表格问答2:模型

先说一个小插曲。昨天的文章大概介绍了一下NL2SQL问题及数据集,文章发出之后有百度的大佬回复我说正在进行的2020语言与智能技术竞赛[1]有语义解析赛道,百度精心准备了一个高质量的NL2SQL数据集,感兴趣的朋友可以关注一下。
数据集包含200个Database以及对应的2.3979万对(question, SQL query),其中18602对用于训练集,2039用于验证集,3156用于测试集。200个Database来自百科infobox、百科表格数据、以及互联网上存在的表格数据。每个Database包含若干张表格(2-11张,平均4.1张),人工构建了表之间的链接操作(即foreign key)。为了验证解析算法Database无关性及question无关性,在训练集合和测试集合的Database无交叉。
——2020语言与智能技术竞赛:语义解析任务
说回正题,今天我们将介绍两个NL2SQL模型,X-SQL和HydraNet。它俩都来自微软,分别推出于2019年和2020年。X-SQL跟它之前的方案比如SQlNET[2]、SQLOVA[3]都比较像,很有代表性;HydraNet对前人解决问题的大框架做了一些修改,变得更加简洁,也更符合预训练语言模型的使用习惯,应该会给大家一点启发。
为了方便大家阅读,我们先来回顾一下WikiSQL的预测目标。WikiSQL数据集进一步把SQL语句结构化(简化),分成了conds,sel,agg三个部分。
-
sel是查询目标列,其值是表格中对应列的序号; -
agg的值是聚合操作的编号,可能出现的聚合操作有['', 'MAX', 'MIN', 'COUNT', 'SUM', 'AVG']共6种; -
conds是筛选条件,可以有多个。每个条件用一个三元组(column_index, operator_index, condition)表示,可能的operator_index共有['=', '>', '<', 'OP']四种,condition是操作的目标值,这是不能用分类解决的目标。
X-SQL模型
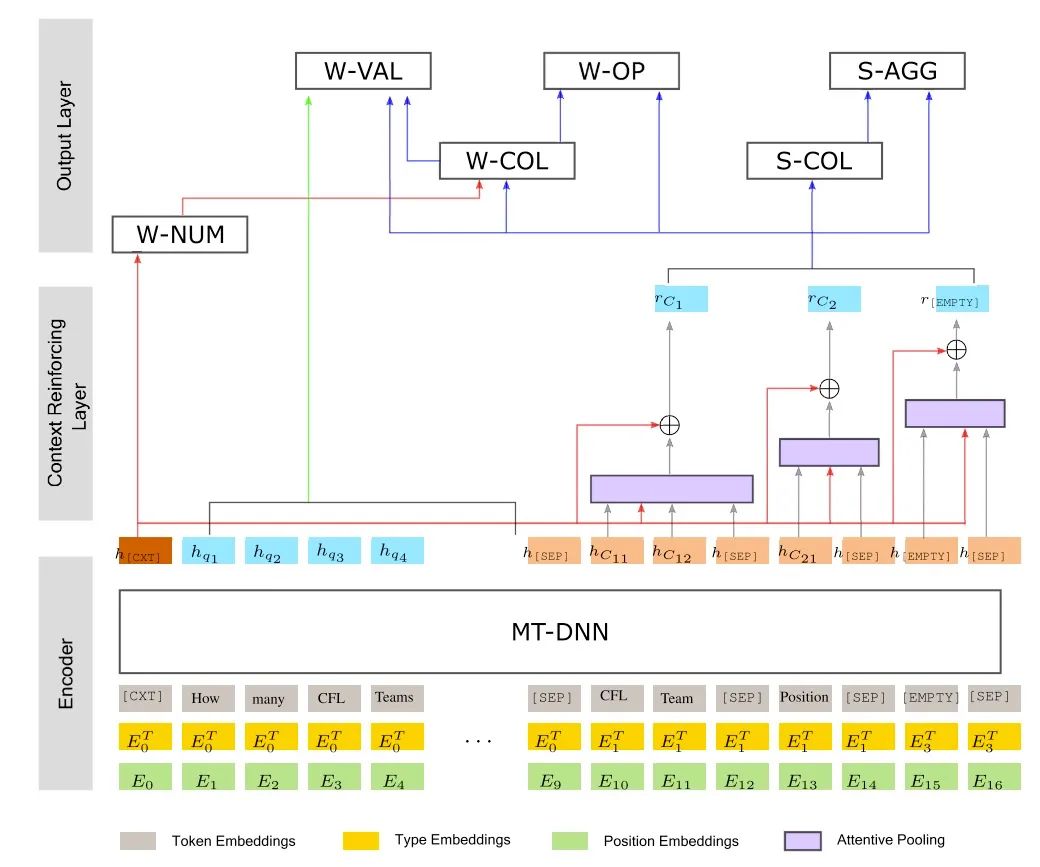
上图是X-SQL的模型结构图,乍一看还是挺复杂的。模型主要分为三层,编码器、上下文强化层和输出层,我们逐层来解析。
编码器是模型的基础,使用的是同样来自微软的改良版BERT——MT-DNN[4]。这部分的重点是它构造输入的方式,X-SQL的输入序列是由自然语言问题(Query)和各列的名称用[SEP]拼接而成的。为了处理conds为空的情况,模型引入了一个特殊列,用[EMPTY]来表示。模型还把原来BERT的Segment Embedding扩展成了图中黄色的Type Embedding。原来的segment token只有0和1两种,而type扩展成了4种,分别表示query,数值列,文本列和特殊的[EMPTY]列。为了突出引入的信息变多了,它们把原来的[CLS]token重新取名为[CTX]token。
中间是上下文增强层,主要是将每个列名对应的多个token输出的向量聚合并且在混入[CTX]token中的信息,得到一个列向量
。图中的例子对应的表格原本有两列,第一列名称包含两个token,第二个列包含一个token,加上了特殊列[EMPTY],总共3列。上下文增强层通过三个attentive pooling模块聚合成3个
向量。
输出层在最上面,可以看到输出层有六种子任务,分别是预测W-NUM(条件个数),W-COL(条件对应列,column_index),W-OP(条件运算符,operator_index),W-VAL(条件目标值,condition),S-COL(查询目标列,sel),S-AGG(查询聚合操作,agg)。
-
由于数据集中绝大多数标签的条件都不会超过4个, W-NUM的预测被建模为一个分类任务,直接取[CTX]token的输出加全连接,这个结果需要最先计算得到。 -
S开头的任务是预测查询目标,都是 分类任务。其中S-AGG是从可选的6种操作中选一个,S-COL是从所有的列中选一个。 -
W-OP和S-AGG对应,是从可选的4种条件操作种选一个;W-COL和S-COL对应,只不过不再是取 一个,而是取W-NUM个。 -
W-VAL任务被当做 阅读理解任务,因为这个值只能从query获取,所以和阅读理解一样,是一个span prediction任务,即预测value值的start/end position。
大家可以从图上看出每个任务的输入分别是什么,以及任务的计算顺序。对于大部分任务,训练时都是采用的交叉熵损失函数,但对于W-COL任务,训练时使用的是KL散度作为损失函数。整个方案既复杂又简单,复杂在于子任务多,而且有依赖关系;简单在于基本都是分类任务,更多细节大家可以参考论文[5]。
HydraNet
如果读懂了X-SQL,理解HydraNet[6]就很简单了。在X-SQL中,一次性把表格中的所有列都输入进了模型,因此需要做复杂的span pooling得到各列的向量表示,最后再计算下游任务。HydraNet返璞归真,本着少量多次的原则,一次只处理一个列。
表示层的输入变成了每个列的列文本和query文本组成的
对,其中列文本c包含了列的名称、类别和所属表名。列的类别只有两种,分别是string和real,这个信息在X-SQL中是用type embedding来注入模型的,但这里直接作为文本进行输入。这样对于每个列都是bert标准的sentence pair输入任务。
任务被分成了两大类:
-
与具体列有关的任务,如W-COL,W-OP,W-VAL。这些任务被建模成sentence pair输入的分类任务和阅读理解任务; -
与具体列无关的任务,如W-NUM和SEL-NUM。在X-SQL里由于一次输入了所有列,这俩可以一次性得到的;但由于HydraNet把列打散了,要么通过设定阈值来选取,要么需要对所有列的结果加权来得到。
以SEL-NUM为例,加权计算公式如下,其中 也对于每个<c, q>对的二分类任务输出的概率, 称为相关列(relavent column),即会出现在SQL语句中的列;而 是针对每个 对的多分类任务。
除了query和每个列的各个子任务结果,还需要对所有的列进行排序,选出那些最应该放入查询条件和查询目标的列。为了分别得到每个列对应select和where的顺位,使用两个不同的全连接层对每个
对的[CTX]token做进一步计算排序得分。
我们来看一下HydraNet的推理过程,一共分5步(论文里是4步):
-
计算每个 对的所有子任务结果; -
综合所有 对的结果得到W-NUM和SEL-NUM; -
对每个 对针对select进行排序,选出得分最高的SEL-NUM个列及其相关的agg作为条件; -
对每个 对针对where进行排序,选出得分最高的W-NUM个列及其相关的val、op作为条件; -
对于多表情况,综合多张表的前四步结果。
以上就是今天的所有内容,有一些细节大家可以参考论文原文,HydraNet的论文今年3月才放出,还很热乎。另外去年中文NL2SQL挑战赛的冠军队伍把他们的方案发了一篇IEEE论文[7],大家也可以参考。下一期我们将介绍几个表格问答的落地应用,不要错过哦。
参考资料
2020语言与智能技术竞赛语义解析赛道: https://aistudio.baidu.com/aistudio/competition/detail/30?isFromCcf=true
[2]SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning: http://arxiv.org/abs/1711.04436
[3]A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization: http://arxiv.org/abs/1902.01069
[4]Multi-Task Deep Neural Networks for Natural Language Understanding: http://arxiv.org/abs/1901.11504
[5]X-SQL: REINFORCE CONTEXT INTO SCHEMA REPRE-SENTATION: https://www.microsoft.com/en-us/research/uploads/prod/2019/03/X_SQL-5c7db555d760f.pdf
[6]Hybrid Ranking Network for Text-to-SQL: https://www.microsoft.com/en-us/research/uploads/prod/2020/03/HydraNet_20200311-5e69612887fcb.pdf
[7]M-SQL: Multi-Task Representation Learning for Single-Table Text2sql Generation: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9020099
推荐阅读
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





