深度学习优化算法总结(SGD,AdaGrad,Adam等)
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 |刘浪
原文 | https://zhuanlan.zhihu.com/p/61955391
动量(Momentum)算法
带动量的 SGD
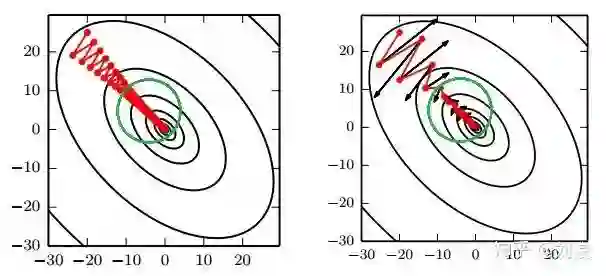
引入动量(Momentum)方法一方面是为了解决“峡谷”和“鞍点”问题;一方面也可以用于SGD 加速,特别是针对高曲率、小幅但是方向一致的梯度。
如果把原始的 SGD 想象成一个纸团在重力作用向下滚动,由于质量小受到山壁弹力的干扰大,导致来回震荡;或者在鞍点处因为质量小速度很快减为 0,导致无法离开这块平地。
动量方法相当于把纸团换成了铁球;不容易受到外力的干扰,轨迹更加稳定;同时因为在鞍点处因为惯性的作用,更有可能离开平地。
动量方法以一种廉价的方式模拟了二阶梯度(牛顿法)
参数更新公式


从形式上看, 动量算法引入了变量 v 充当速度角色,以及相相关的超参数 α(0.9)。
原始 SGD 每次更新的步长只是梯度乘以学习率;现在,步长还取决于历史梯度序列的大小和排列;当许多连续的梯度指向相同的方向时,步长会被不断增大;
动量算法描述

如果动量算法总是观测到梯度 g,那么它会在 −g 方向上不断加速,直到达到最终速度。
在实践中, α 的一般取 0.5, 0.9, 0.99,分别对应最大2 倍、10 倍、100 倍的步长
和学习率一样,α 也可以使用某种策略在训练时进行自适应调整;一般初始值是一个较小的值,随后会慢慢变大。自适应学习率的优化方法

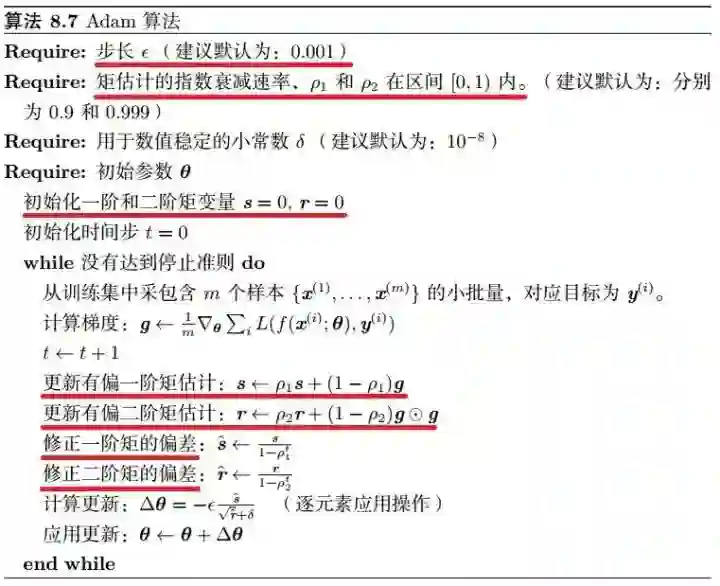
NAG 算法(Nesterov 动量)
NAG 把梯度计算放在对参数施加当前速度之后。
这个“提前量”的设计让算法有了对前方环境“预判”的能力。Nesterov 动量可以解释为往标准动量方法中添加了一个修正因子。
NAG 算法描述

自适应学习率的优化算法
AdaGrad
该算法的思想是独立地适应模型的每个参数:具有较大偏导的参数相应有一个较大的学习率,而具有小偏导的参数则对应一个较小的学习率
具体来说,每个参数的学习率会缩放各参数反比于其历史梯度平方值总和的平方根
AdaGrad 算法描述

注意:全局学习率 ϵ 并没有更新,而是每次应用时被缩放
AdaGrad 存在的问题
学习率是单调递减的,训练后期学习率过小会导致训练困难,甚至提前结束
需要设置一个全局的初始学习率
RMSProp
RMSProp 主要是为了解决 AdaGrad 方法中学习率过度衰减的问题—— AdaGrad 根据平方梯度的整个历史来收缩学习率,可能使得学习率在达到局部最小值之前就变得太小而难以继续训练;
RMSProp 使用指数衰减平均(递归定义)以丢弃遥远的历史,使其能够在找到某个“凸”结构后快速收敛;此外,RMSProp 还加入了一个超参数 ρ 用于控制衰减速率。
具体来说(对比 AdaGrad 的算法描述),即修改 r 为
记
则
其中 E 表示期望,即平均;δ 为平滑项,具体为一个小常数,一般取 1e-8 ~ 1e-10(Tensorflow 中的默认值为 1e-10)



RMSProp 建议的初始值:全局学习率 ϵ=1e-3,衰减速率 ρ=0.9
RMSProp 算法描述

带 Nesterov 动量的 RMSProp

经验上,RMSProp 已被证明是一种有效且实用的深度神经网络优化算法。
RMSProp 依然需要设置一个全局学习率,同时又多了一个超参数(推荐了默认值)。
Adam
Adam 在 RMSProp 方法的基础上更进一步:
除了加入历史梯度平方的指数衰减平均(r)外,
还保留了历史梯度的指数衰减平均(s),相当于动量。
Adam 行为就像一个带有摩擦力的小球,在误差面上倾向于平坦的极小值。
Adam 算法描述
偏差修正
注意到,s 和 r 需要初始化为 0;且 ρ1 和 ρ2 推荐的初始值都很接近 1(0.9 和 0.999)
这将导致在训练初期 s 和 r 都很小(偏向于 0),从而训练缓慢。
因此,Adam 通过修正偏差来抵消这个倾向。
*延伸阅读
图像分类算法优化技巧:Bag of Tricks for Image Classification
行人重识别算法优化技巧:Bags of Tricks and A Strong Baseline
不要只关心怎么优化模型,这不是机器学习的全部
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~


