Attention模型:我的注意力跟你们人类不一样

背景
截至今日,Badanau Attention的原文citation已达1.34w之多。2020年几乎所有主流NLP任务都需要借助attetion来实现。在深度学习全民炼丹的时代,attention是为数不多具有较强可解释性的机制。
在attention提出后的最初几年,大家都因其效果显著便不假思索地用于了自己的任务;许多paper也理所应当地在实验部分贴上各式各样的attention热图,用于解释模型的内部运作方式(例如下图)。
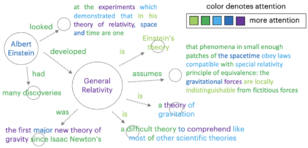
-
能够解释模型的工作原理,即可以从模型的中间结果,分析出其最终结果产生原因。 -
一种更高层次的要求是:模型具有 类似于人的工作的“思维”过程。第1种只要求模型中间结果与最终结果存在某种固定的关联,而这里则还要求该关联与人的思维过程中是相似的。确实,如果模型的脑回路与我们迥然相异的话,我们又凭什么说自己能够解释它呢?
在attention的可解释性上,此前的相关研究还是单从模型本身出发 (model-driven),也就是只停留在了第1层上。比如去年NAACL上发表的这篇《Attention is not Explanation》,他们人为构造了的新attention向量,用于替换原始向量,发现模型结果完全不变。由此,他们否认了attention的可解释性。
今天要和大家分享的这篇paper——《Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words?》,发表于ACL2020,是第一篇从人机比较的角度来讨论attention可解释性的工作。他们先请志愿者在YELP数据集上在做文本分类任务,要求志愿者标记出影响其分类结果的重点词句,作为人类attention(HAM, human attention map)。然后收集不同模型的attention(MAM, machine attention map)。并设计了一套评价指标,用于分析HAM与MAM之间的差异,给出了一些初步的insight。
这份工作最大的潜在contribution是这个HAM的数据集(已开源),YELP-HAT。它开辟了一种可能性:基于这个数据集,我们或许可以给attention添加一些supervised的控制来提高模型表现。在这方面,CV又一次走在了我们的前面。2016年时一个类似的CV方向数据,VQA-HAT,就已提出了(如下图所示)。该数据集标记了人类在做看图问答任务时的attention所在。之后有大量工作follow,研究如何通过添加supervision,使模型能够attend到关键的图片部分。
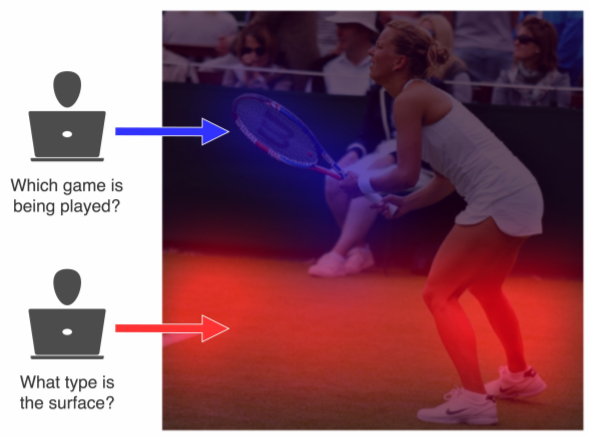
原文链接:
https://www.aclweb.org/anthology/2020.acl-main.419.pdf
数据集链接:
http://davis.wpi.edu/dsrg/PROJECTS/YELPHAT/index.html
Arxiv访问慢的小伙伴也可以在订阅号后台回复关键词【0817】下载论文PDF~
HAM vs MAM
这篇paper的思路很好把握:收集HAM数据集;生成MAM;设计HAM和MAM的比较体系;比较HAM和MAM,得出初步结论。接下来分这四个部分,为大家梳理paper内容。
收集HAM
作者团队请志愿者在YELP数据集上在做文本分类任务,要求志愿者标记出影响其分类结果的重点词句,作为HAM。每一篇文本都有三名志愿者进行重复标注。在下图中,蓝色的是两名志愿者的标注结果,红色是模型attention。可以看到,与MAM不同,人对一个词的attention非0即1的(binary)。

生成MAM
作者用三种模型跑了YELP任务,用于生成MAM。三种模型分别是:
-
RNN -
BiRNN -
Rationale mechanism,用基于规则的方式构造attention向量,旨在用supervised的方法模仿人的attention。
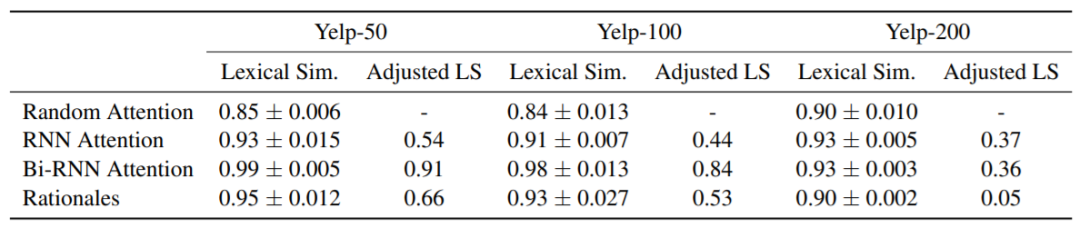
下图是三个模型和人类在YELP数据集上的表现(YELP-50/100/200是YELP数据集的三个子集,各子集中的文本平均长度依次递增)。
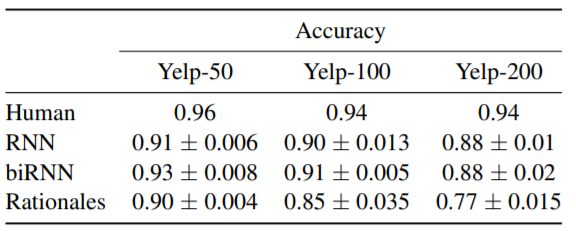
HAM与MAM的比较体系
作者设计了三个指标,从不同维度比较HAM与MAM的异同:
1. 行为相似度(Behavioral Similarity):HAM和MAM两个向量之间的AUC,比较了两者在词语选择上的异同。
2. 词性相似度(Lexical Similarity):先计算HAM和MAM所选词汇的词性分布情况,词性相似度即为两者之间的相关系数。
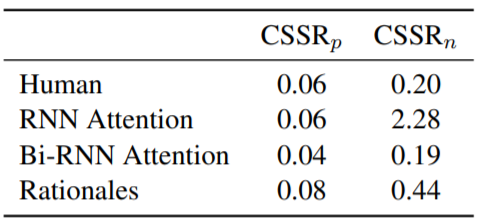
3. 情感词数量比(Context-dependency of Sentimental Polarity):这个指标的motivation源于作者发现:那些positive类的文本中也会出现negative的词汇,反之亦然。进行分类判别时,这类文本中positive和negative的词语往往都会被attend到。作者希望比较HAM和MAM所attend到的两类情感词所占比例是否相同。于是就设计了这个指标。
比较结果与初步结论
下面分别是用三个指标评估HAM和MAM间差距的实验结果(由于篇幅限制,行为相似度的实验结果只展示了部分)。
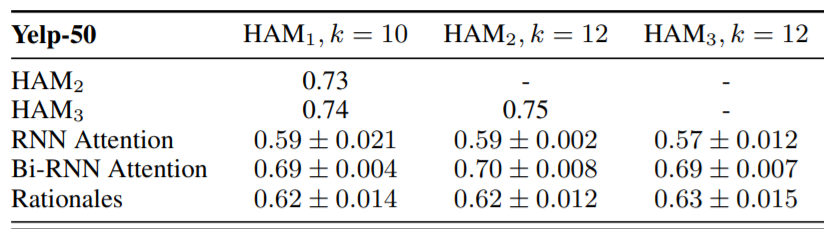
-
三种指标上,与人类attention相似度最高的都是BiRNN。 -
当文本长度增加时,人与模型的attention差异变大。 -
人与模型的attention在词性相似度上差距不大;情感词数量比上,BiRNN也非常接近人类的表现;但从行为相似度评估结果来看,人与模型的差异还是比较大的。
小结
本文从人机比较的角度,探讨了attention机制的可解释性。最大的contribution在于提出了YELP-HAT这一人类attention数据集,为attention中引入supervision提供可能。个人感觉,原文中的实验结论还是比较初步的,但不乏继续follow、深入挖掘的价值。

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





