一文看尽10篇ECCV 2020目标检测最新论文(PAA/PIoU Loss/ATF/LabelEnc等)
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

前言
自从ECCV 2020于7.3日开奖后,网上陆续放出大量论文。现在其实已经可以在官网看到paper list完整版了,但还没有提供论文PDF下载链接,所以应该还要等一个月左右的时候才能看到。到时候Amusi会整理所有检测论文的大盘点,敬请期待!
在此期间,Amusi 收集了10篇已经可以下载的ECCV 2020的目标检测论文。这次分享的paper将同步推送到 github上,欢迎大家 star/fork(点击阅读原文,也可直接访问):
https://github.com/amusi/awesome-object-detection
另外在CVer 公众号后台回复:ECCV2020目标检测,即可下载这10篇论文的PDF合集。
ECCV 2020 目标检测论文
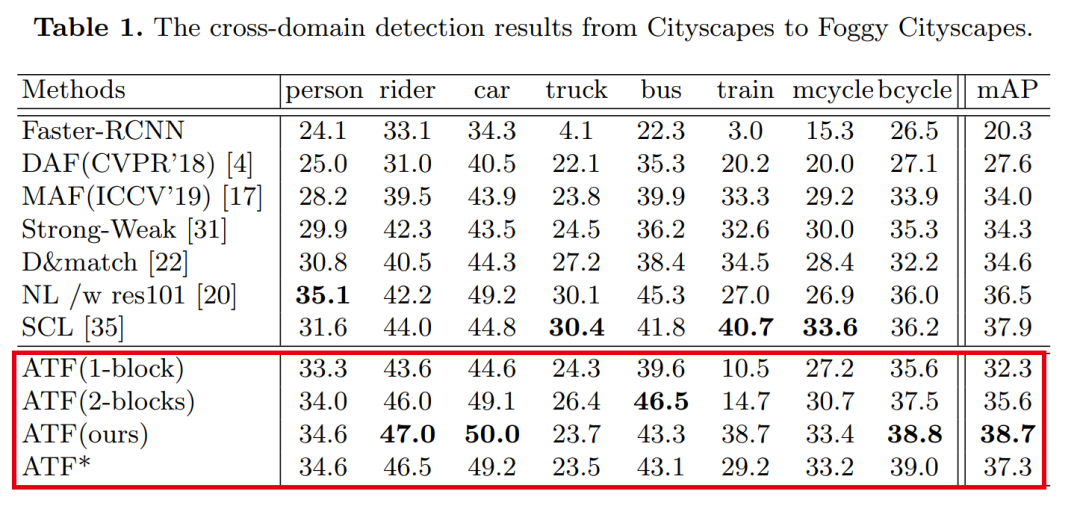
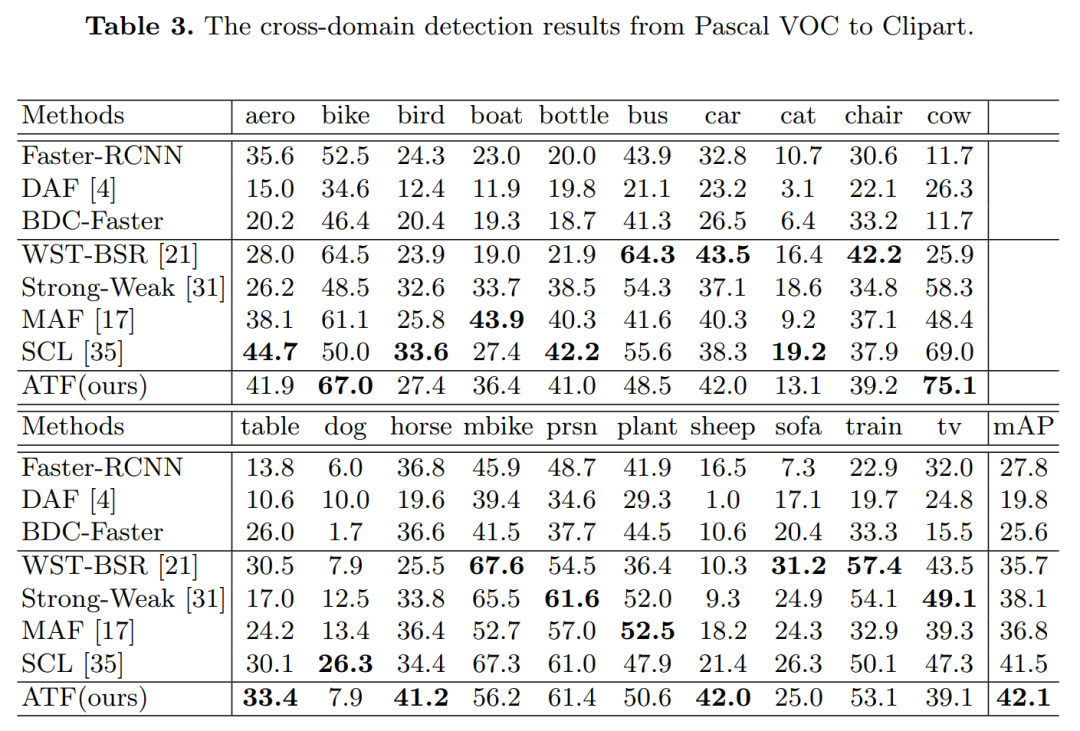
【1】ATF:非对称三路Faster-RCNN进行域自适应目标检测

Domain Adaptive Object Detection via Asymmetric Tri-way Faster-RCNN
作者团队:重庆大学 LiVE组
论文:https://arxiv.org/abs/2007.01571
表现SOTA!性能优于SCL、MAF和Strong-Weak等方法
由于存在域差异,传统的目标检测模型不可避免地会遇到性能下降。最近提出了无监督域自适应目标检测,以减小域之间的差异,其中源域是标签丰富的,而目标域是标签不可知的。现有模型遵循用于对抗域对齐的参数共享siamese结构,但是,这很容易导致源域崩溃和失控风险,并给特征自适应带来负面影响。主要原因是源与目标之间的标签不公平(不对称)使得参数共享机制无法适应。因此,为了避免因参数共享而导致源域崩溃的风险,我们提出了一种非对称三路Faster-RCNN(ATF)用于域自适应目标检测。
我们的ATF模型有两个明显的优点:
1)部署由源标签监督的辅助网络,以学习辅助目标特征并同时保留源域的区分,从而增强了域对齐的结构区分(对象分类与包围盒回归) 。
2)由主网和独立辅助网组成的不对称结构从本质上克服了引起源风险崩溃的参数共享问题。所提出的ATF检测器的适配安全性得到保证。在包括城市景观,有雾城市景观,KITTI,Sim10k,Pascal VOC,Clipart and Watercolor在内的许多数据集上进行了广泛的实验,证明了我们方法的SOTA性能。
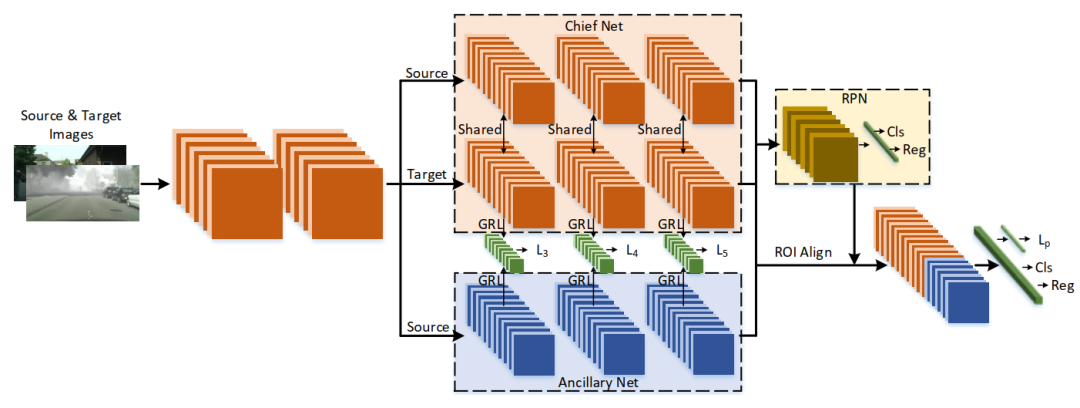
ATF
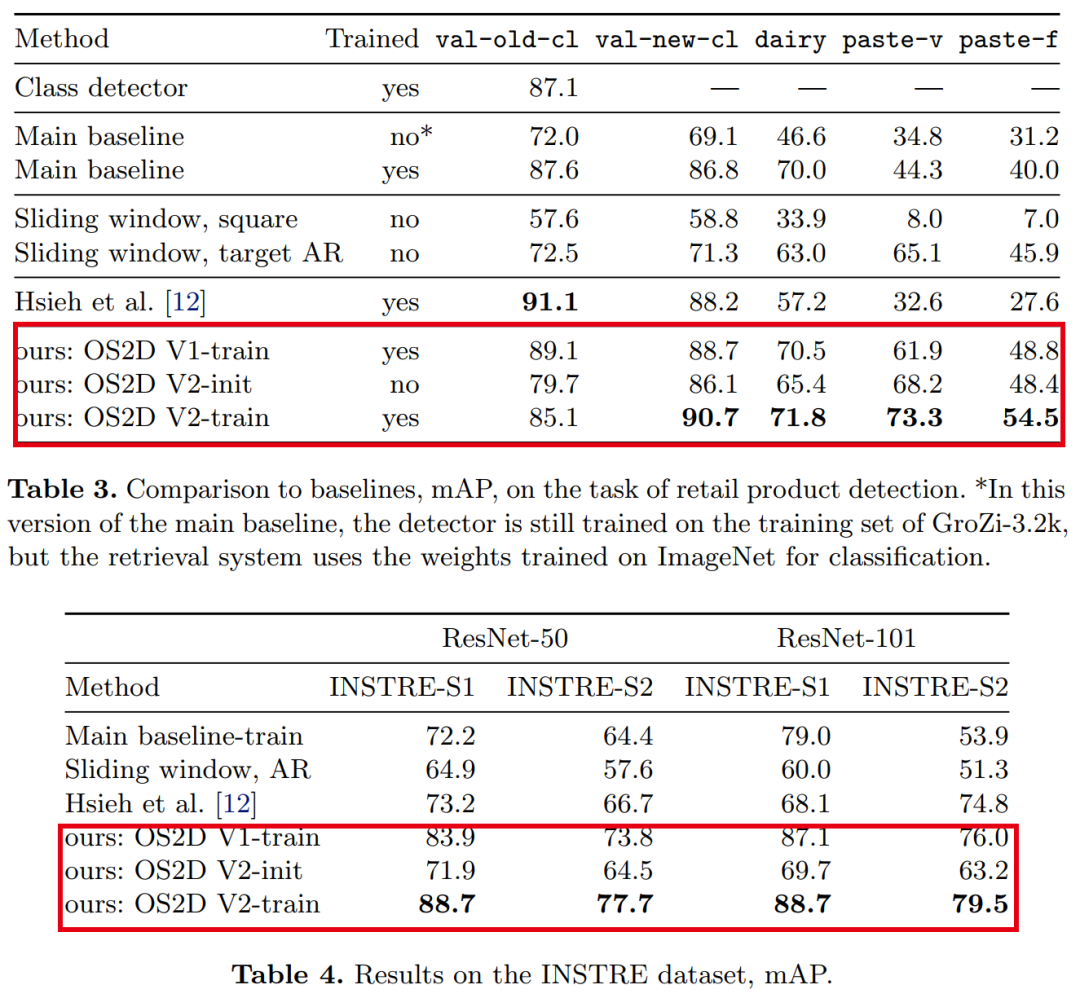
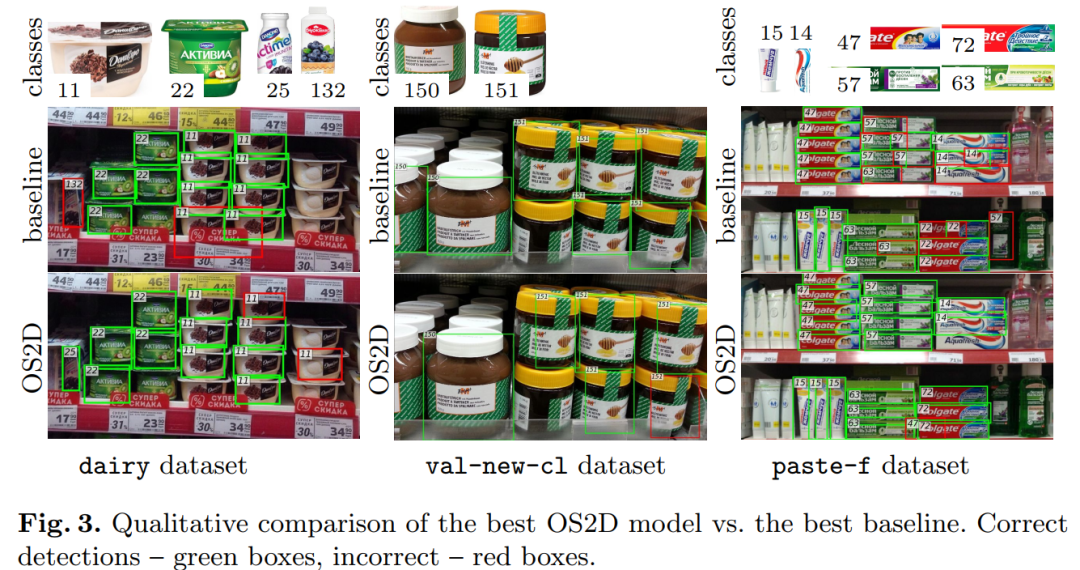
【2】OS2D:匹配Anchor特征进行单阶段One-Shot目标检测

OS2D: One-Stage One-Shot Object Detection by Matching Anchor Features
作者团队:三星HSE lab&MIRUM公司
论文:https://arxiv.org/abs/2003.06800
代码:https://github.com/aosokin/os2d
表现SOTA!性能优于CoAE(NeurIPS 2019)等网络,代码现已开源!
在本文中,我们考虑了one-shot目标检测的任务。与标准目标检测不同,用于训练和测试的目标类别不重叠。我们构建了一个联合执行定位和识别的一阶段系统。我们使用学习到的局部特征的密集相关匹配来查找对应关系,使用前馈几何变换模型来对齐特征,并使用相关张量的双线性重采样来计算对齐特征的检测分数。所有组件都是可区分的,从而可以进行端到端培训。对几个具有挑战性的领域(零售产品,3D目标,建筑物和徽标)进行的实验评估表明,我们的方法可以检测到看不见的类别(例如,在杂货店训练时的牙膏),并且在性能上优于几个基准。
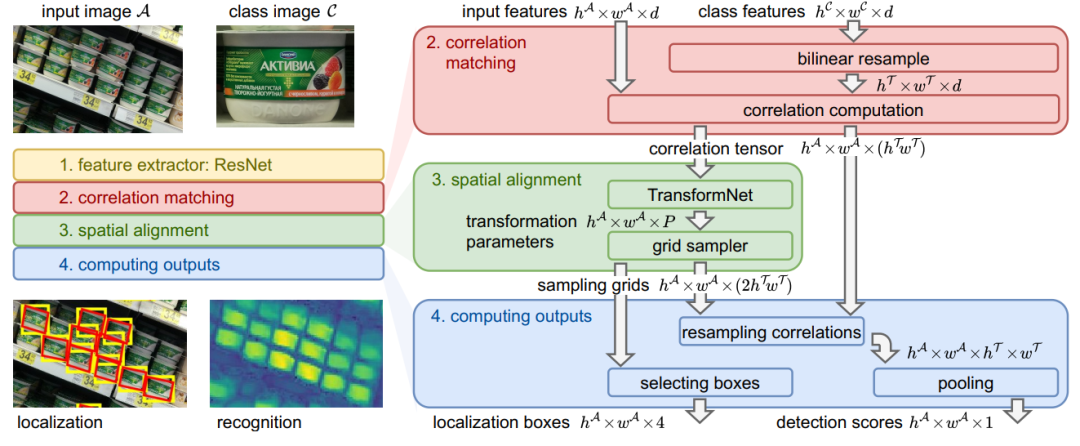
OS2D
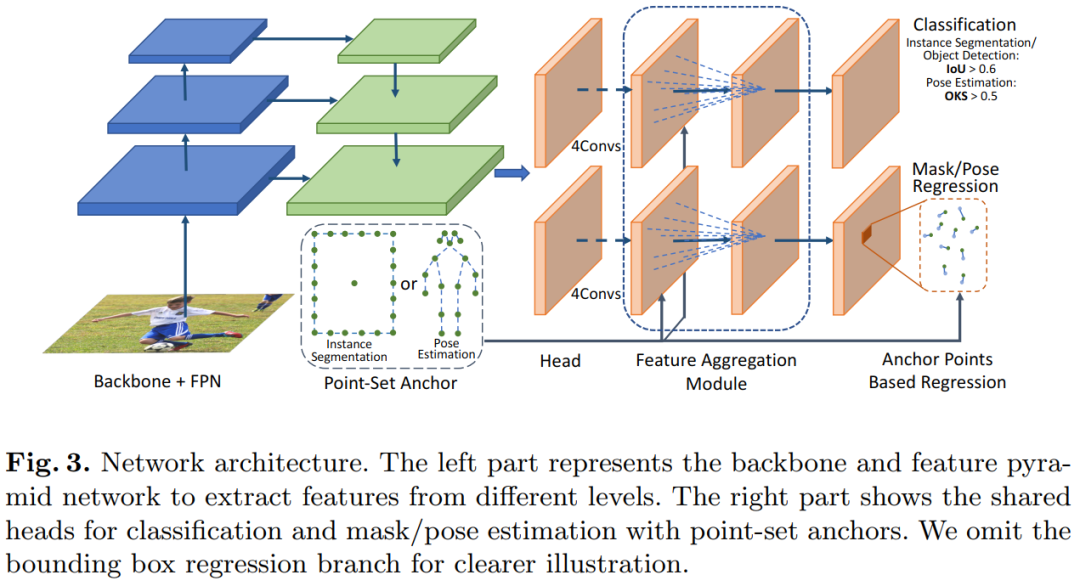
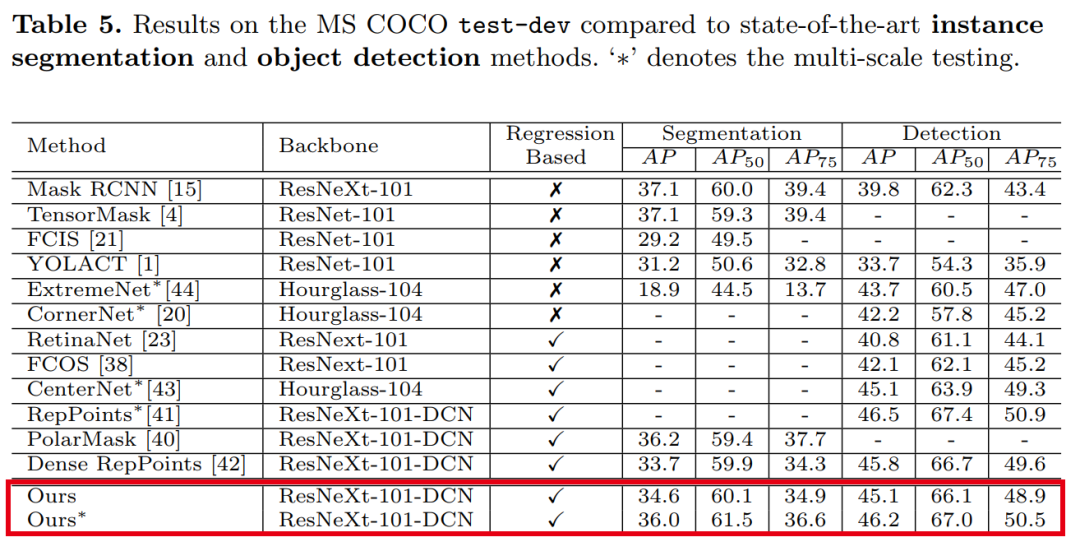
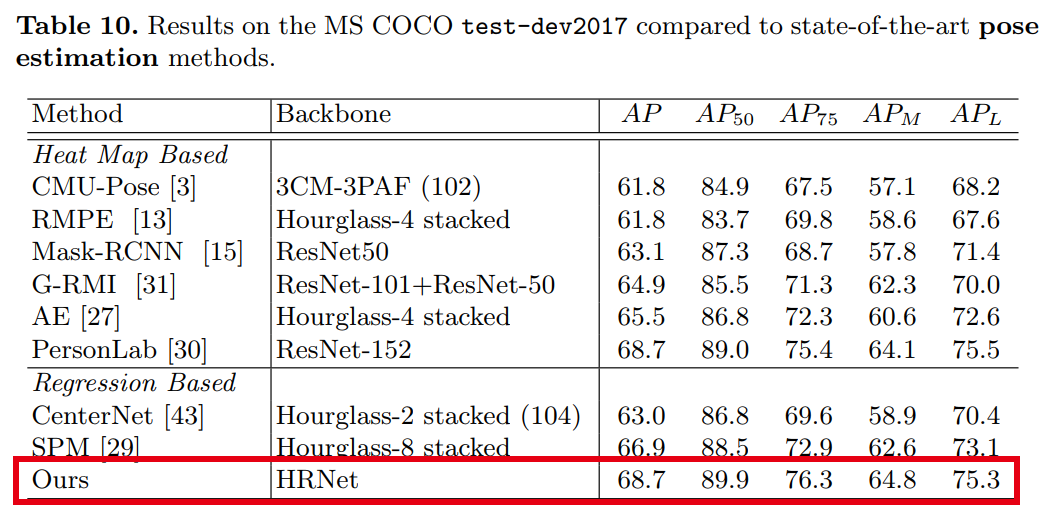
【3】用于目标检测,实例分割和姿势估计的点集Anchors Point-Set Anchors

Point-Set Anchors for Object Detection, Instance Segmentation and Pose Estimation
作者团队:微软亚洲研究院(王井东等)&北京大学
论文:https://arxiv.org/abs/2007.02846
性能优于RepPoints、TensorMask、PersonLab等网络
用于目标检测和人体姿态估计的最新方法是从物体或人的中心点回归边界框或人体关键点。尽管此中心点回归既简单又有效,但我们认为,由于对象变形和比例/方向变化,在中心点提取的图像特征包含的信息有限,无法预测遥远的关键点或边界框边界。为了促进推断,我们提出改为从放置在更有利位置的一组点进行回归。设置该点集以反映给定任务的良好初始化,例如训练数据中用于姿态估计的模式,这些模式比中心点更接近ground-truth情况,并提供更多的信息以供回归。由于点集的效用取决于其比例,长宽比和旋转与目标的匹配程度,因此我们采用anchor技术对这些变换进行采样,以生成其他点集候选项。我们将此提出的框架(称为Point-Set Anchors)应用于目标检测,实例分割和人体姿态估计。我们的结果表明,对于这些任务中的每一项,这种通用方法都可以与最新技术相媲美。
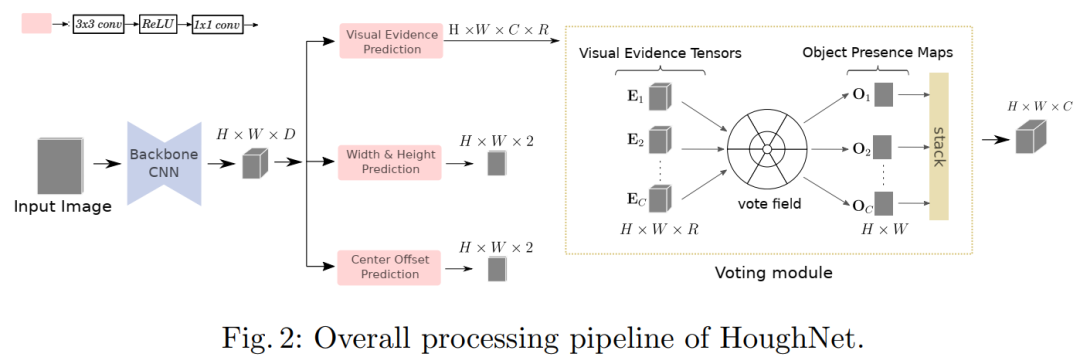
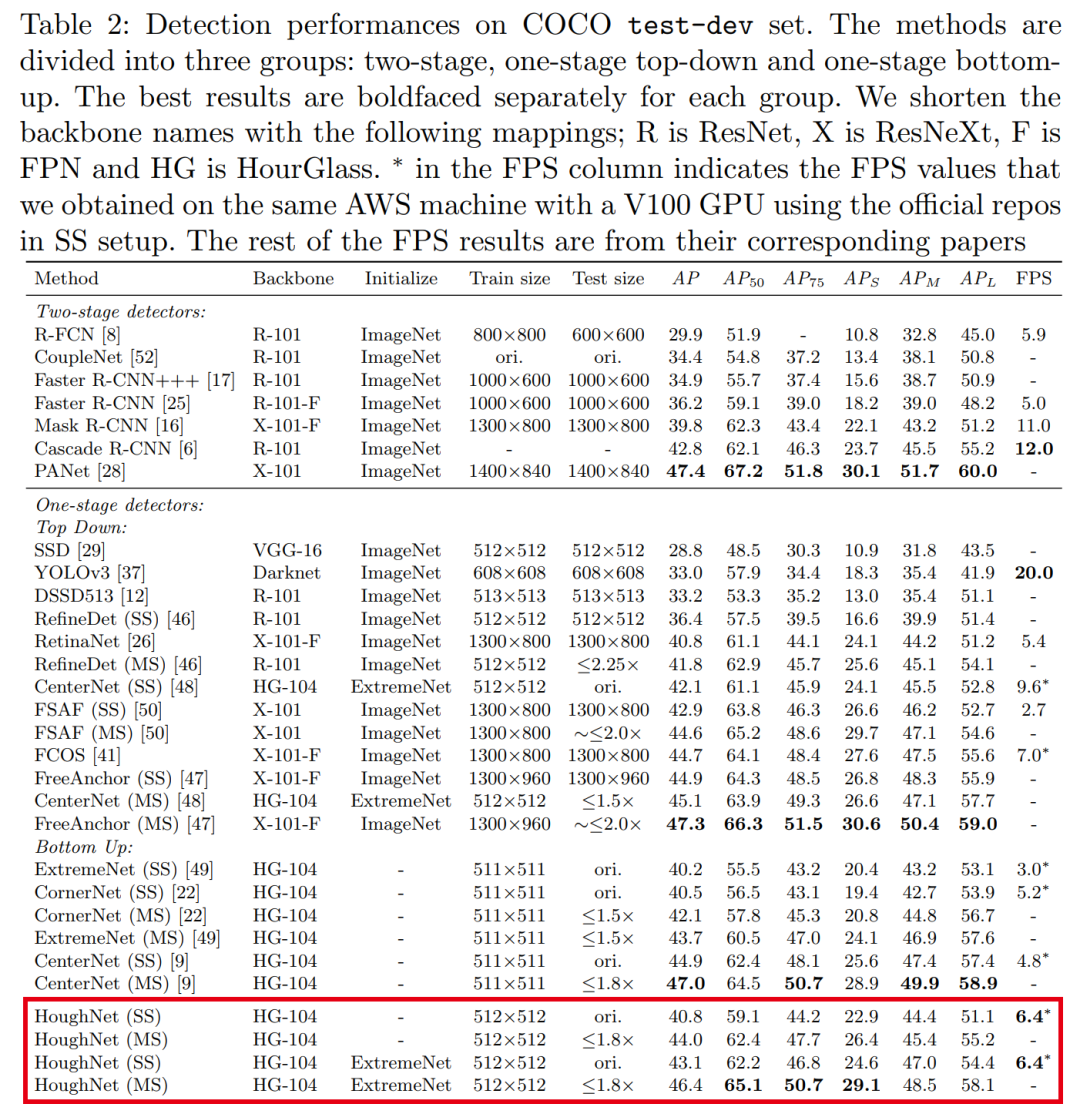
【4】HoughNet:单阶段/Anchor-free/基于投票的自下而上的目标检测

HoughNet: Integrating near and long-range evidence for bottom-up object detection
作者团队:中东技术大学&哈西德佩大学
论文:https://arxiv.org/abs/2007.02355
代码:https://github.com/nerminsamet/houghnet
论文解读:ECCV2020 | HoughNet:将投票机制引入目标检测,整合局部和全局信息
性能优于CenterNet、FCOS等网络,代码即将开源!受到通用霍夫变换的启发,HoughNet通过在某个位置上投的票数之和确定对象在某个位置上的存在。根据对数极性投票字段,从近距离和远距离位置收集投票。借助这种投票机制,HoughNet能够集成近距离和远距离的类条件证据以进行视觉识别,从而泛化和增强了当前仅基于定位信息的目标检测方法。在COCO数据集上,HoughNet达到了46.4 AP(和65.1 AP_50),在自下而上的对目标检测中与最新技术相当,并且性能优于大多数主要的一阶段和两阶段方法。通过将HoughNet的投票模块集成到两个不同的GAN模型中,并进一步证明了两种情况下的准确性,我们进一步验证了我们的提出在另一任务(即“照片上的标签”)图像生成中的有效性。
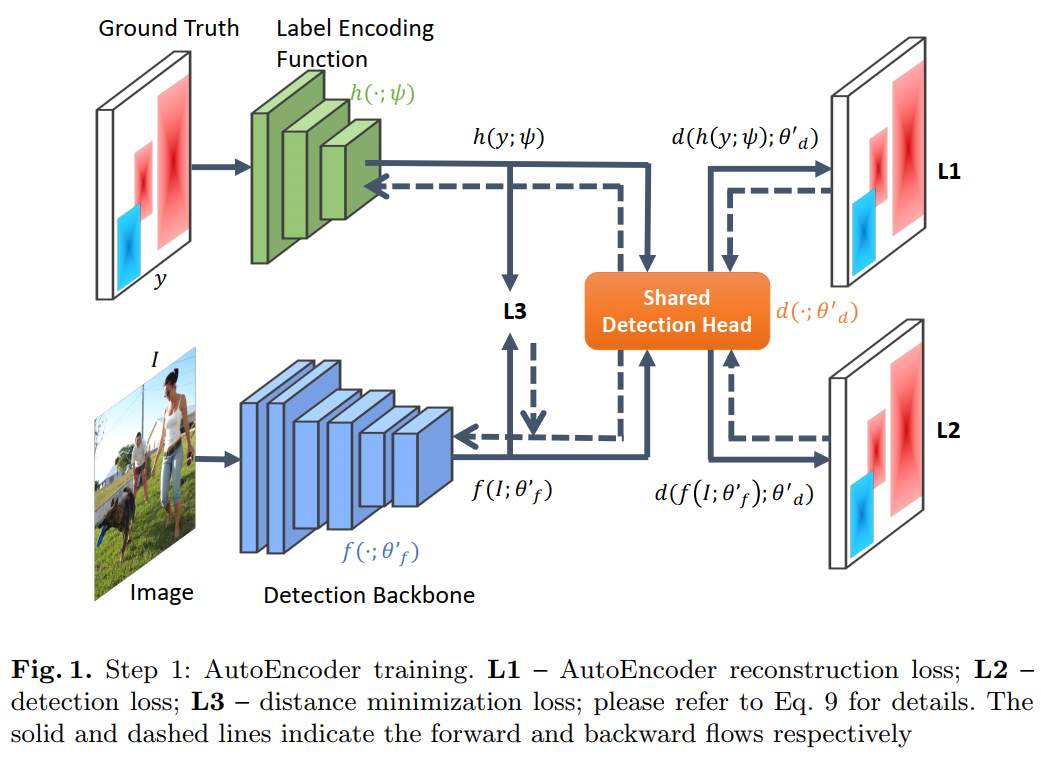
【5】LabelEnc:一种新的目标检测中间监督方法

LabelEnc: A New Intermediate Supervision Method for Object Detection
作者团队:同济大学&旷视研究院
论文:https://arxiv.org/abs/2007.03282
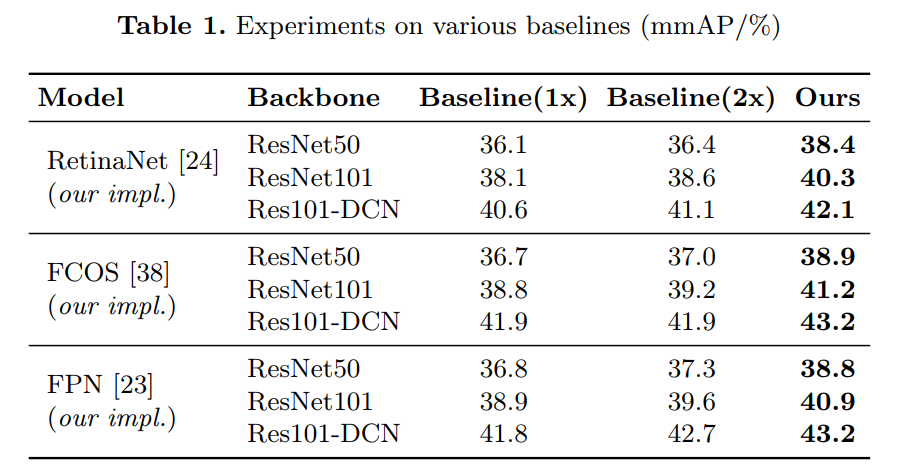
实验表明,无论是一阶段还是两阶段框架,本训练方法都能在COCO数据集上将各种检测系统提高2%左右,如FCOS、RetinaNet等。
在本文中,我们提出了一种新的中间监督方法,称为LabelEnc,以促进对目标检测系统的训练。关键思想是引入一种新颖的标签编码功能,将真实的标签映射到潜在的嵌入中,在训练过程中充当对检测主干的辅助中间监督。我们的方法主要包括两步训练过程。首先,我们通过标签空间中定义的AutoEncoder优化标签编码功能,近似目标对象检测器的“所需”中间表征。其次,利用学习到的标签编码功能,我们在检测主干上引入了新的辅助损失,从而有利于派生检测器的性能。实验表明,无论是一阶段还是两阶段框架,我们的方法都能在COCO数据集上将各种检测系统提高2%左右。此外,辅助结构仅在训练期间存在,即,其推理时间完全cost-free。
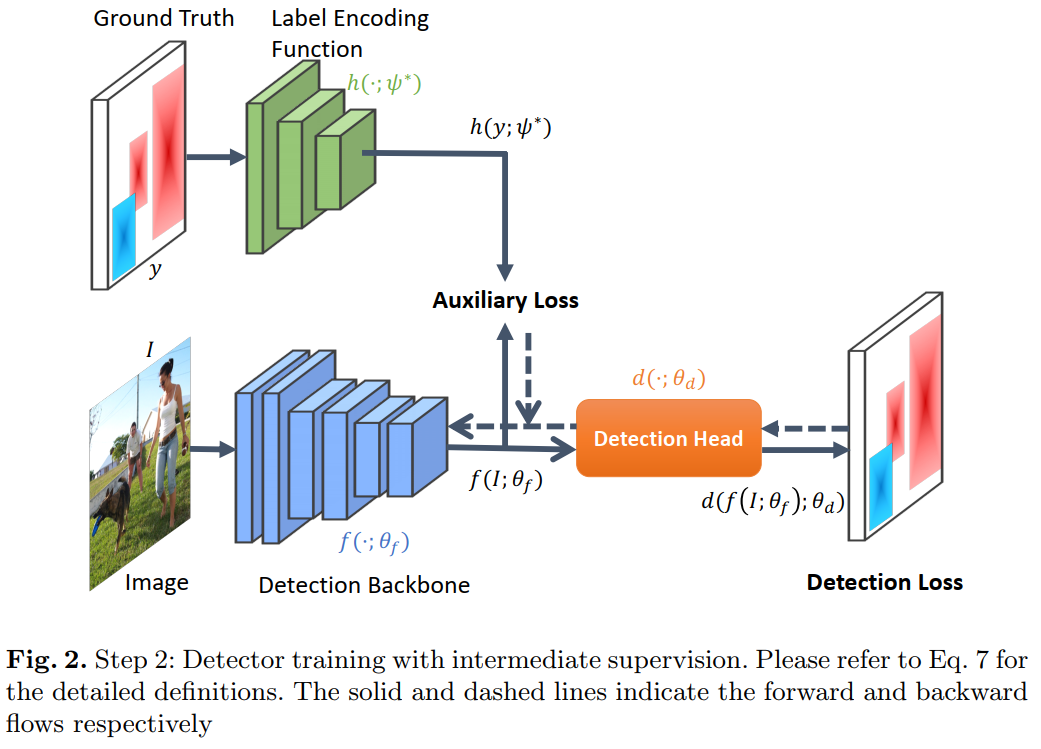
【6】PAA:用于目标检测的IoU预测的概率Anchor分配

Probabilistic Anchor Assignment with IoU Prediction for Object Detection
作者团队:XL8公司&高通(韩国)
论文:https://arxiv.org/abs/2007.08103
代码:https://github.com/kkhoot/PAA
单论 53.5 AP数据,应该是目前最强的单阶段目标检测网络,优于AutoAssign、ATSS、FreeAnchor等,但应该打不过今天刚出的RepPointsv2(基于相同backbone),毕竟时间不同,这篇论文是相当棒的检测论文。代码刚刚开源!在目标检测中,确定将哪些anchor分配为正样本或负样本(称为anchor分配)已被公认为是可以严重影响模型性能的核心过程。
在本文中,我们提出了一种新颖的anchor分配策略,该策略根据模型的学习状态将anchor自适应地分为正样本和负样本用于ground-truth边界框,从而能够以概率方式推理出分离。为此,我们首先计算以模型为条件的anchor的分数,并对这些分数拟合概率分布。然后根据anchor的概率将模型分为正样本和负样本,对模型进行训练。此外,我们调查了训练和测试目标之间的差距,并提出预测检测到的盒子的IoU,以作为衡量定位质量的指标,以减少差异。分类和定位质量的综合得分在非极大值抑制中用作anchor选择度量,与提出的anchor分配策略完全吻合,并带来了显著的性能改进。所提出的方法仅向RetinaNet基线添加单个卷积层,并且每个位置不需要多个anchor,因此非常有效。
实验结果验证了所提方法的有效性。特别是,我们的模型在具有各种主干的MS COCO test-dev数据集上为单阶段检测器创下了新记录。
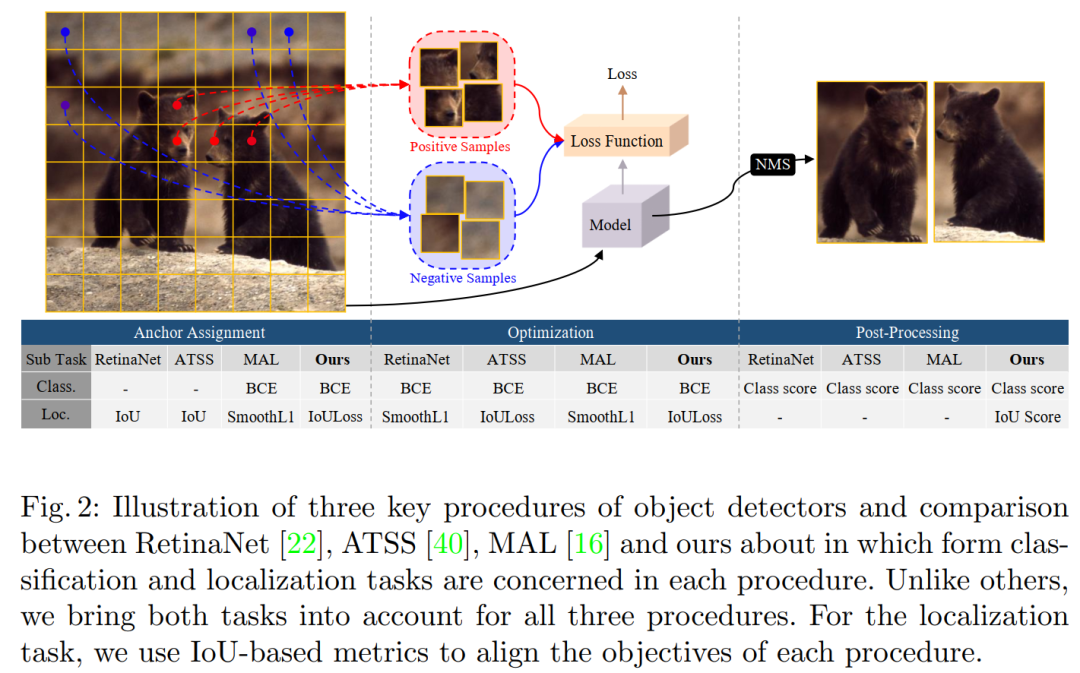

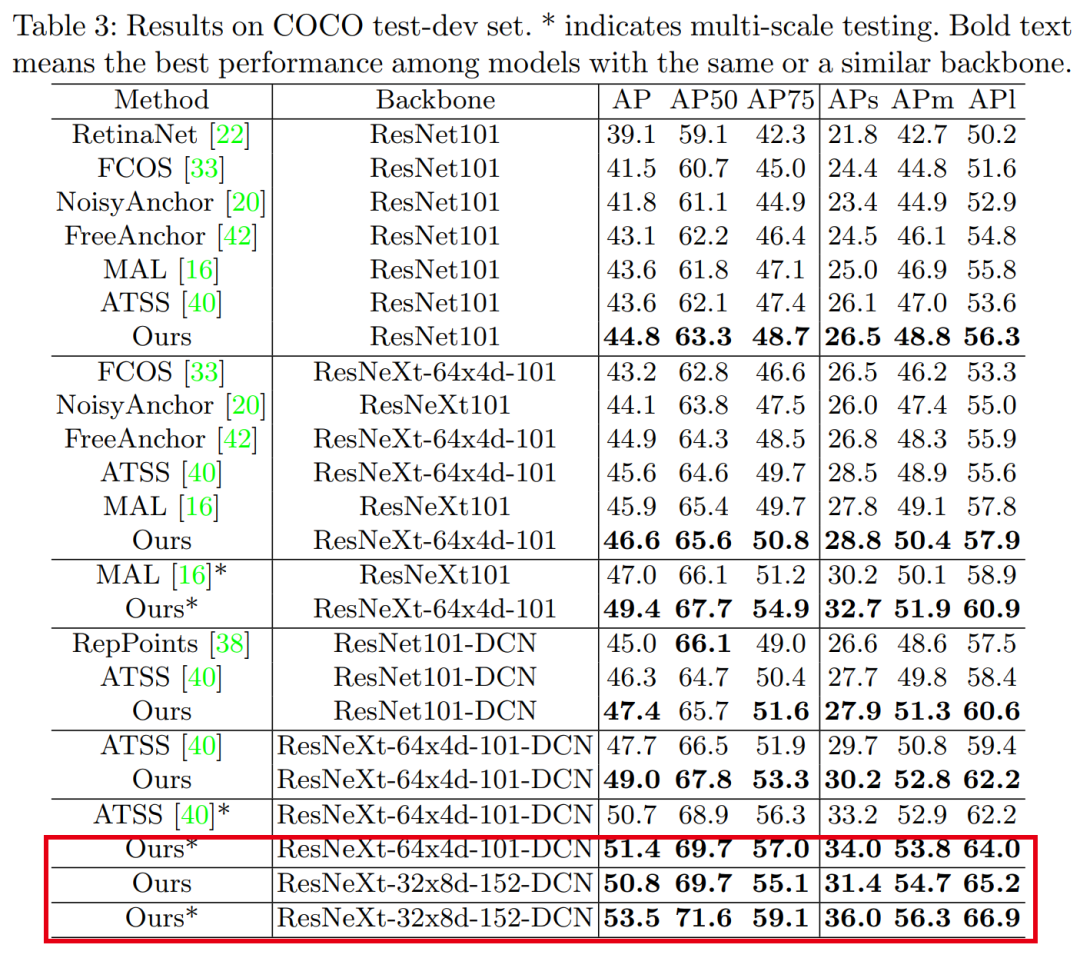
【7】通过渐进式知识迁移来增强弱监督目标检测

Boosting Weakly Supervised Object Detection with Progressive Knowledge Transfer
作者团队:伊利诺伊大学厄巴纳-香槟分校&微软
论文:https://arxiv.org/abs/2007.07986
代码:https://github.com/mikuhatsune/wsod_transfer
表现SOTA!性能优于WSOD2、OICR+UBBR等网络,代码现已开源!
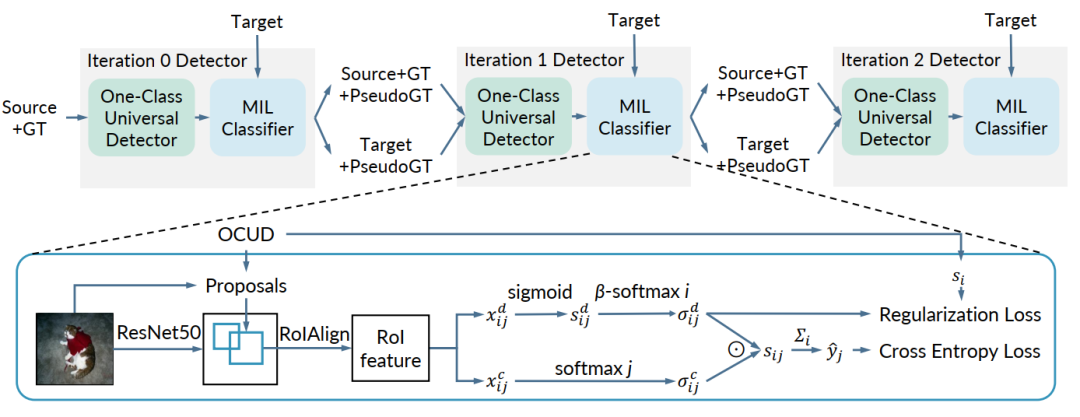
在本文中,我们提出了一个有效的知识迁移框架,可以借助外部全注释源数据集来提高弱监督目标检测的准确性,该数据集的类别可能与目标域不重叠。由于存在许多现成的检测数据集,因此该设置具有很大的实用价值。为了更有效地利用源数据集,我们提出通过一类通用检测器迭代地从源域转移知识,并学习目标域检测器。目标域检测器在每次迭代中挖掘的盒级伪ground-truth有效地改善了一类通用检测器。因此,源数据集中的知识得到了更彻底的开发和利用。以Pascal VOC 2007为目标弱注释数据集,以COCO / ImageNet作为源完全注释数据集进行了广泛的实验。通过提出的解决方案,我们在VOC测试仪上实现了59.7%的mAP检测性能,并在对完全监督的Faster RCNN进行了挖掘的伪ground-truth训练后,其mAP达到了60.2%。这比相关文献中任何以前的已知结果要好得多,并且在知识迁移设置下设置了一种新的最新的弱监督目标检测技术。
wsod_transfer


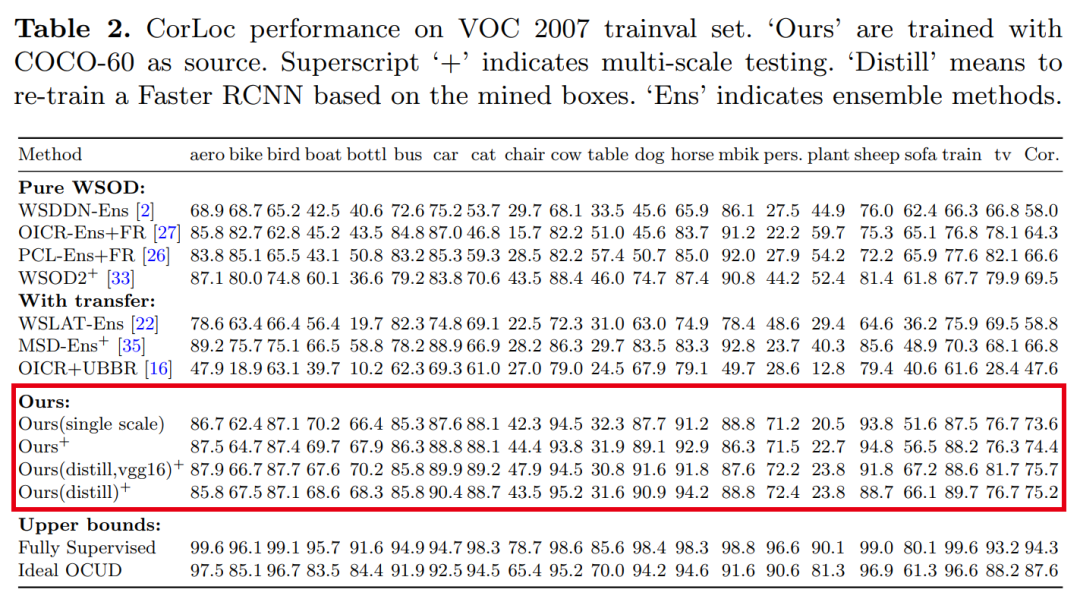
【8】PIoU Loss:在复杂环境中实现准确的多方向目标检测

PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments
作者团队:扩博智能&上海交大&多媒体大学
论文:https://arxiv.org/abs/2007.09584
代码和数据集:https://github.com/clobotics/piou
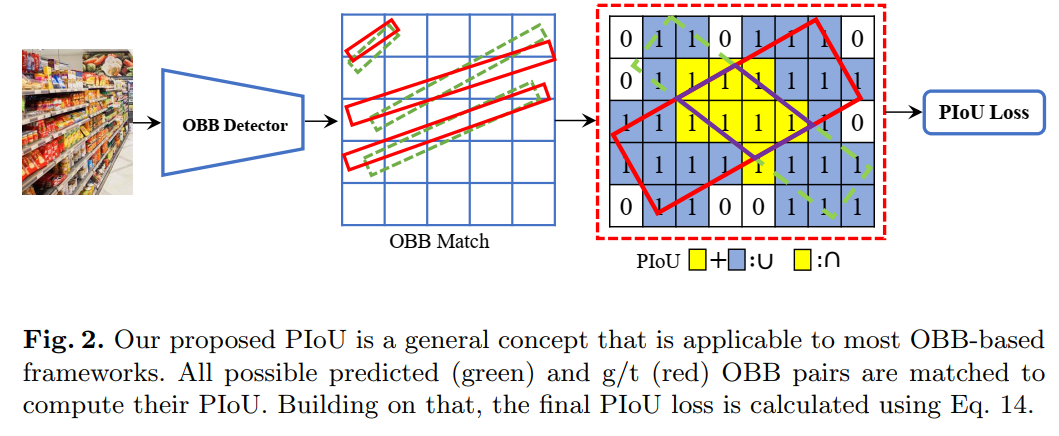
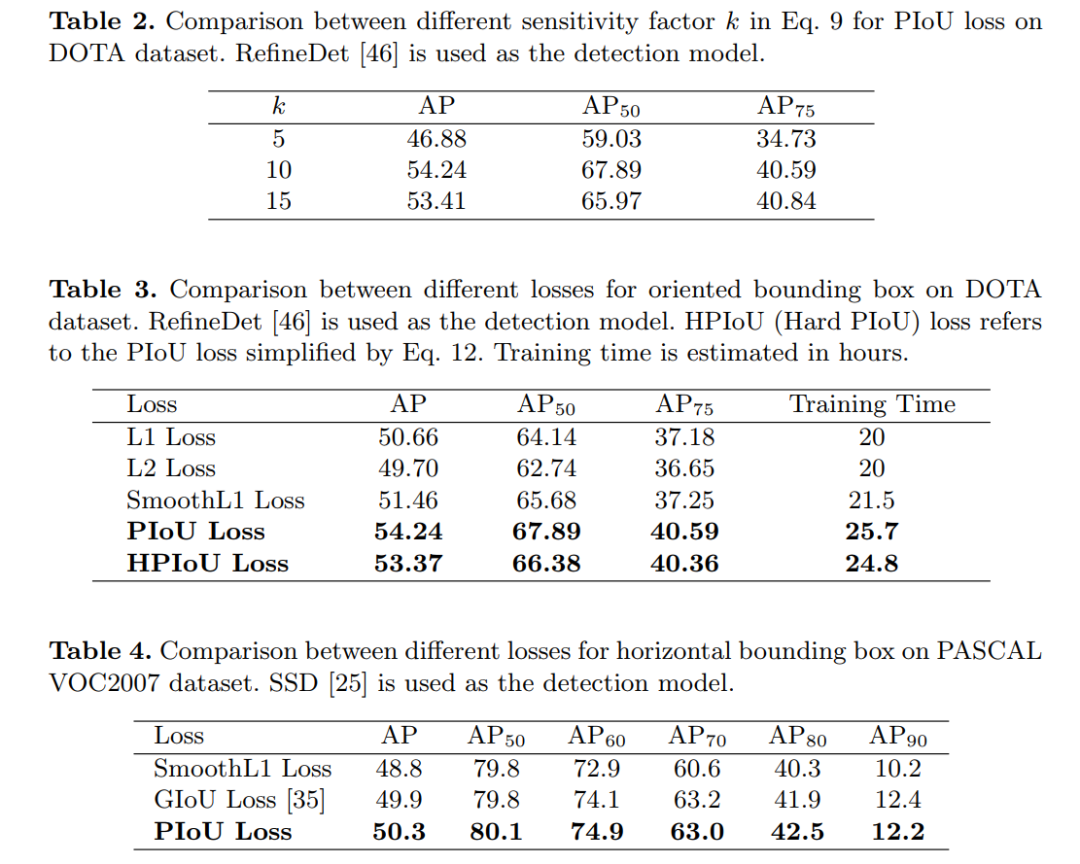
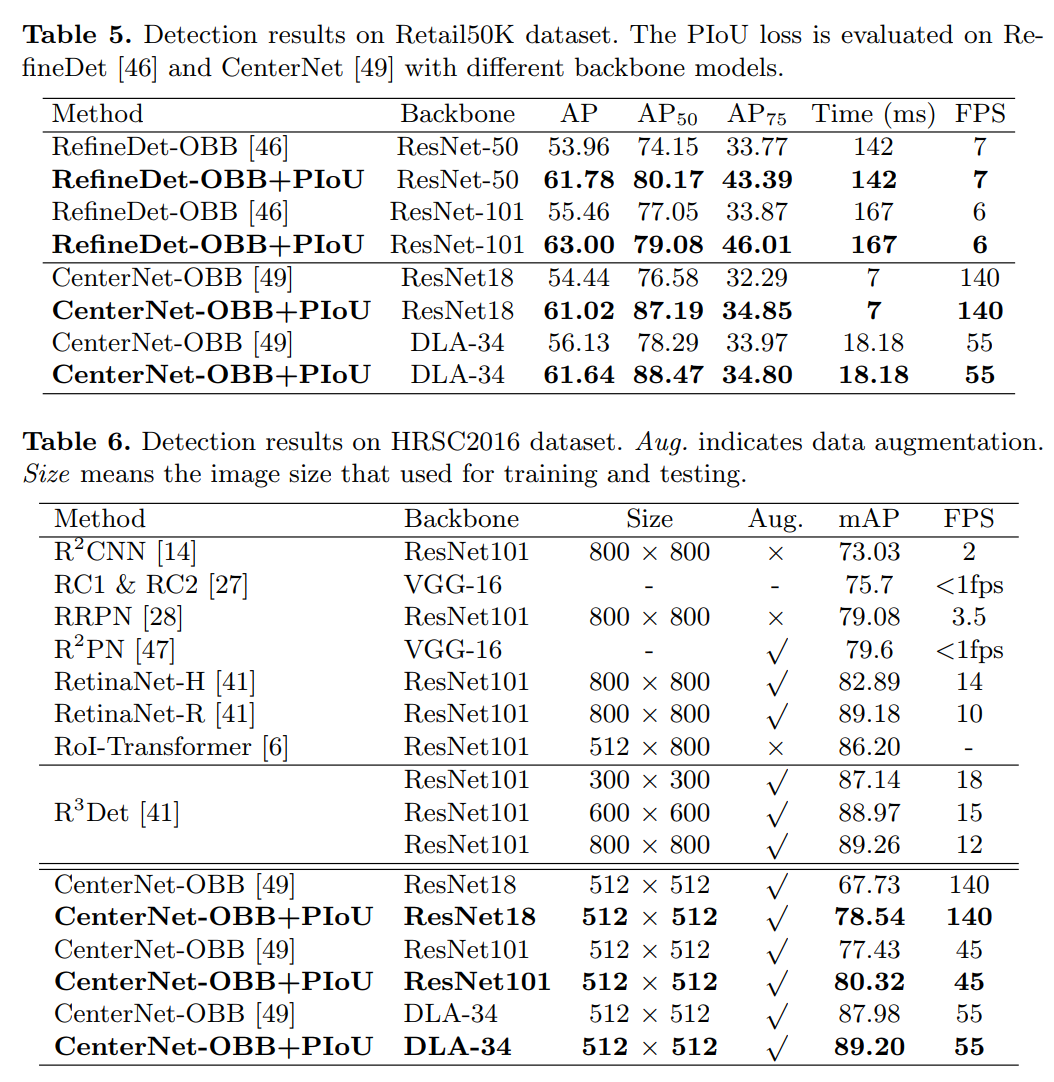
可与现有检测网络集成,来提升多方向目标检测性能,性能优于GIoU Loss、SmoothL1 Loss等损失函数,代码刚刚开源!并提出Retail50K新零售商品检测数据集,也刚开源!使用方向边界框(OBB)进行目标检测可以通过减少与背景区域的重叠来更好地定位旋转对象。现有的OBB方法大多是通过引入由距离损失优化的附加角度尺寸而在水平边界框检测器上构建的。但是,由于距离损失仅使OBB的角度误差最小,并且与IoU的相关性较松散,因此它对具有高纵横比的对象不敏感。因此,制定了一种新的损失,即Pixels-IoU(PIoU)损失,以利用角度和IoU进行精确的OBB回归。PIoU损失是从IoU度量导出的,具有像素级形式,这很简单,适用于水平和定向边界框。为了证明其有效性,我们评估了基于anchor和anchor-free框架的PIoU损失。实验结果表明,PioU loss可以显著提高OBB检测器的性能,特别是在具有高长宽比和复杂背景的对象上。此外,以前的评估数据集不包括对象具有高长宽比的场景,因此引入了新的数据集Retail50K来鼓励社区使OBB检测器适应更复杂的环境。
【9】MPSR:用于Few-Shot目标检测的多尺度正样本优化

Multi-Scale Positive Sample Refinement for Few-Shot Object Detection
作者团队:北京航空航天大学
论文:https://arxiv.org/abs/2007.09384
代码:https://github.com/jiaxi-wu/MPSR
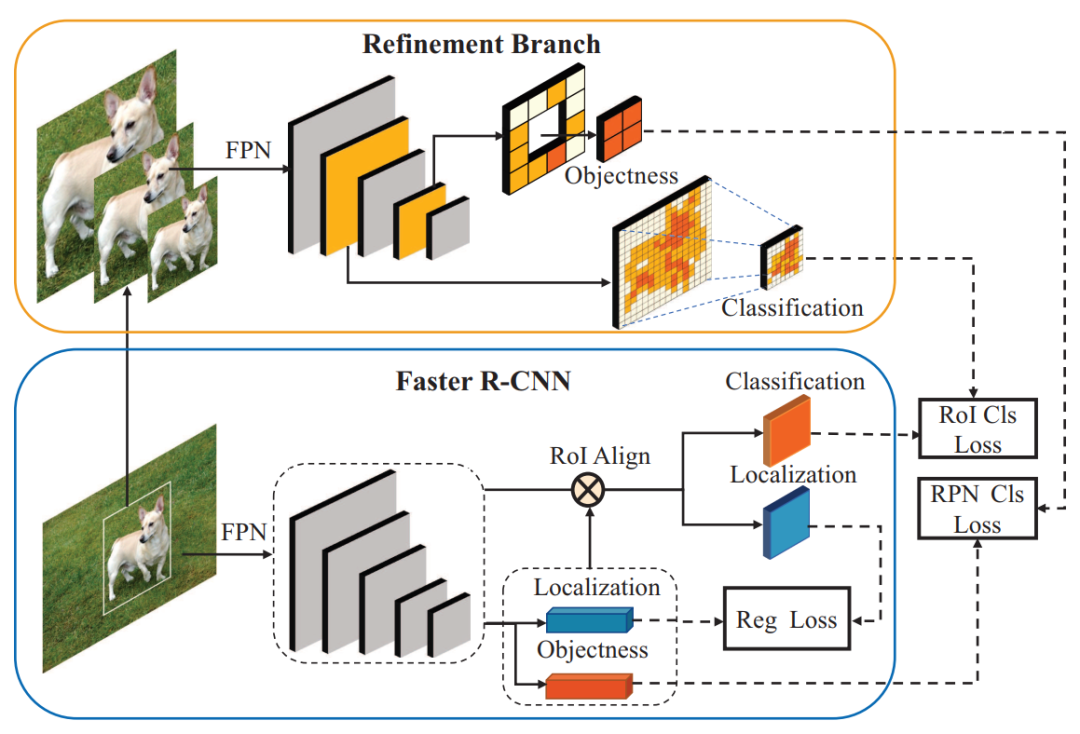
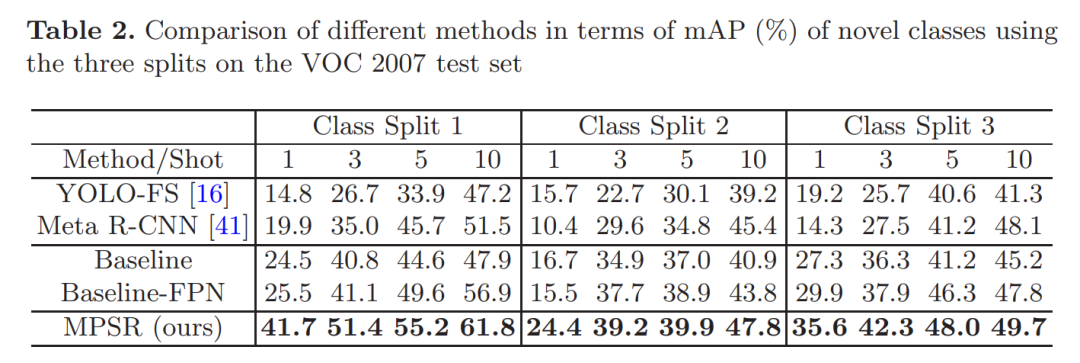
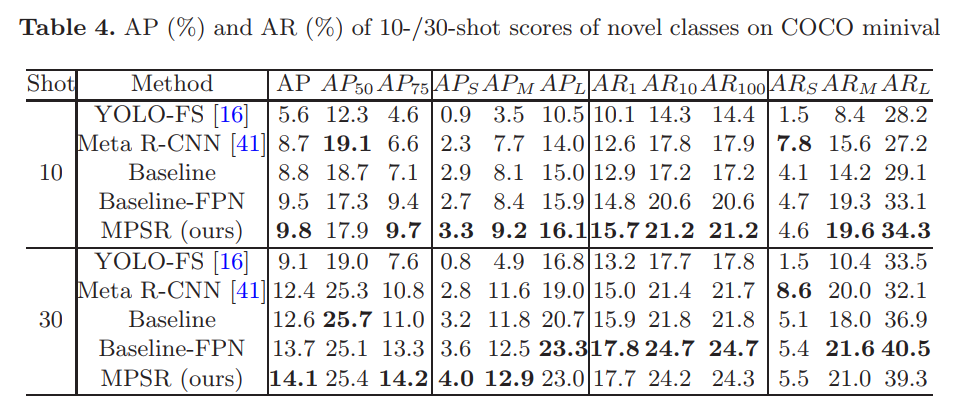
表现SOTA!性能优于Meta R-CNN、YOLO-FS等网络,代码刚刚开源!Few-shot目标检测(FSOD)可帮助检测器在很少的训练实例的情况下适应未知的类别,并且在手动标注很耗时或数据采集受到限制时非常有用。与以前利用few-shot分类技术促进FSOD的尝试不同,这项工作强调了处理尺度变化问题的必要性,由于独特的样本分布,这具有挑战性。为此,我们提出了一种多尺度正样本细化(MPSR)方法来丰富FSOD中的对象尺度。它生成多尺度的正样本作为目标金字塔,并在各种尺度上完善预测。我们通过将其集成为带有FPN的Faster R-CNN流行架构的辅助分支来展示其优势,从而提供强大的FSOD解决方案。在PASCAL VOC和MS COCO上进行了一些实验,所提出的方法达到了最新技术成果,并且明显优于其他同行,这表明了其有效性。
MPSR
【10】S4OD:通过选择性自监督自训练改进目标检测

Improving Object Detection with Selective Self-supervised Self-training
作者团队:中佛罗里达大学&谷歌
论文:https://arxiv.org/abs/2007.09162
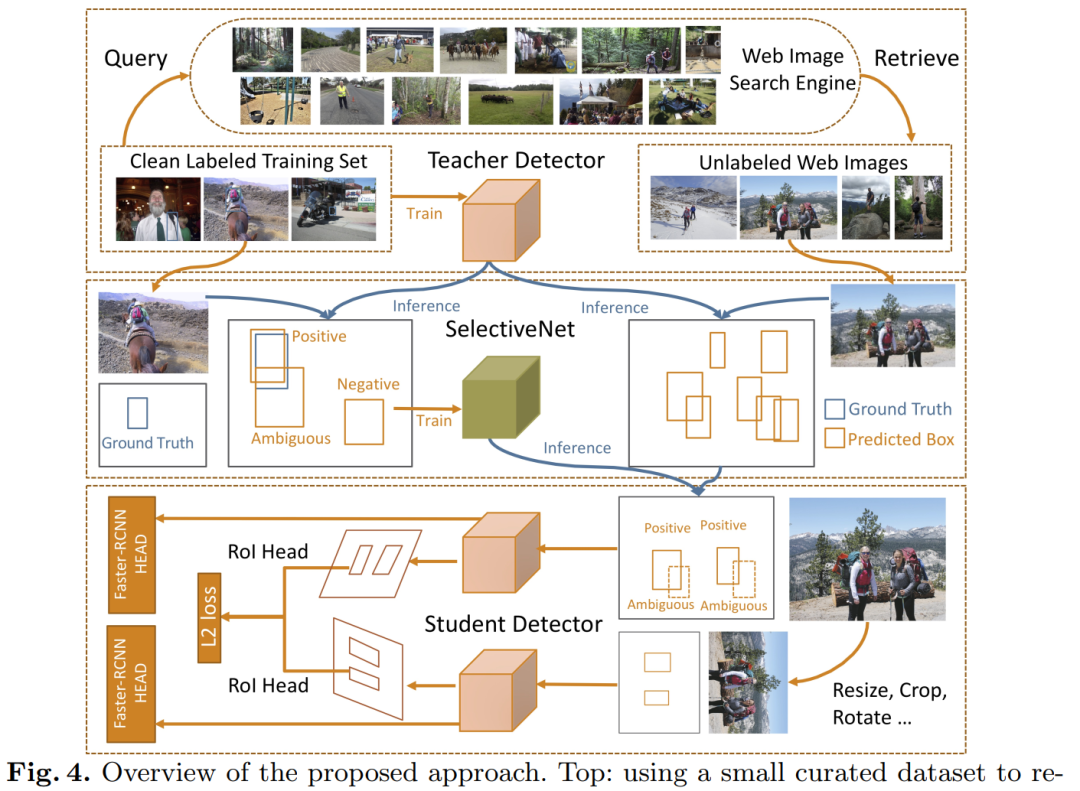
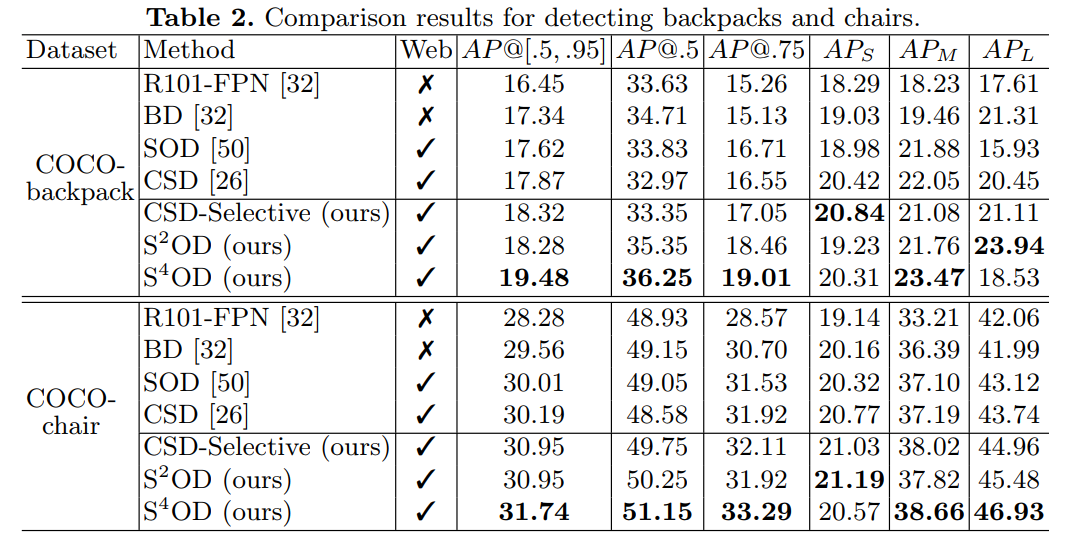
本文提出通过大量未标注的网络(Web)图像来提升目标检测性能,并引入自监督、自训练方法,优于CSD等网络。我们研究了如何利用Web图像来增强目标检测数据集。我们的方法有两个方面。一方面,我们通过图像到图像的搜索来检索Web图像,与其他搜索方法相比,它从策展的数据中引起的域偏移更少。Web图像是多种多样的,提供各种各样的物体姿势,外观,它们与上下文的交互作用等。另一方面,我们提出了一种新颖的学习方法,该方法受两条平行的工作线的激励,它们探索了未标记的数据用于图像分类:自训练和自监督学习。由于Web图像和curated数据集之间的域差异,他们无法改进其原形态的目标检测器。为了应对这一挑战,我们提出了一个选择性网络来纠正Web图像中的监督信号。它不仅可以识别正边界框,而且可以为挖掘hard negative边界框创建安全区域。我们报告了从日常场景中检测背包和椅子以及其他具有挑战性的目标类别的最新结果。
下载
在CVer后台回复:ECCV2020目标检测,即可下载上述10篇论文PDF
后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4100人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!



