机器翻译新时代:Facebook 开源无监督机器翻译模型和大规模训练语料
【导读】基于深度学习的机器翻译往往需要数量非常庞大的平行语料,这一前提使得当前最先进的技术无法被有效地用于那些平行语料比较匮乏的语言之间。为了解决这一问题,Facebook提出了一种不需要任何平行语料的机器翻译模型。该模型的基本思想是, 通过将来自不同语言的句子映射到同一个隐空间下来进行句子翻译。近日,Facebook开源了这一翻译模型MUSE: Multilingual Unsupervised and Supervised Embeddings,并提供预训练好的30种语言的词向量和110个大规模双语词典。

▌主要流程
1、先用单语语料训练两个词向量空间,然后用无监督方法对齐这两个空间
2. 对齐 encoder 语义空间,两种语言各一个 decoder;用 denoising auto-encoder 训练单语语言模型,用 back-translation 造伪平行语料优化似然函数
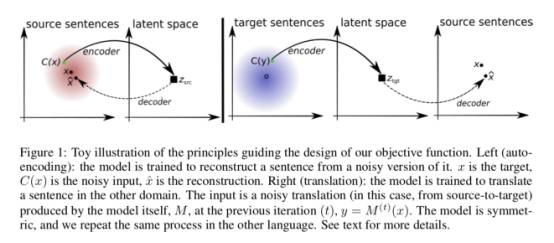
Facebook MUSE: a Python library for multilingual word embeddings now open sourced!
▌Facebook MUSE: 多语言词嵌入的开源Python库
Facebook的开源的MUSE,是一个无监督和有监督的多语言词嵌入Python库,以无监督或有监督的方式对齐嵌入空间。监督方法使用双语词典或相同的字符串。无监督的方法不使用任何并行数据。相反,它通过以无监督的方式对齐词嵌入空间来建立两种语言之间的双语词典(bilingual dictionary)。
Facebook MUSE基于fastText,有最先进的超过30种语言的多语言词嵌入功能。fastText是一个高效学习单词表示和句子分类的库。fastText使用Skipgram,word2vec或CBOW(连续单词袋)学习词嵌入,并将其用于文本分类。
你可以使用下面命令下载英语(en)和西班牙语(es)的词嵌入:
# English fastText Wikipedia embeddings curl -Lo data/wiki.en.vec https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.en.vec # Spanish fastText Wikipedia embeddings curl -Lo data/wiki.es.vec https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.es.vec |
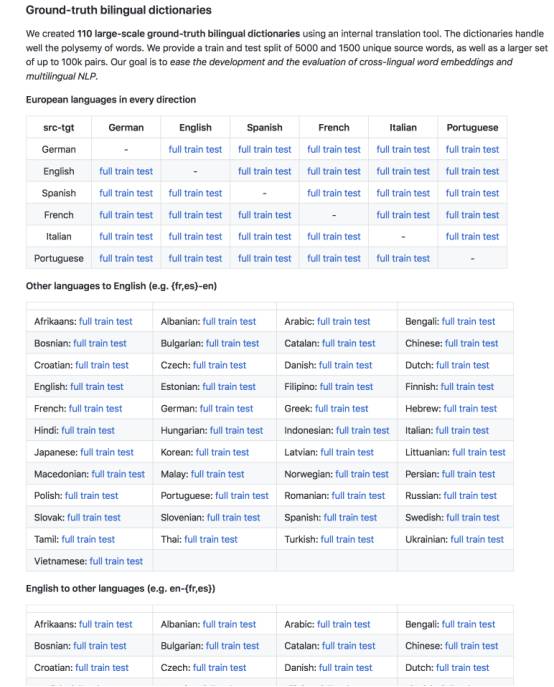
Facebook MUSE还拥有110个大规模高质量、真实的双语词典,以缓解跨语言词嵌入和多语言NLP方法的开发和评价。这些字典是使用内部翻译工具创建的。字典很好地处理了多义词(一词多义问题)。
如前所述,MUSE有两种方法来获取跨语言的词嵌入。
有监督方法使用训练双语词典(或相同的字符串作为锚点(anchor point))来学习使用Procrustes对齐方式从源到目标空间的映射。
要学习源和目标空间之间的映射,只需运行:
python supervised.py --src_lang en --tgt_lang es --src_emb data/wiki.en.vec --tgt_emb data/wiki.es.vec --n_iter 5 --dico_train default |
无监督方法使用对抗训练和Procrustes细化(Procrustes refinement)学习从源到目标空间的映射,而没有利用任何并行数据或锚点(anchor point)。
使用对抗训练和迭代Procrustes细化来学习映射,只需运行:
python unsupervised.py --src_lang en --tgt_lang es --src_emb data/wiki.en.vec --tgt_emb data/wiki.es.vec |
Facebook MUSE还有一个简单的脚本来评估单语言或跨语言词嵌入在几个不同任务中的效果:
单语言
python evaluate.py --src_lang en --src_emb data/wiki.en.vec --max_vocab 200000 |
跨语言
python evaluate.py --src_lang en --tgt_lang es --src_emb data/wiki.en-es.en.vec --tgt_emb data/wiki.en-es.es.vec --max_vocab 200000 |
要了解更多关于这个Python库的功能和下载其他资源,你可以参考下面链接(https://github.com/facebookresearch/MUSE )。
相关链接:
MUSE: https://github.com/facebookresearch/MUSE
fastText: https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md
Skipgram: https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
word2vec: https://www.tensorflow.org/tutorials/word2vec
CBOW: https://iksinc.wordpress.com/tag/continuous-bag-of-words-cbow/
▌详细资料链接
1. 论文地址:https://openreview.net/pdf?id=rkYTTf-AZ
2. 作者:Guillaume Lample, Ludovic Denoyer and Marc' Aurelio Ranzato
3. 研究机构:Facebook AI Research, Sorbonne Universit´es, UPMC Univ Paris 06, LIP6 UMR 7606, CNRS
4. 开源代码GitHub地址:https://github.com/facebookresearch/MUSE
5. 使用fastTest在Wikipedia上预训练的30种语言词向量

6. 110个大规模双语词典。
7. 相关解读链接
https://zhuanlan.zhihu.com/p/31404350
https://zhuanlan.zhihu.com/p/30649985
▌Github代码资源
MUSE: 多语无监督和有监督嵌入

MUSE是一个用于多语言词嵌入的Python库,其目标是提供:
l 基于fastText的一种先进的多语言词嵌入;
l 为训练和评价提供大规模的高质量双语词典。
其中包括两种方法,一种是使用双语词典或相同字符串的有监督方法;另一种是不使用任何平行数据的无监督方法(更多细节请参见无平行数据的单词翻译)。
▌依赖
Python 2/3 with NumPy/SciPy
PyTorch
Faiss (recommended) for fast nearest neighbor search (CPU or GPU).
MUSE可以在CPU或GPU上使用,兼容Python 2和3。对于GPU用户,Faiss是可选的,用Faiss-GPU命令可大大加快最邻近搜索的速度,所以强烈建议CPU用户使用Faiss。可以使用“conda install faiss-cpu -c pytorch”或“conda install faiss-gpu -c pytorch”来安装Faiss。
▌获得评价数据集
获得单语言和跨语言的词嵌入评估数据集:
Our 110 bilingual dictionaries(我们的110双语词典)
28 monolingual word similarity tasks for 6 languages, and the English word analogy task(28个6种语言的单语相似任务,以及英语单词类比任务;)
Cross-lingual word similarity tasks from SemEval2017(SemEval2017中的跨语言单词相似任务)
Sentence translation retrieval with Europarl corpora(Europarl 语料库的句子翻译检索)
在数据集运行:
./get_evaluation.sh
注意:默认情况下,Europarl数据库的下载被禁用,可以在下面链接启用它。
https://github.com/facebookresearch/MUSE/blob/master/data/get_evaluation.sh#L99-L100
▌获得单语词嵌入
对于预训练的单语词嵌入,我们强烈建议使用fastText Wikipedia的词嵌入,或者使用fastText从您的语料库中训练自己的词嵌入。
可以用下面方法来使用英语和西班牙语嵌入:
# English fastText Wikipedia embeddings curl -Lo data/wiki.en.vec https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.en.vec # Spanish fastText Wikipedia embeddings curl -Lo data/wiki.es.vec https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.es.vec |
▌单语词嵌入的对齐
包括两种获取跨语言单词嵌入的方法:
有监督:使用一个训练的双语词典(或相同字符串作为锚点),使用(迭代)Procrustes对齐的方法学习从源到目标空间的映射。
无监督:没有使用任何平行数据或锚点,使用对抗训练和(迭代)Procrustes细化(Procrustes refinement)学习从源到目标空间的映射。
要了解更多细节,请点击链接。
▌有监督方法: 迭代Procrustes(CPU|GPU)
为了学习源空间到目标空间的映射,运行:
python supervised.py --src_lang en --tgt_lang es --src_emb data/wiki.en.vec --tgt_emb data/wiki.es.vec --n_iter 5 --dico_train default
默认情况下,dico_train将指向ground-truth字典(可以根据上面描述进行下载);当设置为“identical_char”时,它将在源语言和目标语言之间使用相同的字符串来构成词汇表。日志和嵌入将被保存在dumped/目录中。
▌无监督方法: 对抗训练和细化(CPU|GPU)
要使用对抗训练和迭代Procrustes细化来学习映射,运行:
python unsupervised.py --src_lang en --tgt_lang es --src_emb data/wiki.en.vec --tgt_emb data/wiki.es.vec
默认情况下,用单词对的平均余弦值作为评价指标,单词所在的词典是用CSLS(Cross-domain similarity local scaling)方法构建的。
▌评价单语言或跨语言嵌入(CPU|GPU)
我们提供一个简单的脚本,用来评价单语言或跨语言词嵌入在几种任务上的效果:
单语言
python evaluate.py --src_lang en --src_emb data/wiki.en.vec --max_vocab 200000
跨语言
python evaluate.py --src_lang en --tgt_lang es --src_emb data/wiki.en-es.en.vec --tgt_emb data/wiki.en-es.es.vec --max_vocab 200000
▌下载
我们提供了多语言嵌入和ground-truth双语词典。
▌多语言词嵌入
我们发布了30个语言的维基百科的基于fastText的有监督词嵌入,并在单向量空间中对齐。
▌Ground-truth双语字典
我们使用内部翻译工具创建了110个大型ground-truth双语字典。字典能很好地处理一词多义问题。我们提供一个分别含有5000和1500个独特源语言的训练和测试分组,以及一个更大包含10万对词。我们的目标是简化跨语言嵌入和多语言NLP的开发和评估。
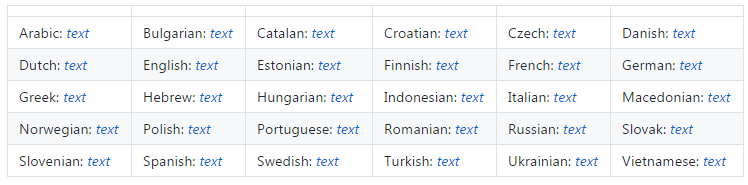
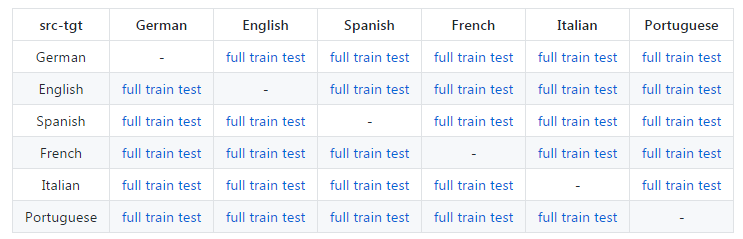
▌任何方向的欧洲语言
原始链接:https://github.com/facebookresearch/MUSE
▌其他语言到英语
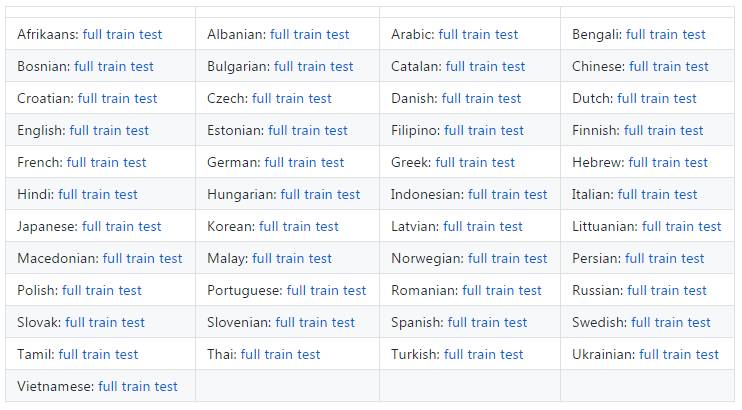
▌英语到其他语言
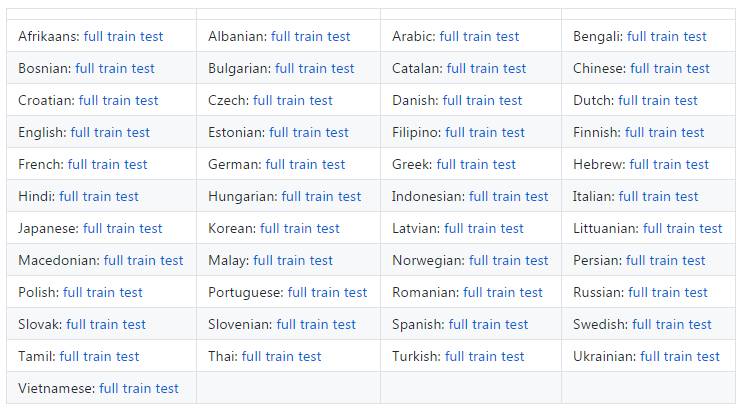
▌参考文献
如果你使用本文介绍的库,请引用文献[1]。
[1] A. Conneau*, G. Lample*, L. Denoyer, MA. Ranzato, H. Jégou, Word Translation Without Parallel Data
https://arxiv.org/pdf/1710.04087.pdf
@article{conneau2017word, title={Word Translation Without Parallel Data}, author={Conneau, Alexis and Lample, Guillaume and Ranzato, Marc'Aurelio and Denoyer, Ludovic and J{\'e}gou, Herv{\'e}}, journal={arXiv preprint arXiv:1710.04087}, year={2017} } |
MUSE是仅用单语数据[2]的无监督机器翻译工作的开山之作。
使用单语数据的无监督机器翻译
[2] G. Lample, L. Denoyer, MA. Ranzato Unsupervised Machine Translation With Monolingual Data Only
https://arxiv.org/abs/1711.00043
@article{lample2017unsupervised, title={Unsupervised Machine Translation Using Monolingual Corpora Only}, author={Lample, Guillaume and Denoyer, Ludovic and Ranzato, Marc'Aurelio}, journal={arXiv preprint arXiv:1711.00043}, year={2017} } |
相关链接:
fastText:https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md
双语词典(bilingual dictionaries):https://github.com/facebookresearch/MUSE#ground-truth-bilingual-dictionaries
SemEval2017:http://alt.qcri.org/semeval2017/task2/
Europarl 数据集:http://www.statmt.org/europarl/
fastText 维基百科嵌入:https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md
Procrustes:https://en.wikipedia.org/wiki/Orthogonal_Procrustes_problem
无并行数据的单词翻译:https://arxiv.org/pdf/1710.04087.pdf
https://github.com/facebookresearch/MUSE
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!



