NeurIPS-21迁移学习、元学习、自监督学习新数据集概览

极市导读
本文总结了NeurIPS 2021中有关迁移学习、预训练、自监督学习、领域自适应、元学习等相关的数据集和评测方案。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
机器学习顶级会议 「NeurIPS 2021」 今年举办了一个特殊的track: Datasets and Benchmark,其主要用于收录最新的数据集和评测方案。此track包含两轮投稿,目前第一轮投稿已结束,其接收的论文均在OpenReview平台上放出。
我们对论文进行了概览,挑选出了其中与 「迁移学习」、「预训练」、「自监督学习」、「领域自适应」、「元学习 等话题相关的数据集和评测方案,其中不乏有来自牛津大学VGG组的数据集。这几个数据集也从医学图像、对话系统、遥感图像、多模态等领域全面覆盖了当前的研究热点,值得大家用来进行更大规模的研究和评测。
所有数据集地址:
https://openreview.net/group?id=NeurIPS.cc/2021/Track/Datasets_and_Benchmarks/Round1
投稿链接:
https://neurips.cc/Conferences/2021/CallForDatasetsBenchmarks
下面是我们找出来与上述话题密切相关的几个数据集,一起来看看吧。
FHIST
-
标题:FHIST: A Benchmark for Few-shot Classification of Histological Images -
领域:医疗、肿瘤、组织学 -
任务:分类 -
模态:图像 -
用途:few-shot / transfer / meta-learning -
链接: https://openreview.net/forum?id=aAMgwCmP930
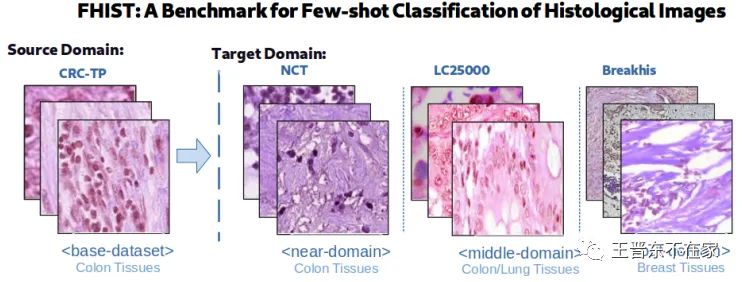
FHIST是一个由多个公开数据集组成的医学数据集,其主要是分类任务,由CRC-TP、NCT-CRC-He-100K、LC25000、BreakHis这四个公开数据集构成,其中每个公开数据集可以当做一个domain(但它们的类别彼此不同)。论文建议由数量最多的CRC-TP当做source domain,其他三个按照与其相关程度分别当做3个target domain来测试元学习和迁移学习算法,如下图所示:
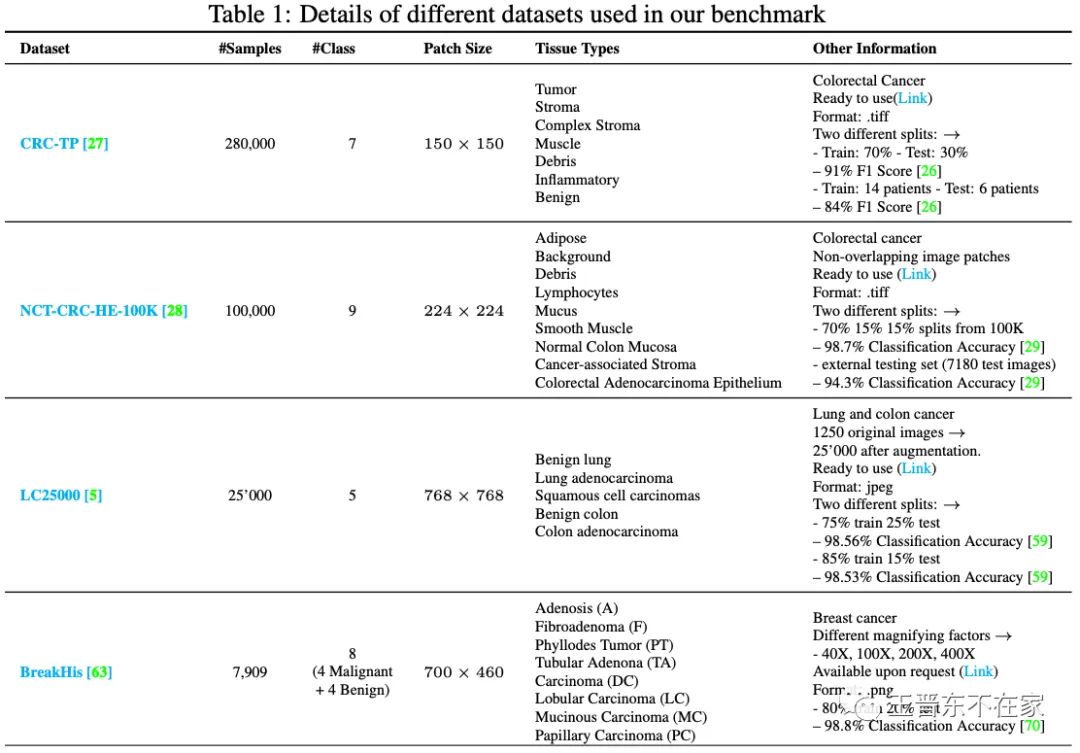
这些数据集的统计信息如下图所示:
BiToD
-
标题:A Bilingual Multi-Domain Dataset For Task-Oriented Dialogue Modeling -
领域:NLP、对话、双语 -
任务:对话生成 -
模态:文本 -
用途:预训练、跨语言迁移学习 -
链接: https://openreview.net/forum?id=dA2Q8CfmGpp
BiToD是由香港科技大学开放的一个中英文双语对话数据集,包含了Restaurant、Attraction、Metro、Weather、Hotel这5个domain,因此可以进行多领域的迁移。除此之外,该数据集也可以进行跨语言的迁移学习。下图展示了中文和英文两个语言的对话截图。

DABS
-
标题:DABS: a Domain-Agnostic Benchmark for Self-Supervised Learning -
领域:多模态 -
任务:多任务 -
模态:多模态 -
用途:自监督学习、迁移学习 -
链接: https://openreview.net/forum?id=Uk2mymgn_LZ
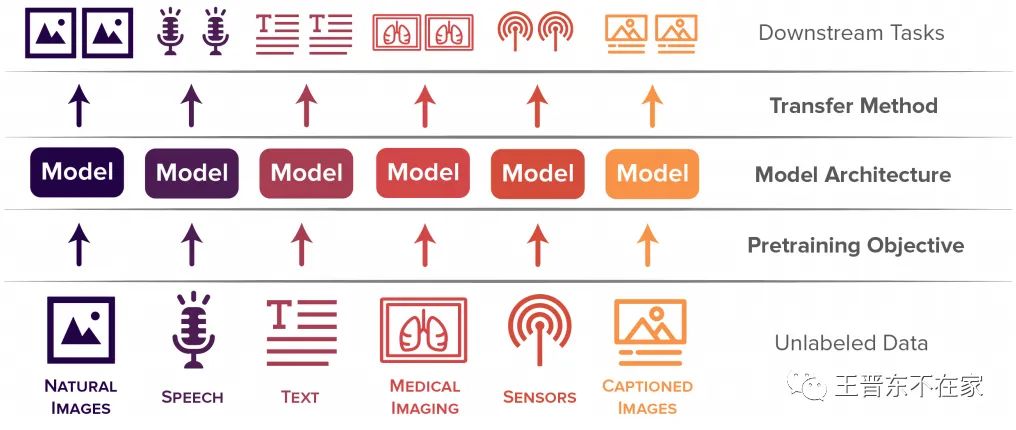
DABS是由斯坦福大学从多个数据集中收集整理的,其被用于进行领域无关(Domain-agnostic)的自监督学习。其包括6个模态的数据:自然图像、语音、文本、医学图像、传感器、带有标注的图片。该数据集要求开发的新算法必须在所有的模态上进行自监督训练,然后迁移到属于这些领域的若干个下游任务,以此来评价方法对于领域无关的数据的有效性。如下图所示。

LoveDA
-
标题:LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptation Semantic Segmentation -
领域:遥感图像 -
任务:语义分割 -
模态:图像 -
用途:迁移学习、领域自适应 -
链接: https://openreview.net/forum?id=_-O9SefMb99
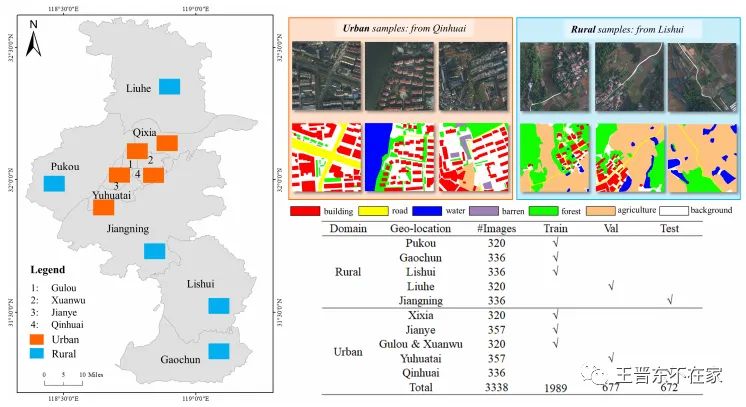
LoveDA (名字挺好)是由武汉大学开放的一个用于评价领域自适应 (Domain adaptation)算法在遥感图像上进行语义分割的数据集。它包含了7个类别、3338张图像,由来自城市和郊区的图像组成,它包含了86516个图像标注。如下图所示。
PASS
-
标题:PASS: An ImageNet replacement for self-supervised pretraining without humans -
领域:图像 -
任务:分类 -
模态:图像 -
用途:自监督学习、迁移学习 -
链接: https://openreview.net/forum?id=BwzYI-KaHdr
PASS数据集全称Pictures without humAns for Self-Supervision,来自大名鼎鼎的牛津大学VGG组。此数据是一个完全无标注的数据集,包含128万张图像。提出此数据集的原因是考虑于ImageNet的版权和隐私问题,并不是很好用。它的特点是不包括任何人和身体部位,因此排除了版权问题。此数据集用于进行自监督训练,论文中也评价了多种在此数据集上预训练的模型迁移到其他下游任务上的表现。

其他非数据集的benchmark
A Unified Few-Shot Classification Benchmark to Compare Transfer and Meta Learning Approaches
-
https://openreview.net/forum?id=Q0hm0_G1mpH -
来自Google,用于在一些已有的图像数据集上对迁移学习和元学习进行比较。
ImageNet-21K Pretraining for the Masses
-
https://openreview.net/forum?id=Zkj_VcZ6ol -
来自阿里巴巴达摩院,提供了一些通用的训练方法,使普通人能轻易地在ImageNet-21K数据上进行预训练。
A Benchmark of Medical Out of Distribution Detection
-
https://openreview.net/forum?id=oUg5rC_95OM -
来自蒙特利尔和多伦多大学,在一些公开数据集上评测了一些主流的OOD算法。
SHIFTs
-
标题:Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
-
领域:机器翻译、天气预测、自动假设汽车行动预测
-
任务:分类、回归
-
模态:图像、文本、表格数据
-
用途:few-shot / transfer / meta-learning / domain adaptation / domain generalization
-
链接:https://openreview.net/pdf?id=qM45LHaWM6E
SHIFTs是一个由3个大型数据集组成的,包含了机器翻译、天气预测、自动假设汽车行动预测这三个任务。其主要用来测试distribution shift,由俄罗斯搜索巨头Yandex发布。这三大任务均包含了大量的out-of-distribution任务,因此,在分类、预测、回归等任务上均可以用来测试模型对于不同分布数据的鲁棒性。
Yandex还财大气粗地举办了一个shifts challenge,号召大家来参加比赛刷分(已于11月7日截止)。相信在今后会有更多的好工作用shift数据集来评测。

ClimART
-
标题:ClimART: A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models
-
领域:数值模拟、地球物理、生态环境学
-
任务:环境检测
-
模态:图像
-
用途:迁移学习
-
链接:https://openreview.net/pdf?id=FZBtIpEAb5J
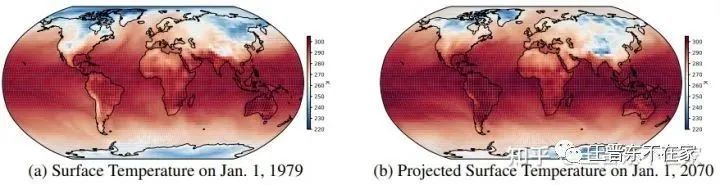
由加拿大蒙特利尔大学等学校联合发布的ClimART数据集是一个面向地球天气、气候进行模拟的数据集。该数据集收集了从1979年到2014年的气候信息,由多张截图(snapshot)以及庞大的统计信息构成,共计1.5TB。这个数据集可以进行大气环境预测等任务。同时,因为随着时间变化,环境也在一直变化,所以,该数据集提供了一个绝佳的out-of-distribution的测试环境。
FS-Mol
-
标题:FS-Mol: A Few-Shot Learning Dataset of Molecules
-
领域:分子生物学、药物发现
-
任务:分类、预测
-
模态:文本、图
-
用途:小样本学习、自监督学习、预训练、迁移学习
-
链接:https://github.com/microsoft/FS-Mol
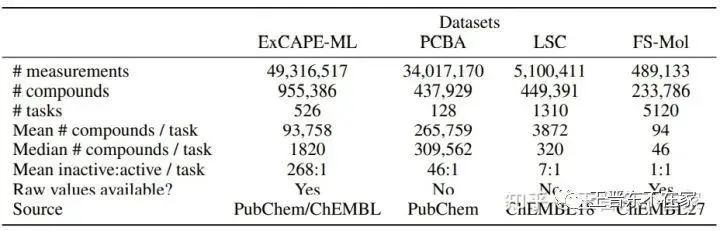
来自微软研究院等多个单位的FS-Mol数据集是一个用于为分子结构提供few-shot learning的数据集。其是通过进行小样本的迁移学习,进而可以达到药物发现(drug discovery)等目的。该数据集包含了5120次试验、233786个独特的化合物,可以进行分类、结构预测等通用的任务。除此之外,作者还提供了一个通用的benchmark,在此数据集上实现和评测了多种小样本学习算法、自监督、图算法等,为今后的研究提代了统一的平台。
LTD
-
标题:Seasons in Drift: A Long-Term Thermal Imaging Dataset for Studying Concept Drift
-
领域:热感图像
-
任务:检测
-
模态:视频、图像
-
用途:迁移学习、领域自适应
-
链接:https://openreview.net/pdf?id=LjjqegBNtPi
LTD的全称是Long-term Thermal Drift,由长达8个月热感图和视频监测构成,用于进行concept drift检测。该数据集包含了来自不同季节、时间、环境的变化图像和视频,以此来进行concept drift检测。

RAFT
-
标题:RAFT: A Real-World Few-Shot Text Classification Benchmark
-
领域:文本分类
-
任务:分类
-
模态:文本
-
用途:小样本学习、迁移学习、domain adaptation / generalization
-
链接:https://openreview.net/pdf?id=bgWHz41FMB7
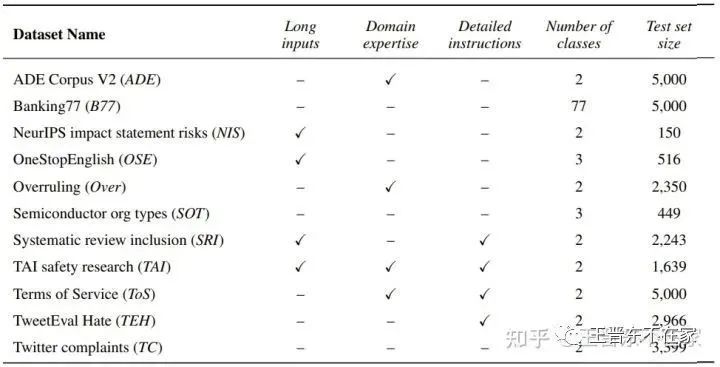
RAFT(Real-world Annotated Few-shot Tasks)用来评估大规模小样本的文本分类。其包含了众多数据集的任务:ADE、Banking77等。作者构建了一个统一的评测标准来进行跨任务、小样本的文本分类评测。
KeSpeech
-
标题:KeSpeech: An Open Source Speech Dataset of Mandarin and Its Eight Subdialects
-
领域:语音
-
任务:分类
-
模态:语音
-
用途:迁移学习、domain adaptation / generalization
-
链接:https://openreview.net/pdf?id=b3Zoeq2sCLq
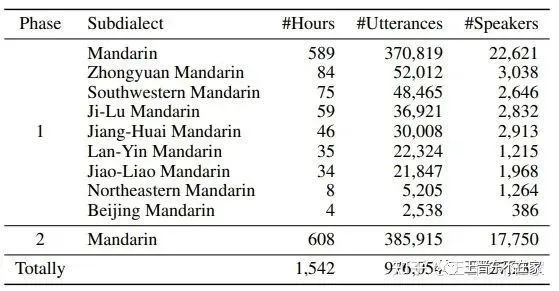
KeSpeech包含了来自27237个说话人、34个中国城市、1542个小时的普通话+8种方言的数据,用来进行跨语言语音识别、预训练等任务。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~






