教程 | 用数据做酷的事!手把手教你搭建问答系统
选自TowardsDataScience
作者:Priya Dwivedi
机器之心编译
参与:Pedro、路
本文介绍了如何基于 SQuAD 数据集搭建问答系统及其重要组件。
我最近很愉快地完成了斯坦福深度学习自然语言处理课程(CS224N),学到了很多新的东西。在结课项目中我基于斯坦福问答数据集(SQuAD)实现了一个问答系统。在这篇博客中,我将为大家介绍搭建问答系统所需要的主要模块。
完整代码 GitHub 地址:https://github.com/priya-dwivedi/cs224n-Squad-Project
SQuAD 数据集
斯坦福问答数据集(SQuAD)是一个全新的阅读理解数据集,由众包人员基于一系列维基百科文章的提问和对应的答案构成,其中每个问题的答案是相关文章中的文本片段或区间。SQuAD 包含关于 500 多篇文章的超过 100000 个问答对,规模远远超过其他阅读理解数据集。
最近一段时间,各种类型的模型在 SQuAD 数据集上的效果获得了快速的发展,其中最新的一些模型在问答任务中甚至取得了和人类相当的准确率。
SQuAD 数据集中的语境、问题和答案的示例
语境:阿波罗计划于 1962 至 1972 年间进行,期间得到了同期的双子座计划(1962 年 - 1966 年)的支持。双子座计划为阿波罗计划成功必需的一些太空旅行技术做了铺垫。阿波罗计划使用土星系列火箭作为运载工具来发射飞船。这些火箭还被用于阿波罗应用计划,包括 1973 年到 1974 年间支持了三个载人飞行任务的空间站 Skylab,以及 1975 年和前苏联合作的联合地球轨道任务阿波罗联盟测试计划。
问题:哪一个空间站于 1973 到 1974 年间承载了三项载人飞行任务?
答案:Skylab 空间站
SQuAD 的主要特点:
i) SQuAD 是一个封闭的数据集,这意味着问题的答案通常位于文章的某一个区间中。
ii) 因此,寻找答案的过程可以简化为在文中找到与答案相对应部分的起始索引和结束索引。
iii) 75% 的答案长度小于四个单词。
机器理解模型关键组件
i) 嵌入层
该模型的训练集包括语境以及相关的问题。二者都可以分解成单独的单词,这些单词会被转换成使用预训练向量(如 GloVe)的词嵌入。想了解更多关于词嵌入的信息,参考《教程 | 用数据玩点花样!如何构建 skim-gram 模型来训练和可视化词向量》。同 one hot 向量相比,用词嵌入方式对单词进行表示可以更好地捕捉语境信息。考虑到没有足够的数据,我使用了 100 维的 GloVe 词嵌入并且在训练过程中没有对它们进行修改。
ii) 编码器层
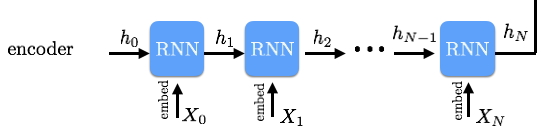
RNN 编码器
我们将基于 RNN 的编码器加入到了模型的下一层当中。我们希望语境中的每一个单词能和它前后的单词产生联系。双向 GRU/LSTM 可以帮助我们达到这一目标。RNN 的输出是一系列向前、向后的隐藏向量,然后我们会将它们级联起来。类似地,我们可以使用相同的 RNN 编码器创建问题隐藏向量。
iii)注意力层
现在我们有了一个语境隐藏向量和问题隐藏向量。我们需要将这两个向量结合起来,以找到问题的答案。这时就需要用到注意力层。注意力层是问答系统的关键组成部分,因为它能帮助确定对于给定的问题我们应该「注意」文中的哪些单词。让我们从最简单的注意力模型开始:
点积注意力
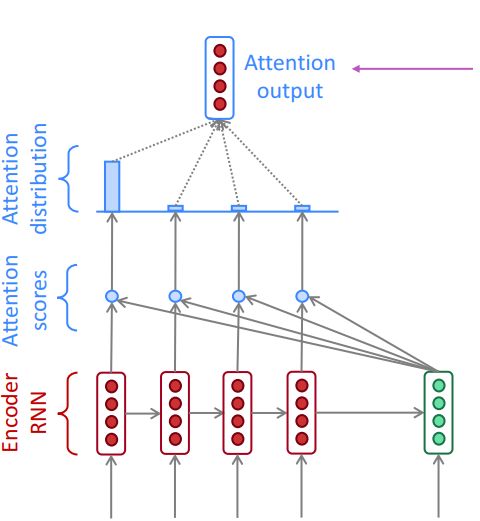
CS224N 中基本注意力的可视化分析
点积注意力等于每个语境向量 c_i 乘每个问题向量 q_j 的结果向量 e^i(上图中的注意力分数)。之后,我们对 e^i 调用 softmax 函数来得到 α^i(上图中的注意力分布)。softmax 保证了所有 e^i 的和是 1。最终,我们计算出 a_i:注意力分布 α^i 与对应问题向量(上图中的注意力输出)的积。点积注意力也可以用下面的式子来描述:
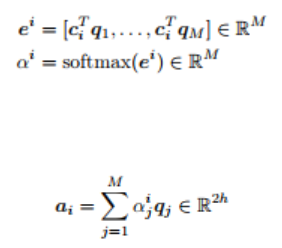
上面提到的注意力已作为基线注意力机制在 GitHub 代码中实现。
更复杂的注意力——BiDAF 注意力
你可以用上述基本注意力层来运行 SQuAD 模型,但恐怕结果不尽人意。更复杂的注意力才能产出更好的性能。
我们来了解一下 BiDAF 论文(https://arxiv.org/abs/1611.01603)。该论文的主要观点是注意力应该是双向的——从语境到问题和从问题到语境。
我们首先计算相似度矩阵 S ∈ R^N×M,它包含每对语境和问题隐藏状态 (c_i , q_j) 的相似度分数。这里
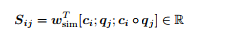
c_i ◦ q_j 代表数组元素对应相乘,w_sim ∈ R 6h 是权重向量。S_ij 用下面的式子来表述:
之后,我们将展示 C2Q 注意力(与上面提到的点积注意力类似)。我们对 S 逐行调用 softmax 函数来获得注意力分布 α^i,用它得到问题隐藏状态 q_j 的加权和,最后得出 C2Q 注意力的输出 a_i。
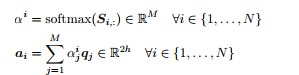
现在,我们来执行 Q2C 注意力。对于每一个语境位置 i ∈ {1, . . . , N},我们取相似度矩阵对应行的最大值:
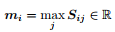
之后我们对结果向量 m ∈ R^N 调用 softmax 函数,而这将给出关于语境位置的注意力分布 β ∈ R^N。之后,我们使用 β 得到语境隐藏状态的加权和 c_i,这也是 Q2C 注意力的输出结果 c'。以下是相关公式:
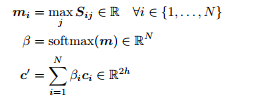
最终对于每一个语境位置 c_i,我们结合 C2Q 注意力和 Q2C 注意力的输出,下面是相关公式:
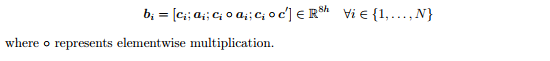
如果你觉得这一段令人费解,不用担心,注意力确实是一个复杂的话题。你可以试着一边喝茶,一边阅读这篇 BiDAF 论文。
iv) 输出层
我们就快成功了。模型的最后一层是一个 softmax 输出层,它帮助我们找出答案区间的开始和结束索引。我们通过结合语境隐藏状态和之前层的注意力向量来得到混合的结果。这些混合的结果最终会成为全连接层的输入,该层使用 softmax 来得到 p_start 向量(具备开始索引的概率)以及 p_end 结束(具备结束索引的概率)。我们知道大部分答案从开始索引到结束索引最多 15 个单词,由此我们可以寻找使 p_start 与 p_end 乘积最大的开始和结束索引。
损失函数是开始和结束位置的交叉熵损失之和。它使用 Adam Optimizer 来获得最小值。
我构建的最终模型比上面描述的要复杂一点,在利用测试集测试时获得了 75 分的 F1 分数。还行!
下一步
关于未来探索的一些想法:
由于 CNN 运行起来比 RNN 快得多,并且更容易在 GPU 上并行计算,因此我最近一直都在用基于 CNN 的编码器而非上述 RNN 编码器进行实验。
其他的注意力机制,如 Dynamic Co-attention(https://arxiv.org/abs/1611.01604)

原文链接:https://towardsdatascience.com/nlp-building-a-question-answering-model-ed0529a68c54
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



