【导读】国际万维网大会(The Web Conference,简称WWW会议)是由国际万维网会议委员会发起主办的国际顶级学术会议,创办于1994年,每年举办一届,是CCF-A类会议。WWW 2020将于2020年4月20日至4月24日在中国台湾台北举行。由于疫情影响,这次会议在线上举行,本届会议共收到了1129篇长文投稿,录用217篇长文,录用率为19.2%。近期,随着会议的临近,有很多paper放出来,小编发现这次WWW 2020被图神经网络攻占,占比非常大,可见其火爆程度。这期小编继续为大家奉上WWW 2020五篇GNN相关论文供参考——图注意力主题模型、超图学习、图神经网络Hash、多视角图聚类、Graph Pooling。
WWW2020GNN_Part2、WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、KDD2019GNN、ACL2019GNN、CVPR2019GNN、ICML2019GNN
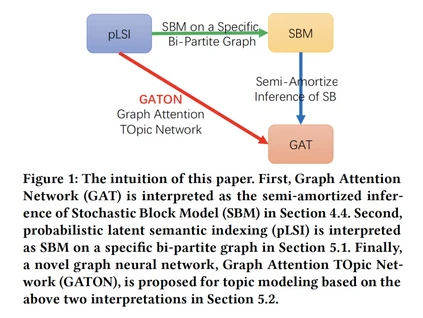
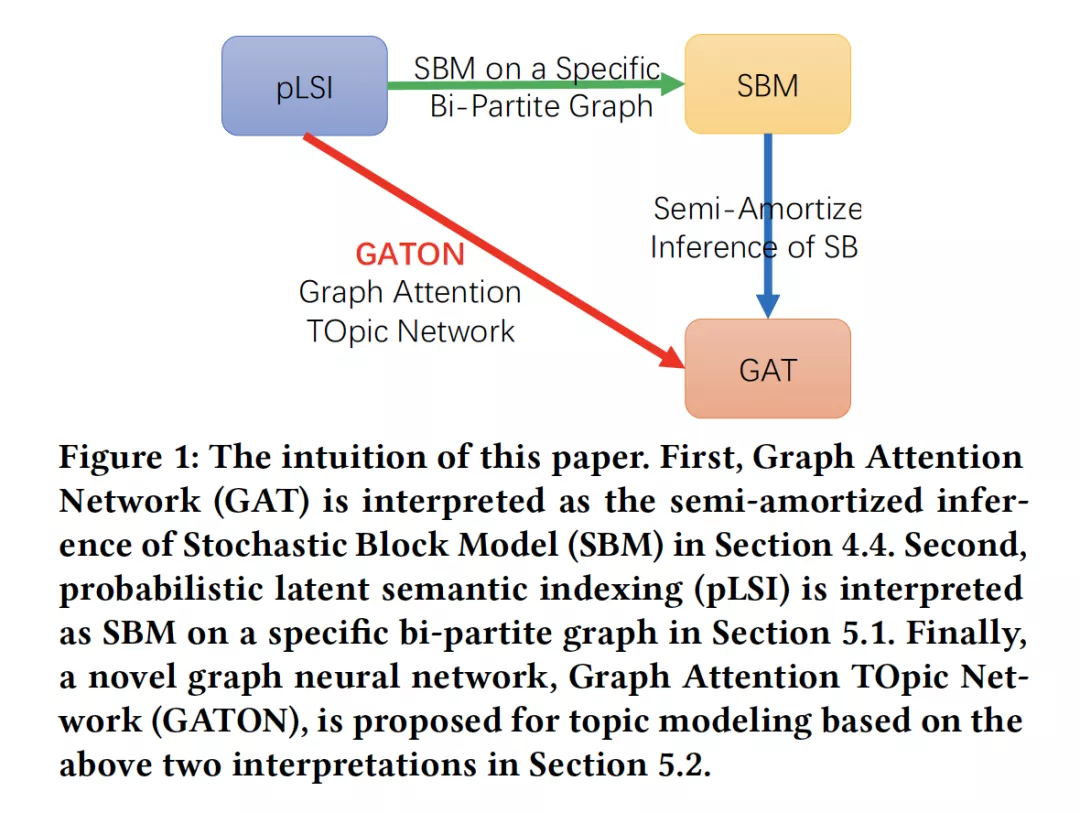
- Graph Attention Topic Modeling Network
作者:Liang Yang, Fan Wu, Junhua Gu, Chuan Wang, Xiaochun Cao, Di Jin, and Yuanfang Guo
摘要:现有的主题模型(topic modeling)方法存在一些问题,包括概率潜在语义索引模型(Probablistic Latent Semantic Indexing,PLSI)过拟合问题、隐狄利克雷分配(Latent Dirichlet Allocation,LDA)模型不能能捕捉主题间丰富的主题相关性与推理复杂度高等问题。本文提出了一种新的方法来克服pLSI的过拟合问题,用嵌入单词的平摊推理(amortized inference)作为输入,代替LDA中的狄利克雷先验。对于生成性主题模型,大量的自由隐变量是过拟合的根源。为了减少参数个数,平摊推理用一个具有共享(平摊)可学习参数的函数代替了对隐变量的推理。共享参数的数量是固定的,并且与语料库的规模无关。为了克服平摊推理在独立同分布(I.I.D)数据中应用的局限性,根据以下两个观察结果,我们提出了一种新的图神经网络--图注意力主题网络(GATON),用于对非I.I.D文档的主题结构进行建模。首先,pLSI可以解释为特定二分图上的随机块模型(SBM)。其次,图注意力网络(GAT)可以解释为SBM的半平摊推理(semi-amortized inference),它放宽了I.I.D数据的vanilla 平摊推理假设。GATON提供了一种新颖的基于图卷积运算的方案,去聚合单词相似度和单词共现结构。具体地说,词袋文档表示被建模为二分图拓扑。同时,将捕获词相似性的词嵌入建模为词节点的属性,并采用词频向量作为文档节点的属性。基于加权(注意力)图卷积操作,词共现结构和词相似度模式被无缝地集成在一起进行主题识别。大量实验表明,GATON在主题识别方面的有效性不仅有利于文档分类,而且能显著细化输入词的嵌入。
网址:https://yangliang.github.io/pdf/www20.pdf
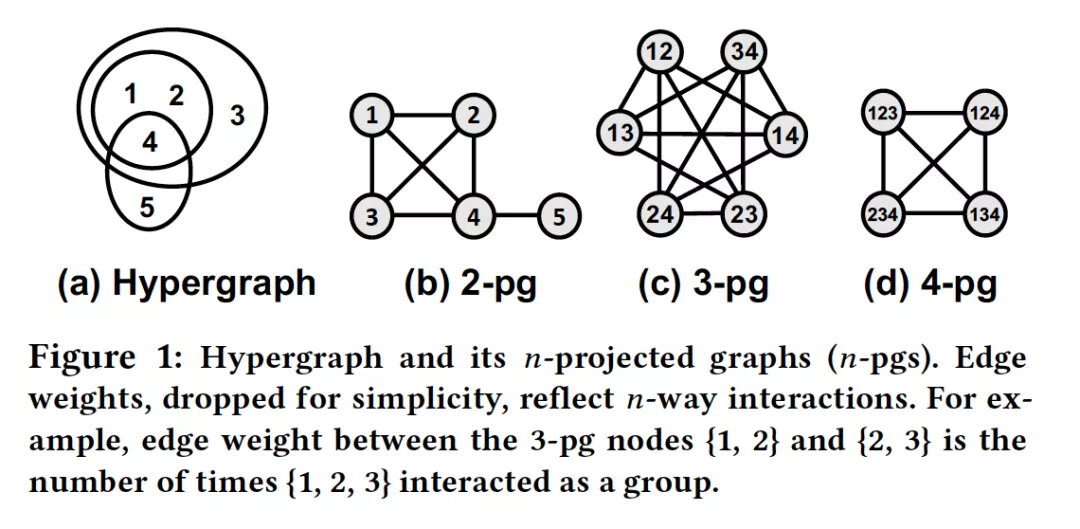
- How Much and When Do We Need Higher-order Information in Hypergraphs? A Case Study on Hyperedge Prediction
作者:Se-eun Yoon, Hyungseok Song, Kijung Shin, and Yung Yi
摘要:超图提供了一种自然的表示组群关系的方法,其复杂性促使大量先前的工作采用某种形式抽象和简化高阶交互。然而,以下问题尚未得到解决:在解决超图任务时,组群间交互的抽象程度需要多大?这些结果在不同的数据集中会有多大的不同?如果这个问题可以回答,将为如何在解决下游任务的复杂性和准确性之间权衡提供有用的工程指南。为此,我们提出了一种使用n投影图( n-projected graph )的概念递增表示群组交互的方法,该图的累积量包含多达n种交互作用的信息,并随着各种数据集的增长,量化解决任务的准确性。作为下游任务,我们考虑超边预测,它是连接预测的扩展,是评估图模型的典型任务。通过在15个真实数据集上的实验,我们得出了以下信息:(a)收益递减:较小地n足以获得与接近完美近似值相当的精度,(b)疑难解答:随着任务的挑战性越来越大,n带来了更多好处,(c)不可约性:当成对抽象化时,其成对交互并不能充分说明高阶交互的数据集将失去很多准确性。
网址:https://arxiv.org/pdf/2001.11181.pdf
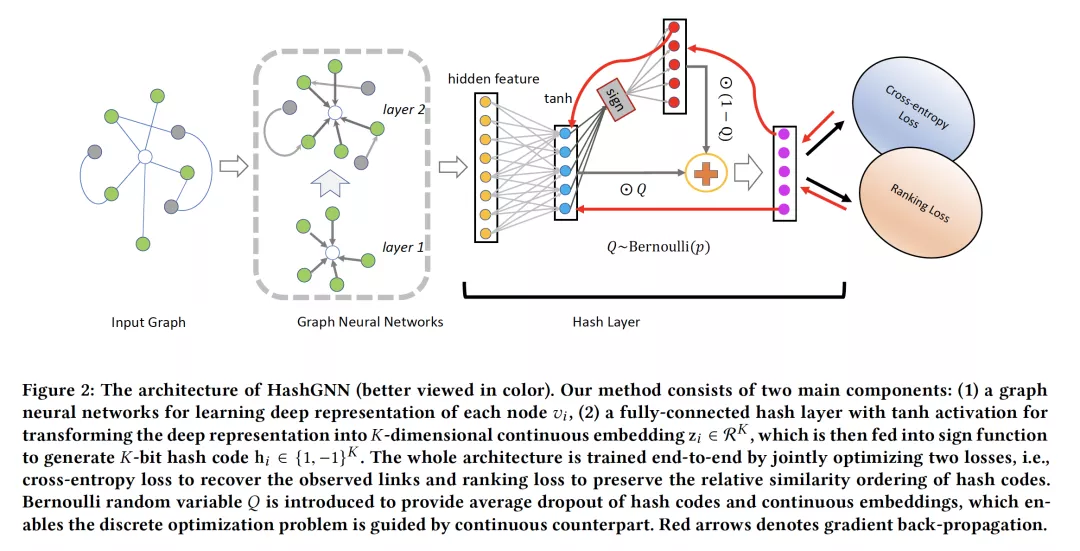
- Learning to Hash with Graph Neural Networks for Recommender Systems
作者:Qiaoyu Tan, Ninghao Liu, Xing Zhao, Hongxia Yang, Jingren Zhou, and Xia Hu
摘要:工业推荐系统一般包括两个阶段:召回和排名。召回是指从海量的项目语料库中高效地识别出数百个用户可能感兴趣的候选项目,而排名的目标是使用复杂的排名模型输出精确的排名列表。近年来,图表示学习在支持大规模高质量候选搜索方面受到了广泛关注。尽管它在用户-项目交互网络中学习对象的嵌入向量方面是有效的,但在连续嵌入空间中推断用户偏好的计算代价是巨大的。在这项工作中,我们研究了基于图神经网络(GNNs)的哈希高质量检索问题,并提出了一种简单而有效的离散表示学习框架来联合学习连续与离散编码。具体地说,提出了一种基于GNN的深度哈希算法(HashGNN),它由两部分组成,一个是用于学习节点表示的GNN编码器,另一个是用于将表示编码为哈希码的哈希层。整个框架通过联合优化以下两个损失进行端到端的训练,即通过重建观察到的连接而产生的重建损失,以及通过保留哈希码的相对顺序产生的排序损失。我们还提出了一种基于直通估计器(straight through estimator ,STE)指导的离散优化策略。其主要思想是在连续嵌入指导下避免STE的反向传播中的梯度放大,在这种情况下,我们从学习一个更容易模仿连续嵌入的更简单的网络开始,并使其在训练过程中发展直至最终返回STE。在三个公开可用数据集和一个真实的阿里巴巴公司数据集的综合实验表明,我们的模型不仅可以达到连续模型的性能,而且在推理过程中运行速度快了好几倍。
网址:https://arxiv.org/pdf/2003.01917.pdf
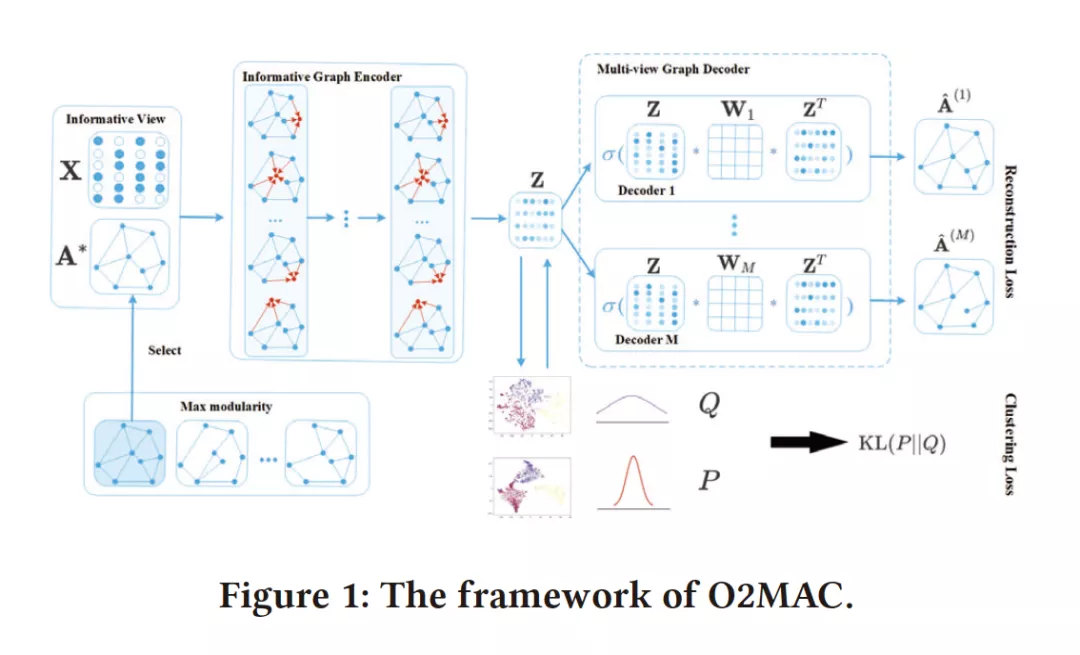
- One2Multi Graph Autoencoder for Multi-view Graph Clustering
作者:Shaohua Fan, Xiao Wang, Chuan Shi, Emiao Lu, Ken Lin, and Bai Wang
摘要:多视图图聚类(Multi-view graph clustering)近年来受到了相当大的关注,它是一种寻找具有多个视图的图的分割方法,通常提供更全面但更复杂的信息。虽然多视图图聚类已经做了一些努力并取得了较好的效果,但大多数都是采用浅层模型来处理多视图间的复杂关系,这可能会严重限制多视图的图信息建模能力。本文首次尝试将深度学习技术应用于属性多视图图聚类,提出了一种新的任务导向的One2Multi图自编码器聚类框架。One2Multi图自编码器能够通过使用一个信息丰富的图形视图和内容数据来重建多个图形视图来学习节点嵌入。因此,可以很好地捕捉多个图的共享特征表示。在此基础上,我们还提出了一种自训练聚类目标,以迭代地改善聚类结果。通过将自训练和自编码器重构集成到一个统一的框架中,我们的模型可以联合优化适用于图聚类的簇标签分配和嵌入。在真实属性多视图图数据集上的实验很好地验证了该模型的有效性。
网址:http://www.shichuan.org/doc/83.pdf
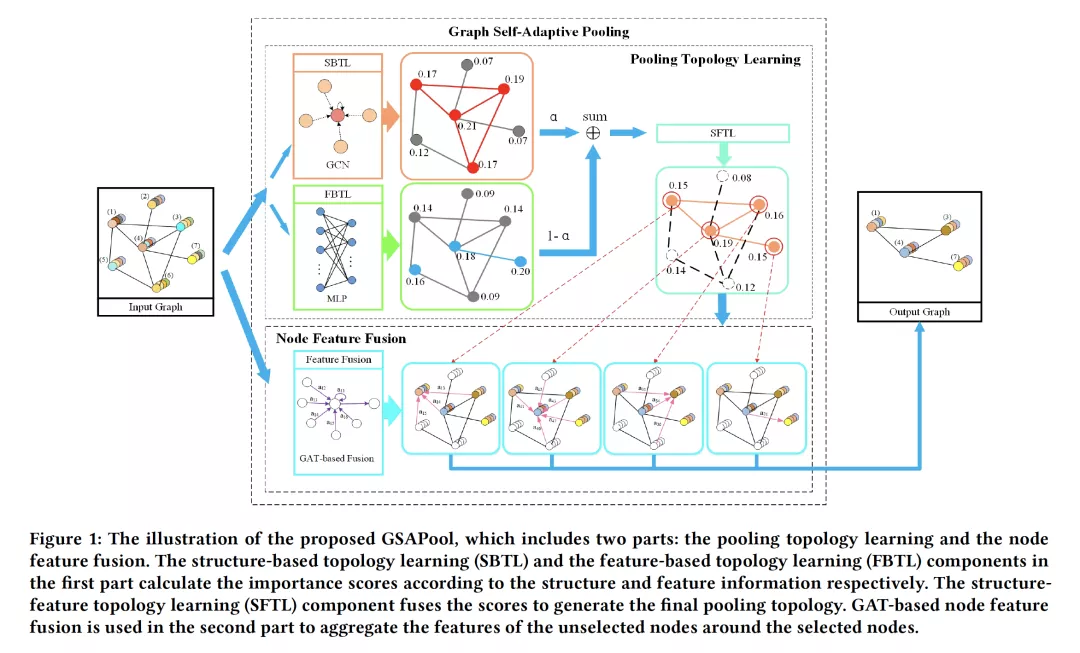
- Structure-Feature based Graph Self-adaptive Pooling
作者:Liang Zhang, Xudong Wang, Hongsheng Li, Guangming Zhu, Peiyi Shen, Ping Li, Xiaoyuan Lu, Syed Afaq Ali Shah, and Mohammed Bennamoun
摘要:近年来,人们提出了各种处理图数据的方法。然而,这些方法大多侧重于图的特征聚合,而不是图的池化。此外,现有的top-k选择图池化方法存在一些问题。首先,在构建池化图拓扑时,现有的top-k选择方法只从单一的角度评价节点的重要性,这是简单化和不客观的。其次,未选中节点的特征信息在池化过程中直接丢失,必然导致大量的图特征信息丢失。为了解决上述问题,我们提出了一种新颖的图自适应池化方法,目标如下:(1)为了构造合理的池化图拓扑,同时考虑了图的结构信息和特征信息,增加了节点选择的准确性和客观性;(2)为了使池化的节点包含足够有效的图信息,在丢弃不重要的节点之前,先聚合节点特征信息;因此,所选择的节点包含来自邻居节点的信息,这可以增强未选择节点的特征的使用。在四个不同的数据集上的实验结果表明,我们的方法在图分类中是有效的,并且优于最新的图池化方法。