Facebook AI 近日开源了多语言机器翻译模型 M2M-100,该模型不依赖以英语为中心的数据,可以实现 100 种语言之间的相互翻译。
![]()
机器翻译(MT)打破了人类之间的语言障碍。如今,平均每天需要在 Facebook 新闻提要上提供 200 亿次翻译,这得益于低资源机器翻译领域的发展以及评估翻译质量的最新进展。
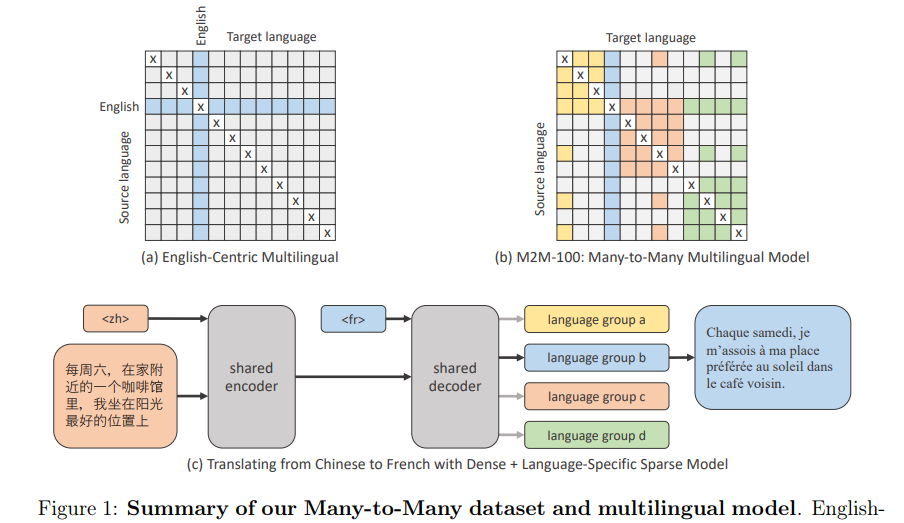
典型的 MT 系统需要为每种语言和每种任务构建单独的 AI 模型,但这种方法无法在 Facebook 上进行有效推广,因为人们在数十亿个帖子中发布超过 160 种语言的内容。先进的多语言处理系统能够同时处理多种语言,但由于依赖英语数据来弥合源语言和目标语言之间的差距,在准确性上会有所折中。
因此,我们需要一种可以翻译任何语言的多语言机器翻译(multilingual machine translation, MMT)模型,从而更好地服务于全球近三分之二不使用英语的人们。
近日,Facebook 根据多年对 MT 的研究宣布实现了一个重要的里程碑:
首个单一的大规模 MMT 模型,该模型可以实现 100x100 个语言对的直接翻译,而不依赖以英语为中心的数据
。这个单一的多语言模型表现得和传统双语模型一样好,并且比以英语为中心的多语言模型提高了 10 个 BLEU 点。
具体而言,通过使用新的挖掘策略来创建翻译数据,该研究构建了首个真正的多对多数据集。该数据集拥有 100 种语言的 75 亿个句子。研究者使用可扩展技术来建立具有 150 亿个参数的通用模型,它从相关语言中捕获信息,并反映出更加多样化的语言文字和词法。目前,这项研究已经开源。
![]()
构建多对多 MMT 模型的最大障碍之一是:在任意方向翻译大量的高质量句子对(也称为平行句),而不需要涉及英语。从中文到英文、从英文到法文的翻译要比从法文到中文容易得多。更重要的是,模型训练所需的数据量会随着语言数量的增加而呈二次增长。例如,如果每个方向需要 10M 句子对,我们需要挖掘 10 种语言的 1B 句子对和 100 种语言的 100B 句子对。
该研究建立了多样化的多对多 MMT 数据集:跨越 100 种语言的 75 亿句子对。通过结合互补的数据挖掘资源:ccAligned、ccMatrix 以及 LASER。此外该研究还创建了一个新的 LASER 2.0 并改进了 fastText 语言识别,提高了挖掘质量,并开放了源代码的训练和评估脚本。所有的数据挖掘资源都利用公开数据集,并且都是开源的。
![]()
尽管如此,即使使用了像 LASER 2.0 这样先进的底层技术,为 100 种不同语言的任意对(或是 4450 种可能的语言对)挖掘大规模训练数据仍然需要大量的计算。为了使这种数据挖掘规模更容易管理,该研究首先关注翻译请求最多的语言。因此,以最高质量的数据和最大数量的数据为优先挖掘方向。该研究避开了在统计上很少需要翻译的方向,比如冰岛语到尼泊尔语翻译,或者是僧伽罗语到爪哇语的翻译。
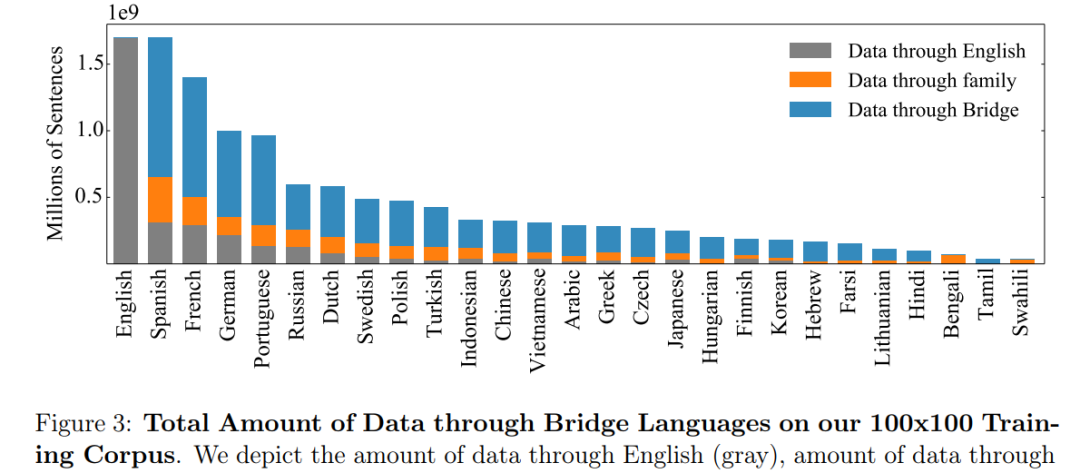
接着,研究者提出了一种新的桥梁挖掘(bridge mining)策略,其中按照语言分类、地域和文化相似性将 100 种语言分成了 14 个语系。这样做是因为,同一个语系中的人(包含多种语言)往往交流更频繁,并将从高质量翻译中收益。举例而言,一个语系中将涵盖印度境内使用的孟加拉语、印地语、马拉地语、尼泊尔语、泰米尔语和乌尔都语等多种语言。研究者系统性地挖掘每个语系中所有可能的语言对。
为了连通不同语系的语言,研究者确定了少量的桥梁语言(bridge language),它们通常由每个语系中的 1 至 3 种主要语言构成。如上述印度境内所使用的语言中,印地语、孟加拉语和泰米尔语是雅利安语的桥梁语言。然后,研究者挖掘这些桥梁语言所有可能组合的并行训练数据。通过这种方法,训练数据集最终生成了 75 亿个并行句子,对应 2200 个语言方向(direction)。
由于挖掘的数据可以用来训练给定语言对的两个不同方向,如 en→fr 和 fr→en,因此挖掘策略有助于实现高效、稀疏地挖掘,从而以最佳的状态覆盖一个模型中的所有 100×100(共计 9900)个方向。
![]()
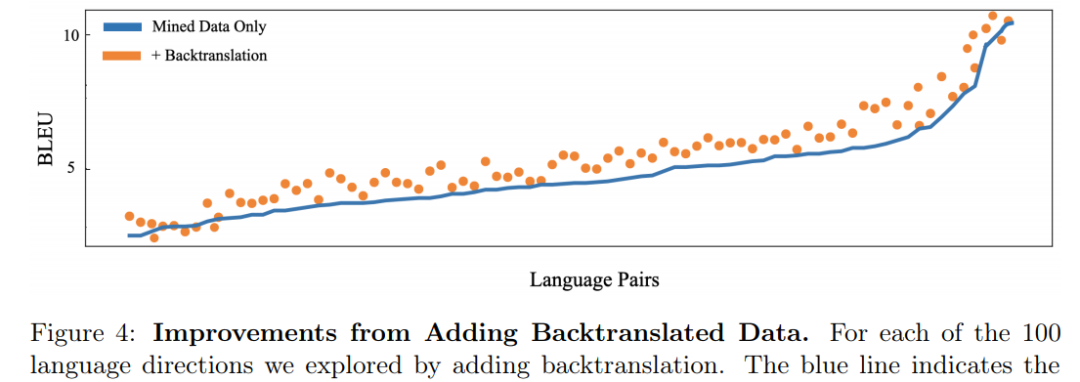
为了对低翻译质量的语料匮乏语言补充并行数据,研究者使用了反向翻译(back-translation)策略。举例而言,如果想要训练一个汉语 - 法语翻译模型,则应该首先训练一个法语到汉语的模型,并翻译所有的单一法语数据以创建合成的反向翻译汉语。研究者发现,反向翻译策略在大规模语言转换中特别有效,比如将亿万个单语句子转换为并行数据集。
具体而言,研究者使用反向翻译策略作为已经挖掘语言对方向训练的补充,将合成反向翻译数据添加到挖掘的并行数据中。此外,研究者还使用反向翻译策略为以往无人监督的语言对方向创建数据。
![]()
仅挖掘数据 VS 反向翻译策略加持形成的语言对比较。
总的来说,与单靠挖掘数据上的训练相比,桥梁策略和反向翻译数据的结合将 100 个反向翻译方向上的性能提升了 1.7BLEU。有了鲁棒性更强、高效和高质量的数据集,这就为构建和扩展多对多(many-to-many)语言模型打下了坚实基础。
在语言对无可用训练数据的零样本设置下,研究者也发现了令人印象深刻的结果。举例而言,如果一个模型在法语 - 英语和德语 - 瑞典语语料库中进行训练,则可以实现法语和瑞典语的零样本转译。在多对多模型必须实现非英语方向之间零样本转译的设置下,则该模型要比以英语为中心的多语言模型好得多。
![]()
多对多和以英语为中心语言模型的比较。在包含英语的评估方向上,多对多模型与以英语为中心模型的性能相当,但在非英语方向上的性能要好得多。
高速度高质量地将 MMT 模型扩展到 150 亿个参数
多语言翻译中的一个挑战是:单一模型必须从多种不同语言和多种脚本中捕获信息。为了解决这个问题,研究者发现扩展模型容量并添加特定于语言的参数的显著优势。扩展模型大小对于高资源语言对尤其有用,因为它们具有训练额外模型容量的大部分数据。
最终,当将模型规模密集扩展到 120 亿个参数时,研究者在所有语言方向上平均获得了 1.2BLEU 的平均提升。此后,进一步密集扩展所带来的回报逐渐减少。密集扩展和特定于语言的稀疏参数(32 亿个)的组合使得能够创建一个具有 150 亿个参数的更优模型。
![]()
研究者将其模型与双语基准和以英语为中心的多语言模型进行比较。研究者从具有 24 个编码器层和 24 个解码器层的 12 亿个参数基线开始,然后将以英语为中心的模型与 M2M-100 模型进行比较。接下来,如果将 12B 参数与 12 亿个参数进行比较,将获得 1.2BLEU 的提高。
为了扩展模型的大小,研究者增加了 Transformer 网络中的层数以及每层的宽度。研究者发现大型模型收敛迅速并且训练高效。值得注意的是,这是第一个利用 Fairscale(一个新的专门设计用于支持管道和张量并行性的 PyTorch 库)的多对多系统。
研究者建立了通用的基础架构,以通过将模型并行到 Fairscale 中来容纳无法在单个 GPU 上安装的大型模型,并且是基于 ZeRO 优化器、层内模型并行性和管道模型并行性构建的,以训练大型模型。
但是仅将模型扩展到数十亿个参数还不够。为了能够将此模型应用于生产,需要以高速训练尽可能高效地扩展模型。例如,许多现有研究使用多模型集成,其中训练了多个模型并将其用于同一个源句以生成翻译。为了降低训练多个模型所需的复杂度和计算量,研究者探索了多源自集成技术,该技术可将源句子翻译成多种语言以提升翻译质量。此外,研究者还在该研究中引入了 LayerDrop 和 Depth-Adaptive,以用常规主干和一些语言特定参数集来共同训练模型。
这种方法对于多对多模型非常有效,因为它提供了一种按照语言对或语言族来拆分模型的自然方法。通过将模型容量的密集扩展与特定于语言的参数结合,该研究提供了大型模型的优势以及学习不同语言的特定层的能力。
研究者表示,他们将继续通过整合此类前沿研究来提升模型,探索方法以负责任地部署 MT 系统,并创建更专业的计算架构将模型投入实际使用。
原文链接:https://ai.facebook.com/blog/introducing-many-to-many-multilingual-machine-translation/
近日,华为推出了MindSpore深度学习实战营,帮助小白更快的上手高性能深度学习框架。
扫描下图二维码,关注MindSpore公众号回复「21天实战」即可获取报名方式!也可添加小助手微信:mindspore0328,备注21,完成报名。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com