梯度下降推导与优化算法的理解和Python实现

梯度下降推导与优化算法的理解和Python实现
梯度下降算法推导
优化算法的理解和Python实现
SGD
Momentum
Nestrov
AdaGrad
RMSprop
Adam
算法的表现
模型的算法就是为了通过模型学习,使得训练集的输入获得的实际输出与理想输出尽可能相近。极大似然函数的本质就是衡量在某个参数下,样本整体估计和真实情况一样的概率,交叉熵函数的本质是衡量样本预测值与真实值之间的差距,差距越大代表越不相似
1. 为什么要最小化损失函数而不是最大化模型模型正确识别的数目?
我们将不同的损失函数都定义为损失函数:

2. 如何推导梯度下降?为什么梯度下降的更新方向是梯度的负方向?
损失函数 

假设在 




最小化损失函数简而言之就是损失函数的值随着时间越来越小,可得目标函数 





如何令 

因为 
将上述过程重复多次, 


在推导了梯度下降算法,再来看各个优化算法也就不难了。引用【1】中总结的框架,首先定义:待优化参数: 


而后,开始进行迭代优化。在每个epoch 
计算目标函数关于当前参数的梯度:
根据历史梯度计算一阶动量和二阶动量:
计算当前时刻的下降梯度:
根据下降梯度进行更新:




掌握了这个框架,你可以轻轻松松设计自己的优化算法。步骤3、4对于各个算法都是一致的,主要的差别就体现在1和2上。
注:下面的内容大部分取自引用【2】和【3】
随机梯度下降法不用多说,每一个参数按照梯度的方向来减小以追求最小化损失函数,梯度下降法目前主要分为三种方法,区别在于每次参数更新时计算的样本数据量不同:批量梯度下降法(BGD, Batch Gradient Descent),随机梯度下降法(SGD, Stochastic Gradient Descent)及小批量梯度下降法(Mini-batch Gradient Descent)。
选择合适的learning rate比较困难 ,学习率太低会收敛缓慢,学习率过高会使收敛时的波动过大
所有参数都是用同样的learning rate
SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点
更新方式
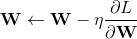
Python实现
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]在梯度下降的基础上加入了动量,动量优化方法引入物理学中的动量思想:当我们将一个小球从山上滚下来,没有阻力时,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。momentum算法思想:参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来加速当前的梯度。下面的式子中, 
更新方式
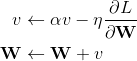
Python实现
class Momentum:
def __init__(self, lr=0.01, momemtum=0.9):
self.lr = lr
self.momemtum = momemtum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momemtum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]Nestrov也是一种动量更新的方式,但是与普通动量方式不同的是,Nestrov为了加速收敛,提前按照之前的动量走了一步,然后求导后按梯度再走一步。
更新方式
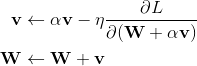
但是这样一来,就给实现带来了很大的麻烦,因为我们当前是在W的位置上,无法求得W+αv处的梯度,所以我们要进行一定改变。由于W与W+αv对参数来说没有什么区别,所以我们可以假设当前的参数就是W+αv。就像下图,按照Nestrov的本意,在0处应该先按照棕色的箭头走αv到1,然后求得1处的梯度,按照梯度走一步到2。
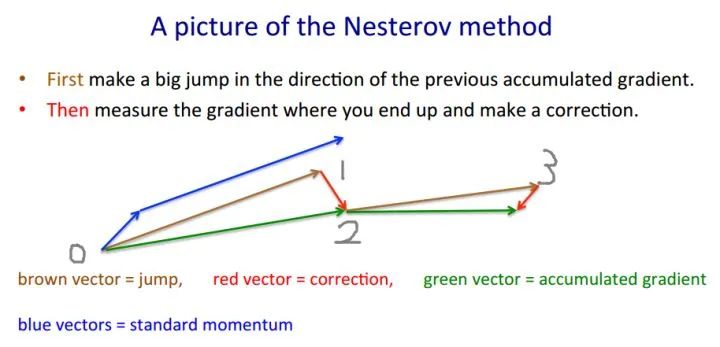
现在,我们假设当前的W就是1处的参数,但是,当前的动量v仍然是0处的动量,那么更新方式就可以写作:
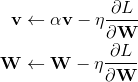
为了便于理解, W和v的更新可以看做是 空间中向量相加 的方式,这样一来,动量v就由0处的动量更新到了下一步的2处的动量。但是下一轮的W相应的应该在3处,所以W还要再走一步αv,即完整的更新过程应该如下所示:
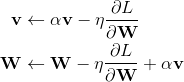
第二行的v是第一行更新的结果,为了统一v的表示,更新过程还可以写作:
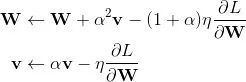
Python实现
class Nestrov:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.momentum * self.v[key] - self.lr * grads[key]但是根据我看到的各个框架的代码,它们好像都把动量延迟更新了一步,所以实现起来有点不一样(或者说是上下两个式子的顺序进行了颠倒),我也找不到好的解释,但是在MNIST数据集上最终的结果要好于原来的实现。
Python实现
class Nestrov:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]前面介绍了几种动量法,动量法旨在通过每个参数在之前的迭代中的梯度,来改变当前位置参数的梯度,在梯度稳定的地方能够加速更新的速度,在梯度不稳定的地方能够稳定梯度。
而AdaGrad则是一种完全不同的思路,它是一种自适应优化算法。它通过每个参数的历史梯度,动态更新每一个参数的学习率,使得每个参数的更新率都能够逐渐减小。前期梯度加大的,学习率减小得更快,梯度小的,学习率减小得更慢些。
Adagrad缺点
仍需要手工设置一个全局学习率
, 如果
设置过大的话,会使regularizer过于敏感,对梯度的调节太大
中后期,分母上梯度累加的平方和会越来越大,使得参数更新量趋近于0,使得训练提前结束,无法学习
 , 如果
, 如果 更新方式
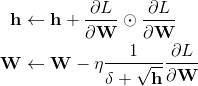
其中δ用于防止除零错
Python实现
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)AdaGrad有个问题,那就是学习率会不断地衰退。这样就会使得很多任务在达到最优解之前学习率就已经过量减小,所以RMSprop采用了使用指数衰减平均来慢慢丢弃先前的梯度历史。这样一来就能够防止学习率过早地减小。
RMSprop特点
其实RMSprop依然依赖于全局学习率
RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
适合处理非平稳目标——对于RNN效果很好
更新方式:
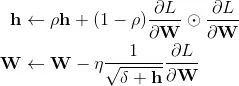
Python实现
class RMSprop:
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)Adam方法结合了上述的动量(Momentum)和自适应(Adaptive),同时对梯度和学习率进行动态调整。如果说动量相当于给优化过程增加了惯性,那么自适应过程就像是给优化过程加入了阻力。速度越快,阻力也会越大。
Adam首先计算了梯度的一阶矩估计和二阶矩估计,分别代表了原来的动量和自适应部分
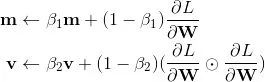
β_1 与 β_2 是两个特有的超参数,一般设为0.9和0.999。
但是,Adam还需要对计算出的矩估计进行修正
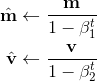
其中t是迭代的次数,修正的原因在

这个问题中有非常详细的解释。简单来说就是由于m和v的初始值为0,所以第一轮的时候会非常偏向第二项,那么在后面计算更新值的时候根据β_1 与 β_2的初始值来看就会非常的大,需要将其修正回来。而且由于β_1 与 β_2很接近于1,所以如果不修正,对于最初的几轮迭代会有很严重的影响。
最后就是更新参数值,和AdaGrad几乎一样,只不过是用上了上面计算过的修正的矩估计
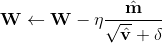
Adam特点
Adam梯度经过偏置校正后,每一次迭代学习率都有一个固定范围,使得参数比较平稳。
结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
为不同的参数计算不同的自适应学习率
也适用于大多非凸优化问题——适用于大数据集和高维空间。
为了使得Python实现更加简洁,将修正矩估计代入原式子,也就是重新表达成只关于m和v的函数,修改如下




python实现
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)各个算法在等高线的表现,它们都从相同的点出发,走不同的路线达到最小值点。可以看到,Adagrad,Adadelta和RMSprop在正确的方向上很快地转移方向,并且快速地收敛,然而Momentum和NAG先被领到一个偏远的地方,然后才确定正确的方向,NAG比momentum率先更正方向。SGD则是缓缓地朝着最小值点前进。
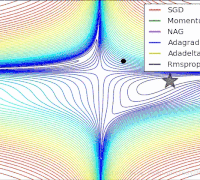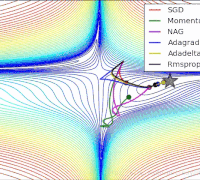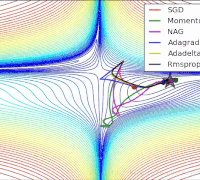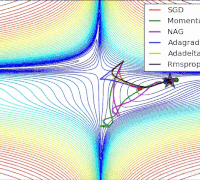
Juliuszh:一个框架看懂优化算法之异同 SGD/AdaGrad/Adam
深度学习中的优化算法(Optimizer)理解与python实现
优化算法Optimizer比较和总结
推荐阅读
抛开模型,探究文本自动摘要的本质——ACL2019 论文佳作研读系列
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




