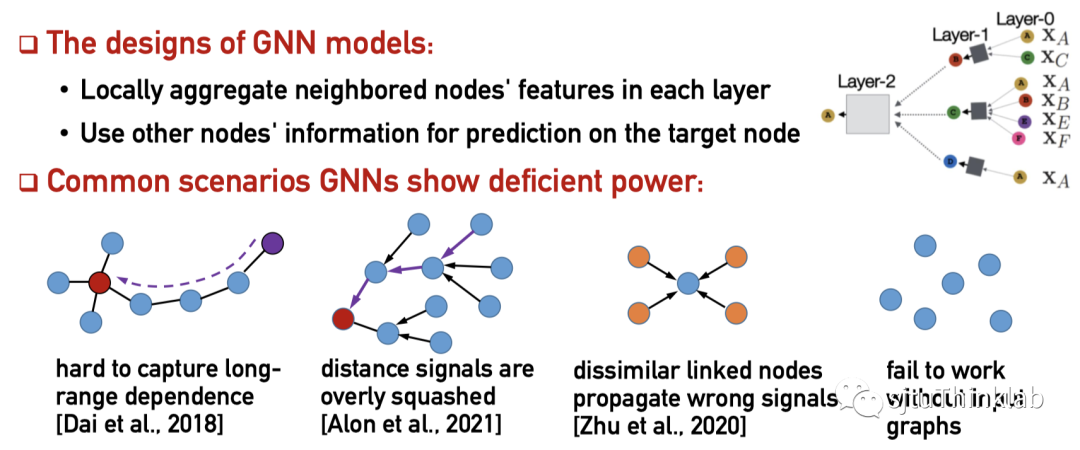
这一系列的问题和局限性都源自GNN的核心设计思想“沿着固定输入图结构进行信息传递”,这也启发了我们是否能构建一个不依赖于固定输入图的模型,可以在一个更灵活的隐式图上实现两两节点的信息传递。
大规模图结构学习的技术挑战
然而,要学习一个全新的图结构,实现两两节点间的信息传递是非常困难的,尤其对于大规模的图。主要有以下两点挑战:
-
可扩展:不管是学习一个最优图结构,还是实现两两节点的信息传递,这二者都需要 的复杂度(N表示节点数目)。对于大规模图 的计算复杂度是非常棘手的,具体的比如当考虑万级别节点两两之间的信息传递时,16GB的显存就难以容纳了。 -
可微分:图结构本身是离散的,当考虑对图结构进行优化时一种理想的情况是能实现端到端的梯度更新(高效且稳定),此时就要求对图结构的学习也是可微分的。
NodeFormer:可扩展的节点级Transformer
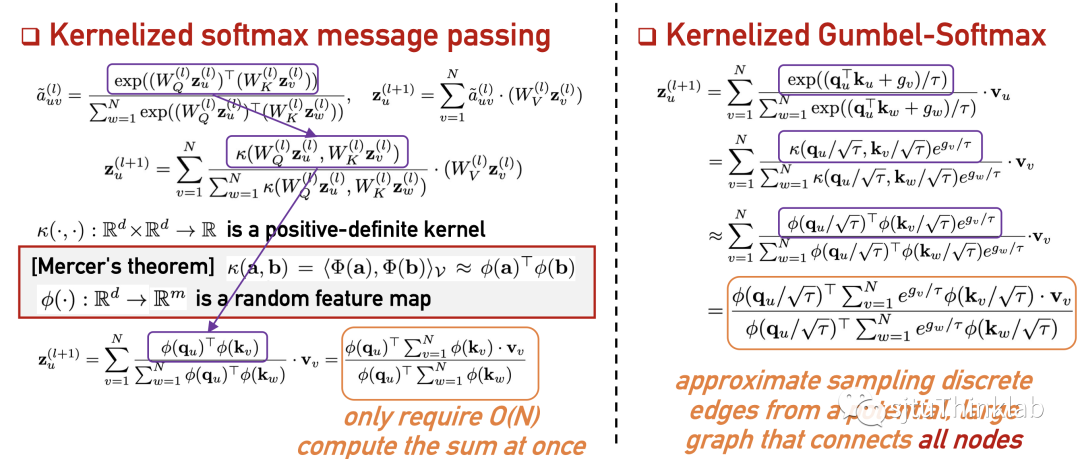
本文提出的方法简单的说就是将Random Feature Map[1]和Gumbel-Softmax[2]两种近似策略有机融合(为什么说“有机融合”,因为我们提供了理论保障分析),从而实现了线性复杂度下大规模信息传递图结构的学习。
具体的,下面介绍本文核心思路的公式推导。假设图中有 个节点,我们考虑对任意节点 ,使用 表示它在第 层对应的表示向量,于是下一层结果的更新公式为
这里的 , , 由第 层的特征变换得到(对应Transformer里的key/query/value)。(1)式可以看作把Transformer定义在了图上,即图中所有节点组成了一个很长的输入序列(“一个”也是强调节点分类中通常只有一张很大的图)。另一种理解是从Graph Attention Networks的角度出发,(1)式也可以看作图注意力机制被定义在一个所有节点均两两相连的图上。
显而易见的是(1)式需要 的复杂度,因为对于任意节点都需要单独计算其他 个节点的注意力。为了解决这一困难,我们采用核方法对exponential-then-dot这一操作进行近似,即,这里的 是一个Random Feature Map(RF),例如常用的Positive Random Feature(PRF)[3]可以定义为
于是我们可以把(1)式变换为
这样做的好处是上式右侧的结果所包含的两个求和项对所有节点是共享的(即不随 变化),因此我们只需要计算一次,总的复杂度保持在 以内。
以上的建模和推导都假设每条连边有一个连续的注意力权重值,为了更进一步的考虑将连边“离散化”,我们换一个建模思路来看待这个问题。对于任意节点 ,我们其实需要的是找到在每一层中一个“最优”的邻居集合,进行信息传递。所以我们可以把 个节点产生的注意力权重视为一个Categorical Distribution,然后从中采样得到邻居集合。尽管采样的过程不可求导,我们可以借助Gumbel-Softmax对其进行近似处理。具体的就是把原先的(1)式中的Softmax替换为Gumbel-Softmax
庆幸的是虽然上式加入了Gumbel noise和温度系数 ,我们依然可以沿用之前的思路使用RF进行线性复杂度的近似:
上式的计算我们称为Kernerlized Gumbel-Softmax Operator,这也是NodeFormer模型实现线性复杂度的核心部件。为了更直观的展示公式的推演过程,我们将上述的推导用下图概括。
理论分析
虽然目前我们已经基本实现了最开始的目标,对于解决实际问题我们可以直接利用Kernerlized Gumbel-Softmax Operator在 复杂度内对大规模信息传递图结构进行学习。但回到方法本身,我们仍然有两个基础性的理论问题需要解决:
-
(2)式在融入Gumbel noise后是否仍能近似相应的exponential-then-dot操作(以及近似误差)? -
(2)式的温度系数对采样结果的影响,样本是否能视为对原始Categorical Distribution的采样?
对于上述两个理论问题的回答感兴趣的读者可以阅读我们论文的3.2节,在定理1和定理2中我们分别对这两个问题做了回答,主要结论如下
-
融入Gumbel noise后的RF近似误差上界为 ,即与温度系数与RF维度有关,特别地,与节点数目 无关。 -
当温度系数 趋于0时,(2)式使用RF近似后的Gumbel-Softmax仍会逼近原始的Categorical Distribution。
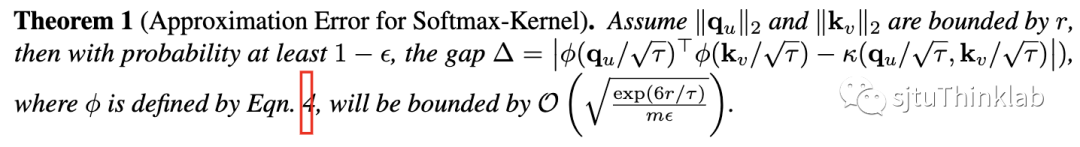
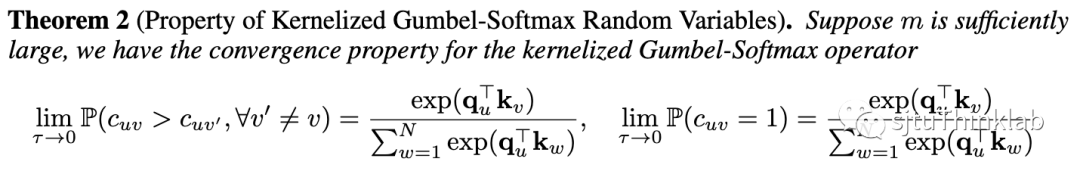
如何利用输入图信息?
到目前为止,我们都没有讨论输入图如何利用。对于有输入图的情况,一般图结构本身也包含了很多有用信息。本文提出了两种简单有效的策略对输入图结构的信息加以利用。这两种方法的计算复杂度都是 (E表示输入图中连边数目),即当考虑输入图时NodeFormer最终的计算复杂度为 。
Relational Bias 第一种策略是在每层信息传递时,对观测连边的权重进行加强,我们为每条边赋予一个共享的可学习的权重,称作relational bias,于是每层的更新公式更改为
其中 是第 层对应的可学习的权重参数, 是一个可选的非线性映射。
Edge Regularization Loss 第二种策略是把观测连边作为监督信号,加入到学习目标函数中。具体的,我们把模型每层的注意力估计视为一个Categorical Distribution,而观测连边视为样本,于是采用极大似然估计定义一个连边的损失函数
其中 表示节点 在输入图中的度(degree), 表示模型中间层的注意力估计。此外,带标签的训练节点本身定义了节点分类的监督目标:
最终的目标函数就是上面两个式子的加权和 。当然,为了消除上述设计没有理论支撑的顾虑,本文也提供了如何从贝叶斯视角理解上述两个目标函数的共同存在的意义,可以证明 的加入可以帮助模型学到的隐式图结构逼近最优后验分布的采样。
实验结果
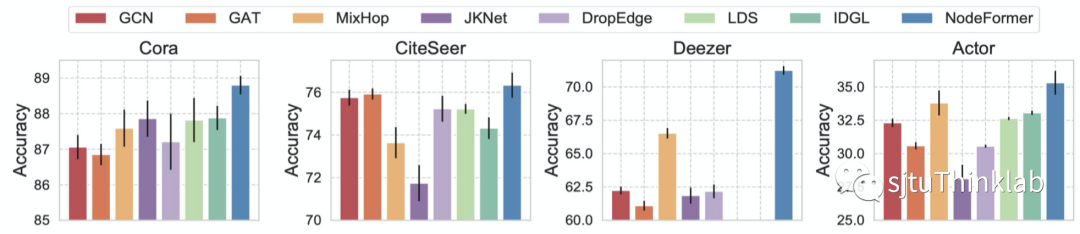
为了验证提出的方法,本文在不同任务上开展了大量实验。首先是在中等大小(1K~10K节点规模)图上的节点分类结果,对比了常用的GNN方法和先进的图结构学习方法LDS和IDGL,结果如下图。在取得更好分类精度之外,NodeFormer也极大的节省了训练时间和空间的开销,相比于图结构学习方法LDS取得了93.1%/75.6%训练时间/空间的降低。
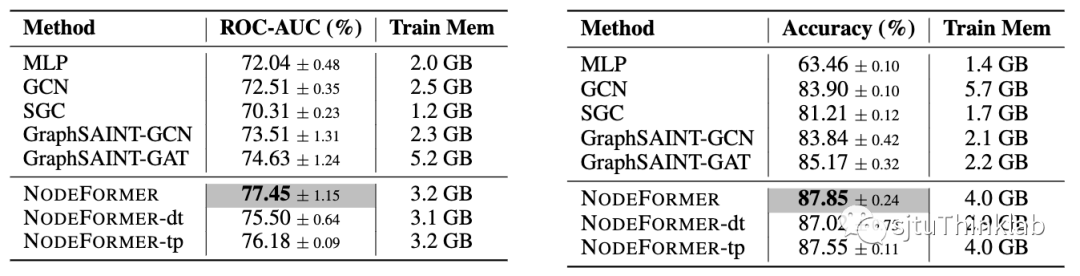
对于大规模节点分类图数据集,本文考虑了OGBN-Proteins和Amazon2M,他们分别包含0.13M和2.4M的节点。由于本文的方法对输入图结构的依赖性不强,我们可以灵活使用mini-batch随机划分训练样本,考虑batch内部的信息传递以节省空间开销;又因为我们的方法只需要线性复杂度,因此允许我们使用较大的batch size。例如我们在两个大数据集上分别使用10K和0.1M的batch size,GPU内存消耗可以控制在4GB以内,下表展示了实验对比结果。
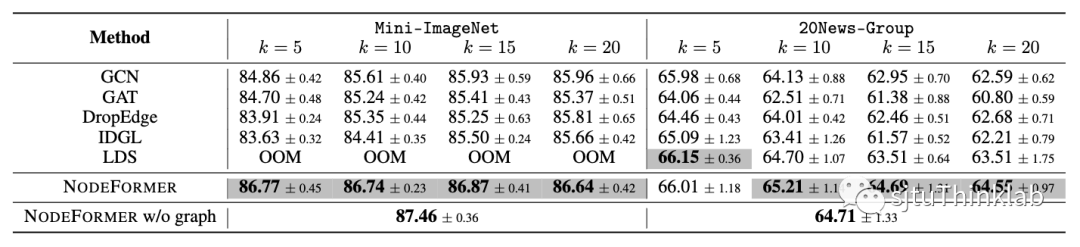
另一个NodeFormer可以发挥作用的场景,是没有输入图的情形,这里我们考虑图片和文本分类,输入样本之间没有连边信息。如果要使用输入图结构(例如GNN模型以及NodeFormer中两处用到输入图的模块),常规的做法是使用kNN方法人工定义一个样本间相连的图。下表显示了使用不同的k=5,10,15,20几种方法的对比性能。有趣的是,在不使用输入图的情况下,NodeFormer仍能取得有竞争力的结果。
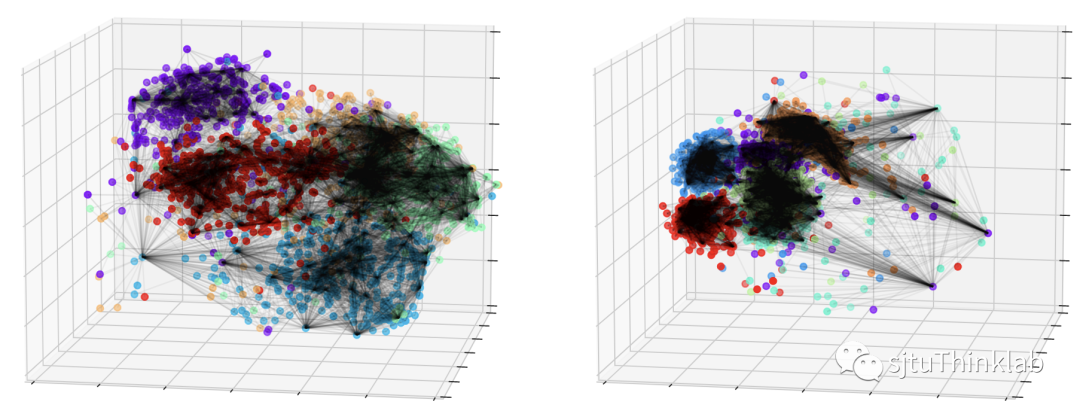
为了进一步探索模型学到的隐式图结构的特性,我们对估计的连边(筛选出权重大于某个阈值)和节点embedding做了可视化。可以看到,同类节点之间的连边较为密集,不同类的节点之间也会存在少许的连边。
与现有工作的对比和总结
目前也有很多工作考虑为GNN学习一个最优的信息传递图结构,或者研究图上的Transformer,这里我们做一个简单的对比和总结。简单的说,相比于其他图结构学习的工作,本文提出的NodeFormer拥有以下几个优势:
-
表达能力:考虑每层单独学习自适应的图结构,模型的表达能力更强 -
可扩展性:线性复杂度,可以扩展到大规模图,例如本文使用最大数据集包含百万节点,单卡GPU显存占用仅有4GB -
训练/推理高效性:不依赖于复杂的优化算法,可实现高效的端到端训练,例如Cora数据集1000个epoch的训练+评测只需要1-2分钟 -
适用性:可以在inductive和没有输入图的场景下工作,也可用于对隐式结构进行发掘
而对于graph Transformer,目前的绝大部分研究都侧重于图分类任务(每张图是一个样本,图的规模较小),例如分子图性质预测。本文首次探索了大规模图上的“两两节点间信息传递”,实现了面向节点分类大图的Transformer。当然,我们也相信沿着本文的思路存在着很大的拓展空间,此外本文提出的kernelized Gumbel-Softmax message passing也能很方便的被用作plug-in module,去解决大规模结构学习或隐式关系推断等问题。对于本文有任何疑问或希望进一步交流,可以发邮件至echo740@sjtu.edu.cn
Reference
[1] Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Advances in Neural Information Processing Systems, pages 1177–1184, 2007.
[2] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In International Conference on Learning Representations, 2017.
[3] Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamás Sarlós, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J. Colwell, and Adrian Weller. Rethinking attention with performers. In International Conference on Learning Representations, 2021.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NFME” 就可以获取《【NeurIPS22】大图上线性复杂度的节点级Transformer》专知下载链接



