机器学习(7)之感知机python实现
微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第二
【Python】:排名第三
【算法】:排名第四
感知器PLA是一种最简单,最基本的线性分类算法(二分类)。其前提是数据本身是线性可分的。
模型可以定义为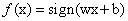
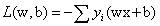
算法选择,最终的目标是求损失函数的最小值,利用机器学习中最常用的梯度下降GD或者随机梯度下降SGD来求解。
SGD算法的流程如下:输入训练集和学习率
1、初始化w0,b0,确定初始化超平面,并确定各样例点是否正确分类(利用yi和wx+b的正负性关系);
2、随机在误分类点中选择一个样例点,计算L关于w和b在该点处的梯度值;
3、更新w,b,按照如下方向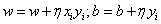
4、迭代运行,直到满足停止条件(限定迭代次数或者定义可接受误差最大值);
如上所述,初值的选择,误分类点的选择顺序都影响算法的性能和运行时间。PLA是一个很基本的算法,应用场景很受限,只是作为一个引子来了解机器学习,后面有很多高级的算法,比如SVM和MLP,以及大热的deep learning,都是感知器的扩展。
对于PLA,还有一个对偶问题,此处,简单介绍一下对偶问题相关的知识。
对偶问题:
每一个线性规划问题,我们称之为原始问题,都有一个与之对应的线性规划问题我们称之为对偶问题。原始问题与对偶问题的解是对应的,得出一个问题的解,另一个问题的解也就得到了。并且原始问题与对偶问题在形式上存在很简单的对应关系:目标函数对原始问题是极大化,对对偶问题则是极小化。原始问题目标函数中的收益系数(优化函数中变量前面的系数)是对偶问题约束不等式中的右端常数,而原始问题约束不等式中的右端常数则是对偶问题中目标函数的收益系数;原始问题和对偶问题的约束不等式的符号方向相反;原始问题约束不等式系数矩阵转置后即为对偶问题的约束不等式的系数矩阵;原始问题的约束方程数对应于对偶问题的变量数,而原始问题的变量数对应于对偶问题的约束方程数;对偶问题的对偶问题是原始问题。总之他们存在着简单的矩阵转置,系数变换的关系。当问题通过对偶变换后经常会呈现许多便利,如约束条件变少、优化变量变少,使得问题的求解证明更加方便计算可能更加方便。
对偶问题中,此处将w和b看成是x和y的函数,w和b可表示为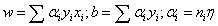
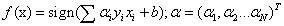
1、
2、随机选取误分类点对,并更新计算
3、直至没有误分类点,停止计算,返回相应的参数;
原始问题和对偶问题都是严格可收敛的,在线性可分的条件下,一定可以停止算法运行,会达到结果,存在多个解。
如果线性不可分,可以利用口袋算法,每次迭代更新错误最小的权值,且规定迭代次数。口袋算法基于贪心的思想。他总是让遇到的最好的线拿在自己的手上。。。 就是我首先手里有一条分割线wt,发现他在数据点(xn,yn)上面犯了错误,那我们就纠正这个分割线得到wt+1,我们然后让wt与wt+1遍历所有的数据,看哪条线犯的错误少。如果wt+1犯的错误少,那么就让wt+1替代wt,否则wt不变。 那怎样让算法停下来呢??——–我们就 自己规定迭代的次数 由于口袋算法得到的线越来越好(PLA就不一定了,PLA是最终结果最好,其他情况就说不准了),所以我们就 自己规定迭代的次数 。
感知机python实现代码

招募 志愿者
广告、商业合作
请发邮件:357062955@qq.com

喜欢,别忘关注~
帮助你在AI领域更好的发展,期待与你相遇!



