预训练语言模型(PLM)是 NLP 领域的一大热门话题。从 BERT 到 GPT2 再到 XLNet,各种预训练模型层出不穷,不少同学感叹,「大佬慢点,跟不上了……」那么,这么多预训练模型要怎么学?它们之间有什么关联?为了理清这些问题,来自清华大学的两位本科同学整理了一份预训练语言模型必读论文列表,还用图的形式整理出了这些模型之间的复杂关系。
Github 项目:https://github.com/thunlp/PLMpapers
项目的两位作者——王晓智和张正彦都是清华大学的在读本科生。其中,王晓智师从清华大学计算机系教授李涓子和副教授刘知远,研究方向为 NLP 和知识图谱中的深度学习技术,于今年 4 月份入选 2019 年清华大学「未来学者」计划第二批名单;张正彦则参与过孙茂松教授指导的很多工作,如之前发布的「图神经网络必读论文列表」。此外,他还是增强版语言表征模型 ERNIE 的第一作者,并参与了多领域中文预训练模型仓库 OpenCLaP 的创建。
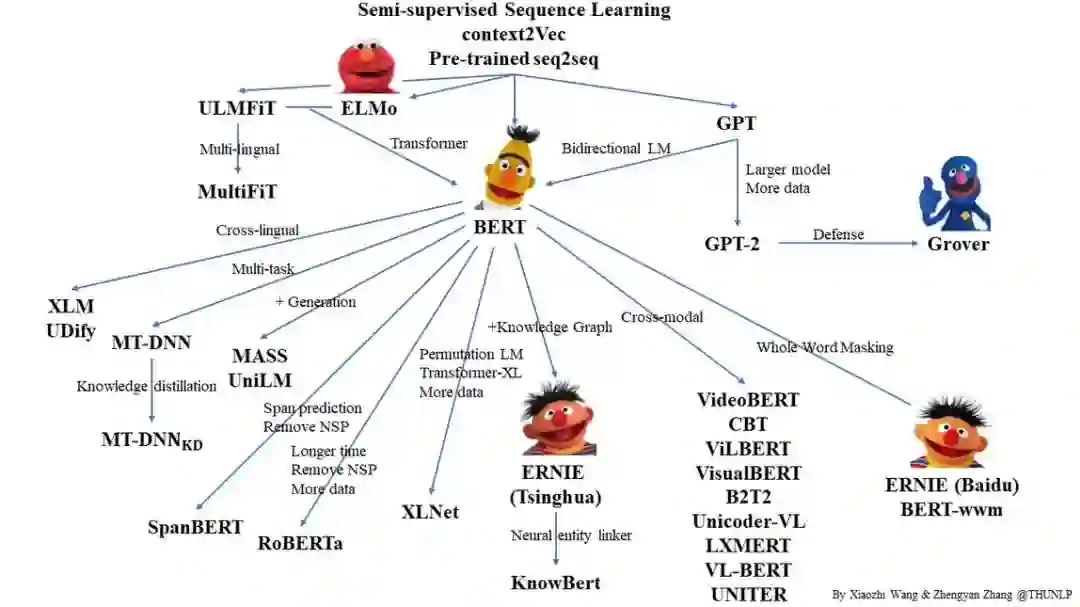
在这个预训练模型论文列表项目中,两位同学首先给出了一份预训练语言模型的关系图:
图中列出了 BERT、GPT、XLNet、ERNIE 等大家熟知的模型以及它们之间的关系。以 BERT 和清华大学提出的 ERNIE 为例,张正彦等人曾在论文中指出,BERT 等预训练语言模型只能学习语言相关的信息,学习不到「知识」相关的信息。因此他们提出用知识图谱增强 BERT 的预训练效果,让预训练语言模型也能变得「有文化」。在这张图中我们可以清楚地看到论文中阐述的这种关系,即 BERT+知识图谱→ERNIE(清华版)。这种简化版的展示对于初学者理清思路非常有帮助。
除了这张关系图,两位同学还给出了一份预训练语言模型必读论文列表。列表分为三个部分:模型、知识蒸馏与模型压缩以及相关分析论文。机器之心曾经介绍过其中的一些论文,读者可以根据链接找到相关论文中文介绍。
![]()
![]()
![]()
「知识蒸馏与模型压缩」部分包含 11 篇论文,列表如下:
![]()
![]()
![]()
![]()
参考链接:
https://github.com/thunlp/PLMpapers
华为云近期推出精编实战公开课,涵盖机器学习、大数据、运维实战等多项系列课程,由华为云资深工程师倾情讲授,完成理论学习+实践内容还有精美礼品相赠。点击
阅读原文,选择课程,免费报名。
![]()