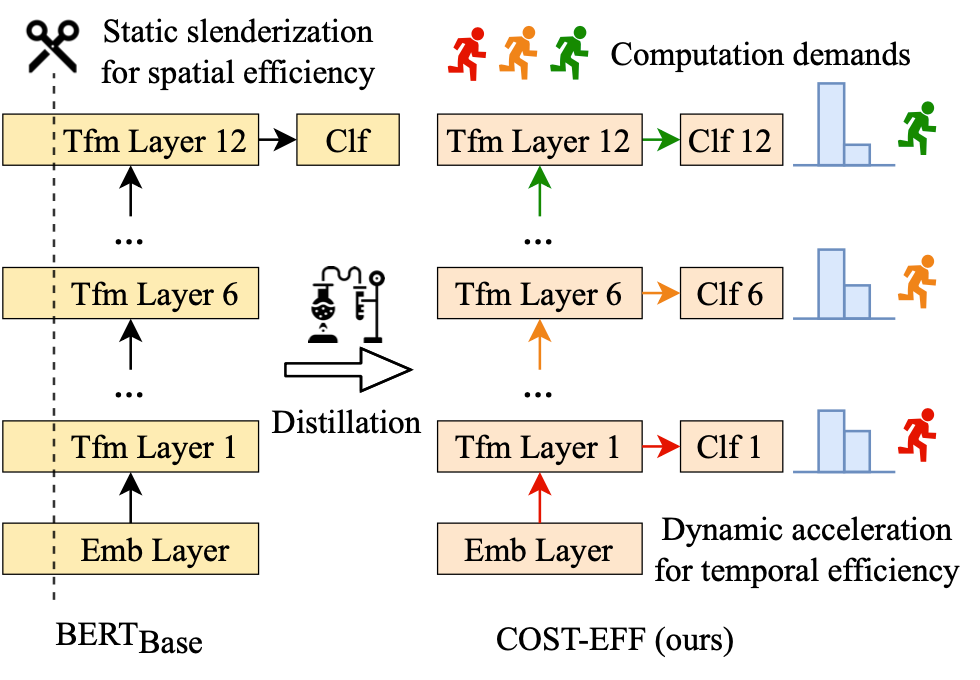
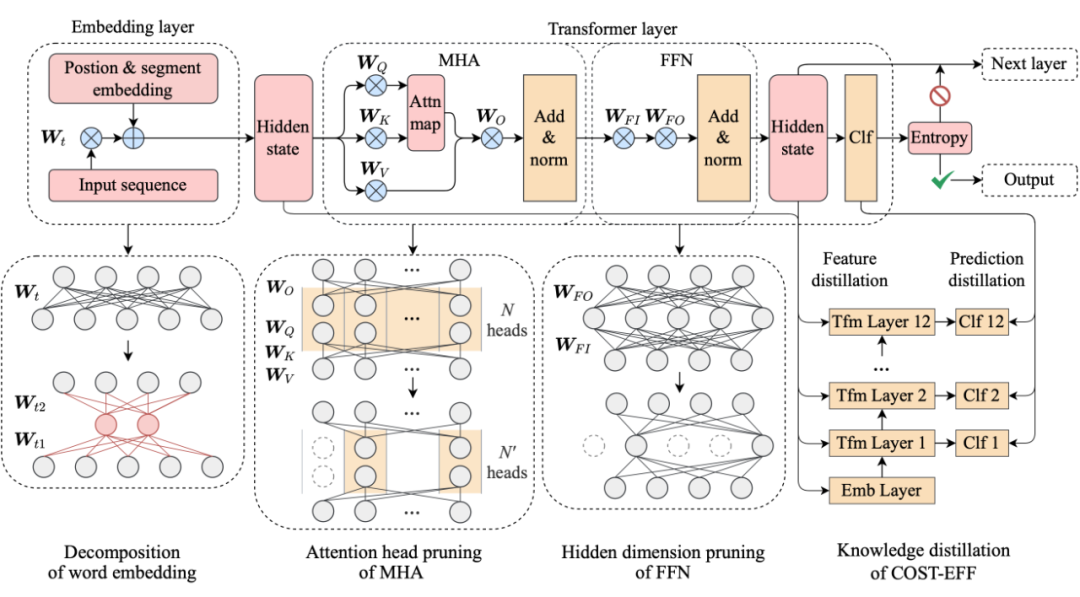
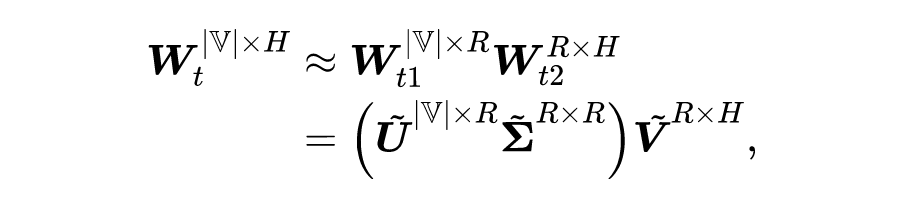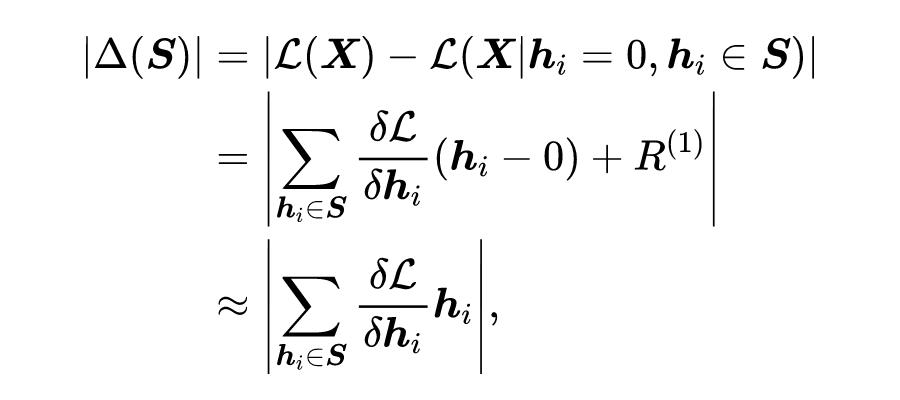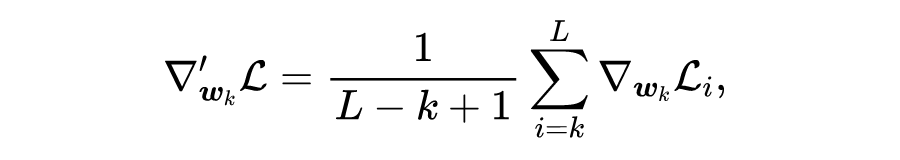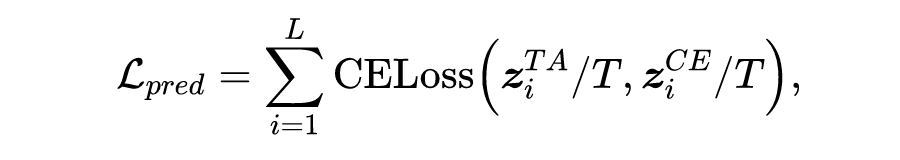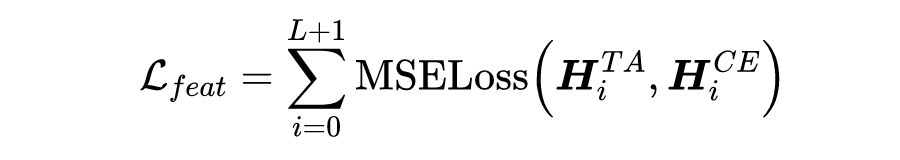COST-EFF: Collaborative Optimization of Spatial and Temporal Efficiency with Slenderized Multi-exit Language Models
收录会议:
EMNLP 2022
论文链接:
https://arxiv.org/abs/2210.15523
代码链接:
https://github.com/sbwww/cost-eff
动机
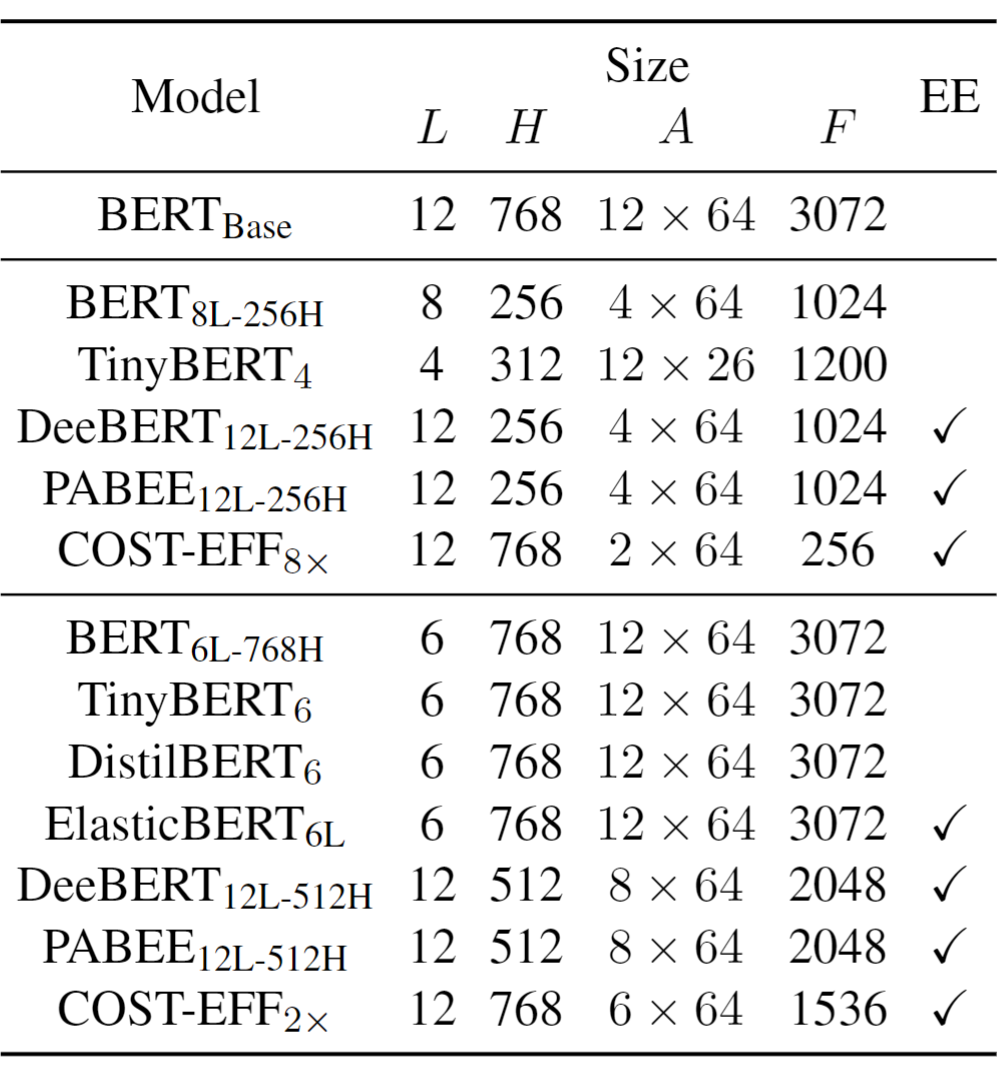
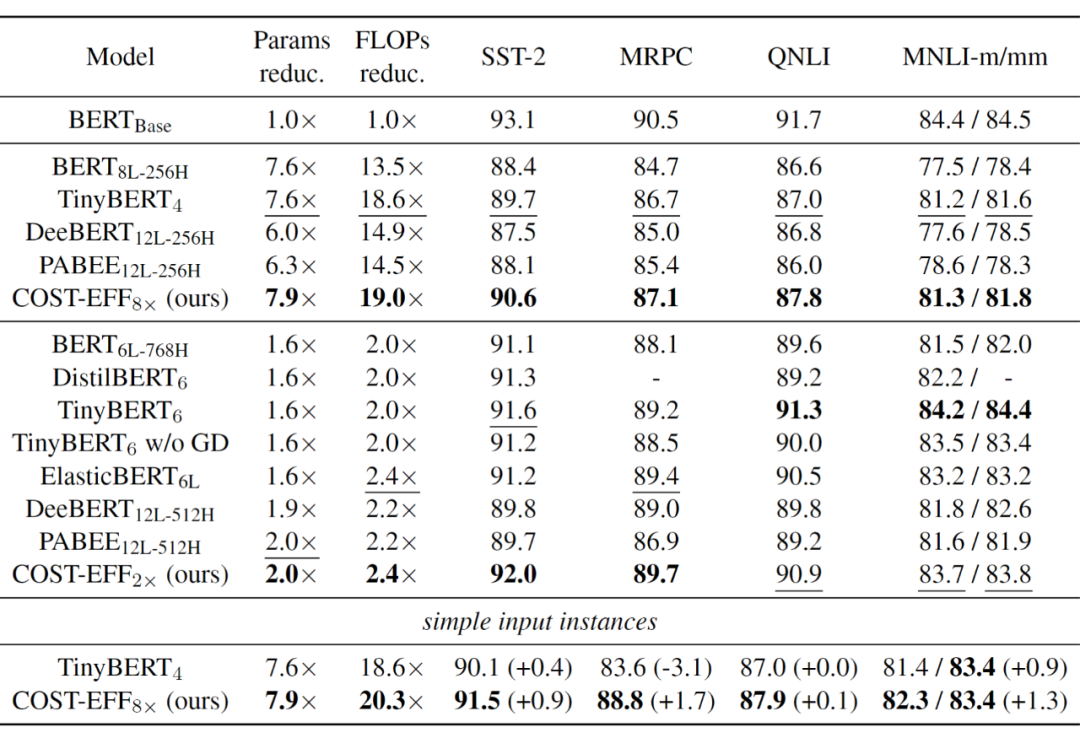
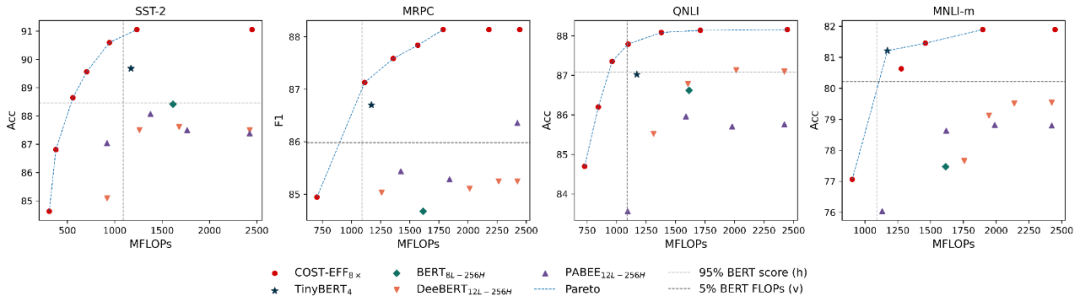
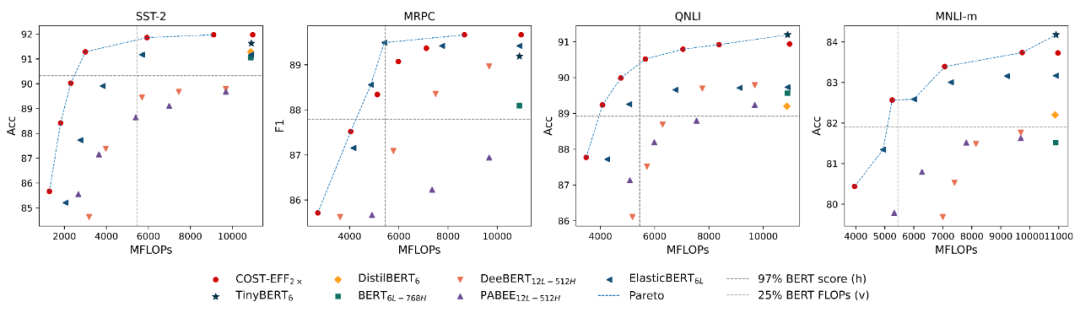
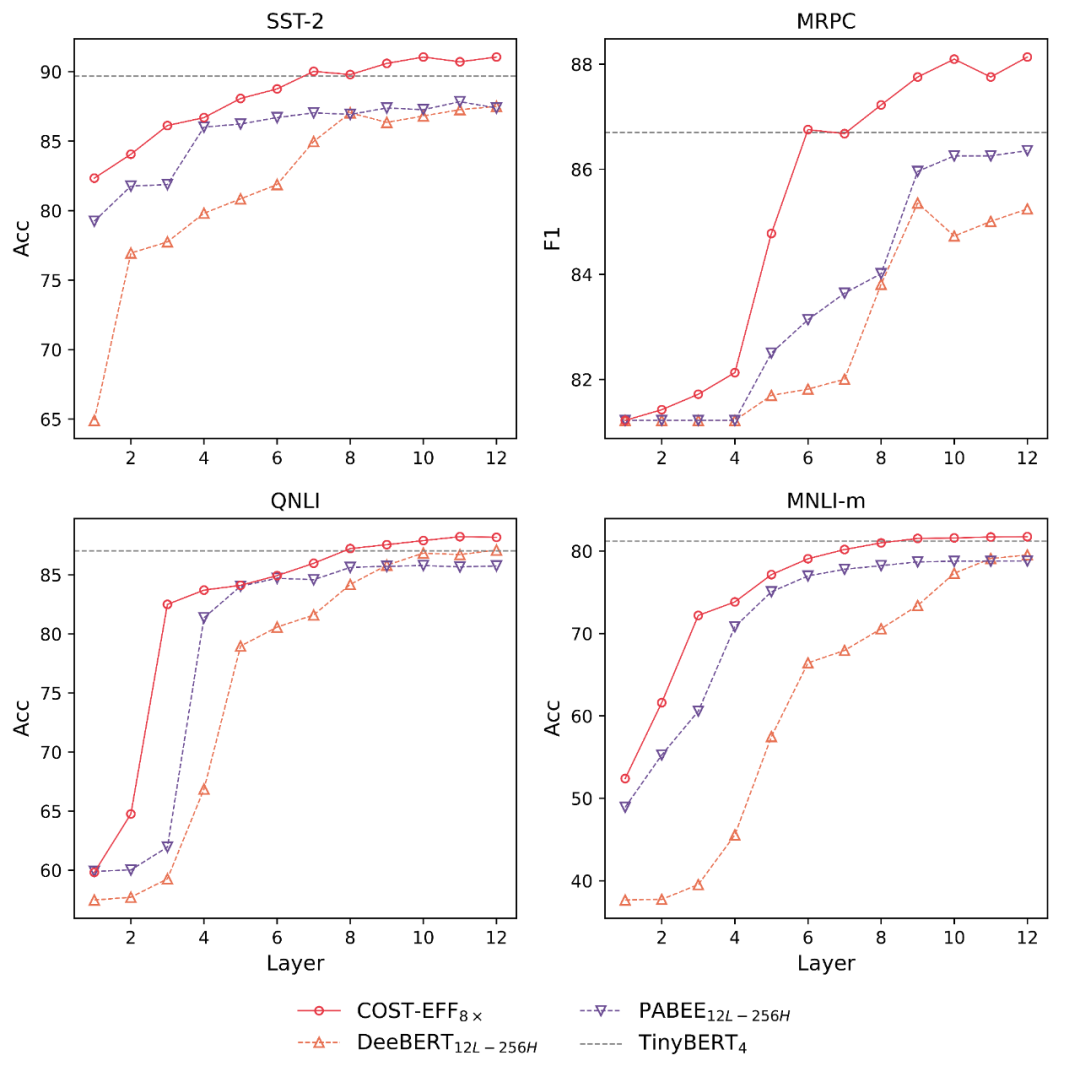
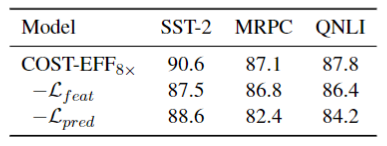
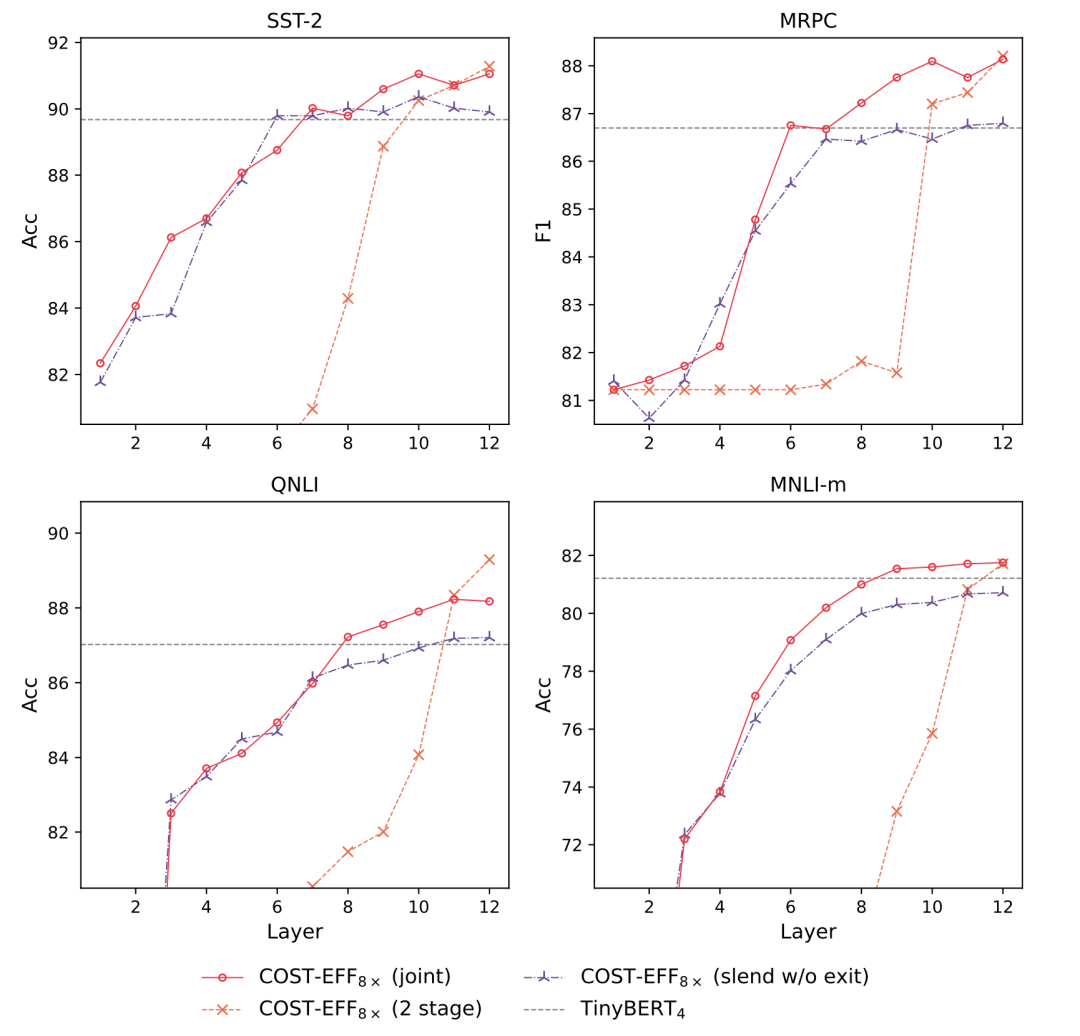
众多基于 Transformer 的预训练语言模型(Pre-trained Language Models,PLMs)不断刷新着各项任务的性能,却存在体积大、推断慢等效率问题。对于资源受限的设备和应用场景,需要一种在空间和时间上高效,且在任务推断上准确的模型。为了得到这样的模型,现有一些研究对 PLM 进行静态压缩 [1]。然而,单纯地进行静态压缩难以得到一个合适的模型,因为压缩后的模型很可能对简单样本而言仍有冗余,对复杂样本而言能力不足。为了使模型意识到输入样本的复杂性差异,Xin et al [2],Liu et al [3] 等将 PLM 修改为多出口模型(即模型的多个部位都具有输出分类器),并使用动态提前退出方法进行推断加速。我们发现,使用动态提前退出方法来加速小容量的压缩模型推断会造成较大的性能损失,其原因在于,多出口模型的浅层与深层在目标上存在不一致性。具体来说,浅层模块需兼顾做出预测和提取更深层所需的信息两个目标,而深层更多关注做出预测。这种不一致性在多出口模型中普遍存在,大容量模型有较好的能力缓解该问题,但小容量的压缩模型难以做出权衡。为了解决上述问题,我们提出了 COST-EFF 来整合静态模型压缩和动态推断加速,实现空间和时间上的协同优化。具体来说,我们1. 将 PLM 的宽度细化,而深度保持不变,保留模型提取深层知识的能力 [4]。同时,使用逐层的动态提前退出来减小模型深度带来的推断开销,根据样本复杂性动态地控制模型计算量,加速推理。
[1] [jiao2020tinybert]: Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. TinyBERT: Distilling BERT for natural language understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4163–4174, Online. Association for Computational Linguistics. [2] [xin2020deebert]: Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy Lin. 2020. DeeBERT: Dynamic early exiting for accelerating BERT inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2246–2251, Online. Association for Computational Linguistics. [3] [liu2022towards]: Xiangyang Liu, Tianxiang Sun, Junliang He, Jiawen Wu, Lingling Wu, Xinyu Zhang, Hao Jiang, Zhao Cao, Xuanjing Huang, and Xipeng Qiu. 2022. Towards efficient NLP: A standard evaluation and a strong baseline. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3288–3303, Seattle, United States. Association for Computational Linguistics. [4] [bengio2007scaling]: Yoshua Bengio, Yann LeCun, et al. 2007. Scaling learning algorithms towards ai. Large-scale kernel machines, 34(5):1–41. [5] [zhou2020bert]: Wangchunshu Zhou, Canwen Xu, Tao Ge, Julian McAuley, Ke Xu, and Furu Wei. 2020. Bert loses patience: Fast and robust inference with early exit. Advances in Neural Information Processing Systems, 33:18330–18341. [6] [li2019improved]: Hao Li, Hong Zhang, Xiaojuan Qi, Ruigang Yang, and Gao Huang. 2019. Improved techniques for training adaptive deep networks. In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 1891–1900. IEEE.[7] [wang2018glue]: Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.[8] [turc2019well]: Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Well-read students learn better: The impact of student initialization on knowledge distillation. CoRR, abs/1908.08962.[9] [sanh2019distilbert]: Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2020. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108 [cs]. ArXiv: 1910.01108.[10] [gupta2022compression]: Manish Gupta and Puneet Agrawal. 2022. Compression of deep learning models for text: A survey. ACM Transactions on Knowledge Discovery from Data (TKDD), 16(4):1–55.