复旦提出ObjectFormer,收录CVPR 2022!图像篡改检测新工作!

极市导读
本文中,复旦大学以人为本人工智能研究中心提出了ObjectFormer,借助视觉Transformer的优势建模物体层面的视觉不一致信息,从而为图像篡改检测提供了崭新的思路。该方法在常用的图像篡改数据集上取得了SOTA的效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

ObjectFormer for Image Manipulation Detection and Localization
论文:https://arxiv.org/abs/2203.14681
Part I. 动机
随着深度学习尤其是对抗生成网络的发展,图像编辑应用正逐渐走进大众的日常生活。然而,这些被修改的图片的视觉质量愈发提高,甚至可以达到以假乱真的效果。这就为互联网信息的可信性带来了严峻的挑战。出于提高多媒体数据安全的考虑,亟需研发有效的方法进行图像篡改检测。
图像篡改方法可以被大致划分为三种类型:
(1) 拼接,也就是将一张图像的部分内容(通常是某个物体)粘贴到另一张图像上;
(2) 复制-粘贴,将一张图像里的某个物体挪动到其它位置;
(3) 移除,将图像里的某个区域抹掉并根据周围的像素进行修复。
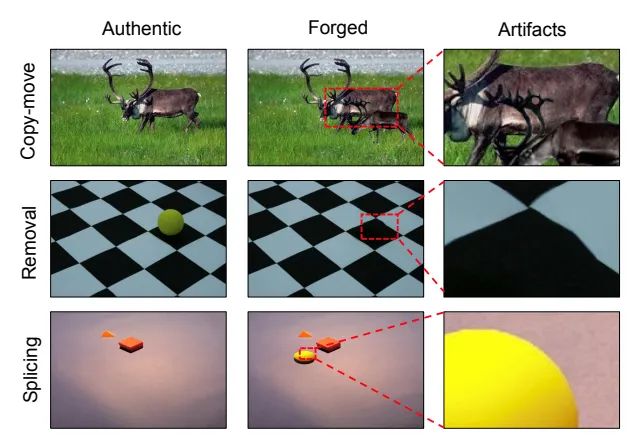
上图展示了由这三种篡改方法生成的伪造图像,为了产生有语义的图像,这些方法经常在物体层面 (object-level) 上对图像的内容进行修改,例如在图像中增加 / 删除物体。
现有的图像篡改检测方法通常使用CNN (卷积神经网络) 提取图像内的篡改信息,它们往往关注图像层面(高层)或者像素层面(底层)的视觉一致信息,而没有明确地对物体层面(中层)的表示进行建模。相比之下,我们认为,图像操纵检测不仅要检查某些像素是否具有异常,还要考虑物体之间是否一致。
对于传统的CNN模型来说,进行物体层面的建模是很困难的,因为具有固定权重的卷积核不能动态地分配一组神经元来表征图像内的物体。而随着视觉Transformer的兴起,对于这一问题的解决就有了可行的思路。
在这篇文章中,我们提出借助于Transformer的优势来明确地建模物体层面的视觉一致性信息,可学习的object prototypes被用作中层表征,并通过prototypes与图像patches之间的cross-attention,学习其与不同区域之间的依赖性。
Part II. 方法
ObjectFormer主要由三个组件构成,分别是高频特征提取模块、物体编码器和图像块解码器,下图给出了模型的完整框架图。
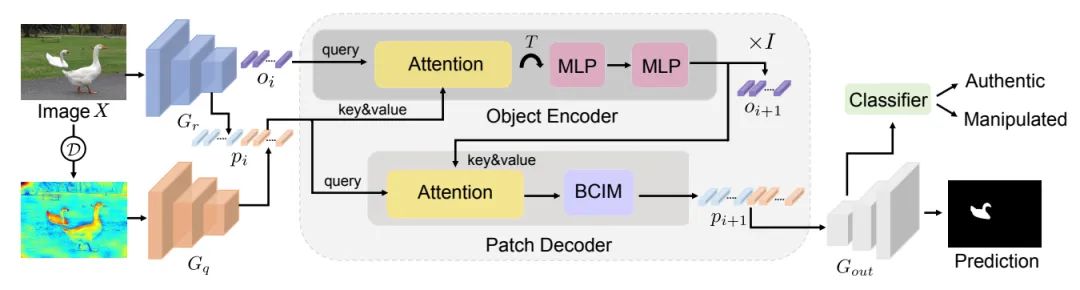
1. 高频特征提取模块
随着伪造技术的愈发成熟,由图像编辑带来的视觉伪影在RGB域中越来越难以被察觉,受启发于Deepfake检测中相关工作的探索,我们尝试利用频率信息来帮助发现微妙的伪造痕迹。
具体而言,我们首先对输入图像进行DCT变换,并过滤得到其高频分量,这是基于图像中的视觉瑕疵往往存在于频域的高频段中。然后我们将原图像和其对应的高频分量分别输入到几层卷积层中进一步提取特征。最后,我们从特征图中划分出相同大小的图像块进行拼接,并最终得到了多模态图像块潜入的表示 (multimodal patch embeddings)。
2. 物体编码器
物体编码器的目的是自动学习一组中层表征,这些表征分别关注特定区域并识别这些区域是否相互一致。为此,我们利用一个可学习的参数序列作为object prototypes,并利用其与上述提到的multimodal patch embeddings之间的交叉注意力使得其建立与图像中不同区域之间的依赖关系:
其中 是可学习的映射矩阵, 和 分别是第 个block中物体表征和(多模态)图像块表征。我们 通过残差连接的形式让图像中的视觉信息inject到物体的表征中。
接下来,我们进一步通过object prototypes之间的自注意力实现不同物体之间的交互,以来建模物体层面的一致性信息。
3. 图像块解码器
物体编码器允许图像中的不同物体相互作用,以建模中层表征是否在视觉上是否一致,并关注重要的图像块。在此基础上,我们使用来自物体编码器的更新后的物体表征来进一步完善图像块表征:
通过这样交叉注意力的方式,中层不一致信息被inject到图像块表征中,从而使得图像中相应区域的特征更具有判别性。因此,通过两次交叉注意力 (object prototypes和multimodal patch embeddings互相作为key和value),我们有效地建模了被篡改图像中的物体层面的一致性信息。
然而,考虑到不同被篡改的物体尺寸上的差异、以及对像素层面伪造痕迹的捕捉,更精细粒度的一致性建模同样非常重要。为此我们提出了一个边界敏感的上下文信息提取模块,来进行图像中每一个小的图像块内的一致性建模:
其中 是一个 大小的窗口, 我们计算该窗口内中心位置的特征向量和其余每个向量的相似 度, 来衡量特征图上每个位置和周围区域的一致性。
Part III. 实验结果
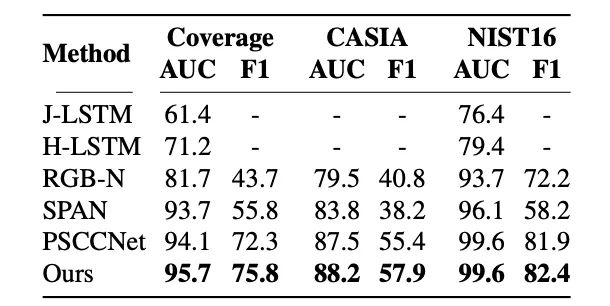
我们参考了现有的工作,利用COCO和Paris StreetView数据集合成了伪造的图像作为预训练数据,并在现有的图像篡改数据集上进行finetune,在下表中我们展示了我们的方法和现有方法的结果对比。
除了定量的比较,我们可视化预测的伪造区域mask进行了定性的比较。

Part IV. 总结
现有的图像篡改检测方法大多采用CNN的架构去捕捉图像层面或者像素层面的伪造图像,而这篇工作借助了视觉Transformer的优越性,从物体层面建模视觉不一致信息,从而为图像篡改提供了新的思路。同时,这种利用prototype去帮助学习图像区域/视觉元素的想法在物体分割、自监督学习等多个视觉任务上广泛使用,未来值得在更多的领域进行探索。
公众号后台回复“数据集”获取90+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



