论文浅尝 | 基于知识图谱子图匹配以回答自然语言问题

Citation: Hu,S., Zou, L., Yu, J. X., Wang, H., & Zhao, D. (2018). Answering natural language questions by subgraph matching over knowledge graphs. IEEE Transactions on Knowledge & Data Engineering, PP(99), 1-1.
动机
对于基于知识图谱的事实性问答(KBQA),采用基于语法分析的方法,大致分为两个阶段:其一为问题理解,即将问题转换为 SPARQL 类型的结构化查询;其二为查询评分,即对产生的结构化查询进行置信度评分。在问答系统中,重点是解决第一阶段中的歧义性问题,即解决:第一,短语链接问题,即如何将自然语言问句中的短语链接到正确的实体/类/关系/属性上;第二,复合问题,即一个自然语言问题可能转换为多个知识图谱三元组,而这多个三元组如何组合,才正确表达了问题的意图,并由此得到正确答案。
因此,为了解决第一阶段的两个问题,本文提出基于图匹配的方法,将解决歧义问题与查询评分这两个阶段融合在一起,即当得到自然语言问题的一个正确匹配的查询子图时,歧义问题也已经同时解决了。本文为了将自然语言转换为查询图,提出了关系优先(relation-first)和点优先(node-first)的方法。前者从自然语言问句中,尽量抽取对应的关系,并从句法树中抽取实体来构成查询图;后者从问句中尽量抽取对应的实体,再对实体之间的边进行填充,来构成查询图。该方法不需要事先人工设立模板,且对复杂问句分析非常有效。
贡献
文章的贡献有:
(1)不同于已有的基于模板的工作,本文工作不需要预先设置模板;
(2)不同于已有的基于语义分析的工作,本文工作的将歧义性问题与查询评分问题融合成一个问题来解决;
(3)本文工作对于解决复杂问题非常有效,且对于句法依存树的使用具有容错率。
方法
本文的工作主旨,是建立一个与自然语言问句意图充分匹配的查询图Qs,这个查询图中可以存在具有歧义性的实体(以节点表示)或关系(以边表示)。当这个查询图被确定下来时,对应的结构化查询也被唯一确定。为了建立结构化查询,本文首先从问句中形成以自然语言成分组成的查询图Qs,再通过图Qs与知识图谱G的同构匹配,来得到结构化查询。本文的工作主要分为线下和线上部分,其中线上部分又分为关系优先(relation-first)和点优先(node-first)的方法。
⒈线下部分的工作
线下工作,主要是建立两个字典,分别用于实体-实体指称和关系-关系指称。
⒉线上部分的工作——关系优先框架(relation-first framework)
首先使用 Stanford Parser 将自然问句N转换为句法依存树 Y。由于在线下部分已经建立了关系指称词典,即每一个词都可能被不同的关系指称所包含,所以在关系优先框架中,对于 Y 中每一个词(节点)wi,先找到所有包含 wi 的关系指称,然后使用深度优先搜索算法来遍历Y中以wi为根的子树,并判断这个子树是否与当前关系指称一一匹配。如果一个关系指称中所有的字都在子树中出现,那么认为找到一个匹配的句法依存子树y,这个关系指称也是符合自然问句 N 的。
当得到关系指称之后,就需要找到与这个关系指称相联系的主语和宾语节点。本文根据统计分析,基于句法树中边的词性,而统计出属于“subject-like”的边,与“object-like”的边。分析关系指称与句法依存树,若在依存子树y中有点w是可以被匹配为类/实体,则认为这个w是关系指称的一个主语;否则,观察w与它的子节点中,是否被 subject-like 的边相连,若是的话,这个子节点就是这个关系指称的主语。同理,若 w 与子节点被 object-like 的边相连,那么关系指称的宾语就是这个子节点。如果经过这种规则处理,找不到对应的主语/宾语,那么就需要应用一些高阶规则。
如下图 1 所示,即一个寻找与关系指称相关的主/宾语节点的示例。
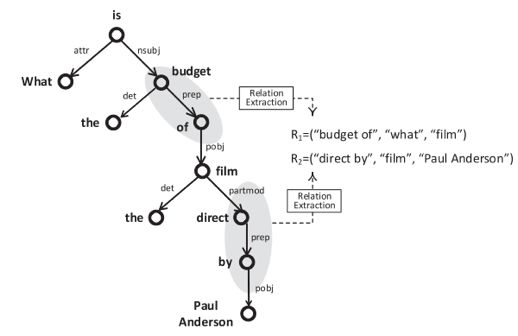
图1 关系抽取示例
如图 1,已知的关系指称为“budget of”与“direct by”,由于“file”是匹配于实体或类,且“of”与子节点“film”之间以object-like的边pobj相连,所以“film”是关系指称“budget of”的宾语。此外,虽然“is”与“budget”由subject-like的边相连,但是“is”并不是一个可以匹配到实体/类的节点,所以“is”不是“budget of”的主语。根据前面所述,与“budget of”最相近的wh-词是“what”,那么它就是“budget of”的主语。
以上的工作,是通过自然语言问句与句法树的分析,得到了查询图 Qs,后续需要再通过图 Qs 与知识图谱 G 的同构匹配,来得到结构化查询。
Qs 中每一条边都有匹配的候选谓词,而 Qs 中每一个节点都有匹配的候选实体或者类,且根据关系指称词典和实体指称词典,均有一个置信度得分。当 Qs 与知识图谱 G 进行匹配时,可以找到若干匹配的子图,从中找到分数最大的 top-k 子图,就是找到对应的结构化查询。再执行这个查询,就可以得到问题对应的答案。
⒊线上部分的工作——节点优先框架(node-first framework)
节点优先框架,是从自然语言问句中找到节点,再对填充节点之间的边。当填充边时,肯定会出现同一对节点之间以不同路径相连的问题,所以通过识别节点、再填充边的做法,形成的图为超语义查询图 Qu,而 Qs 是其一个子图。
首先用已有的方法识别出所有的实体指称,并且将所有wh-词和不能匹配到任何实体的名词作为通配符。比如对于例句“What is thebudget of the film directed by Paul Anderson and starred by a Chinese actor?”可以识别出“what”、“film”、“Paul Anderson”、“Chinese”、“actor”。
其次进行结构的建立。利用句法依存树,当两个节点之间没有其余节点存在,那么这两个节点之间即认为是有边或路径相连,即为一个关系指称,且路径上所有边的label组合成为这个关系指称。如下图 2 所示,点“film”与点“Paul Anderson”、“actor”之间都没有其余节点存在,所以“film”与“Paul Anderson”存在关系,关系指称为“directed by”;“film”与“actor”存在关系,关系指称为“directedstarred by”,由此得到了节点间的关系指称。当两个节点之间的指称没有label时,如图2的“Chinese”和“actor”,那么若两个节点都为实体/类,那么在知识图谱中将这两个节点间的关系填入;若其中一个节点为通配符,则在知识图谱中定位另外一个节点,取与其连接频数最高的那些谓词作为候选关系填入。
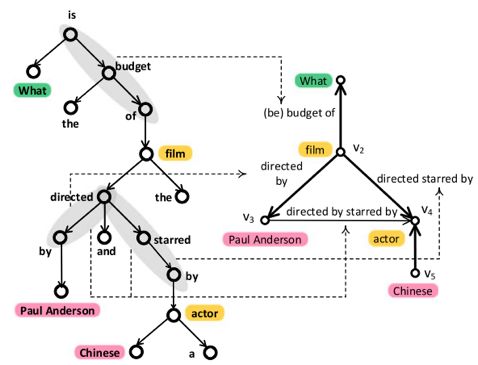
图 2 建立超语义查询图
经过关系填充,可以得到 Qu,而 Qu 中将包含所有节点,但以不同边连接所有节点的子图以 Si 表示。在将 Si 与结构化查询图进行匹配时,采用基于动态规划的自顶向下的方法来逐步扩展。即首先找到最可能匹配的部分子图 Q,再将与 Q 中节点相连的边逐一加入,并评估是否可以与知识图谱G中的子图匹配,若可以的话,则继续加入边到 Q,直到 Q 是 Qu 的包含了 Qu 所有节点的子图,那么就视为找到了一个语义查询图;若加入了一条边后,后续无法产生匹配,则需要回溯,把这条边从 Q 中删去,重新加一条新边,再进行迭代。
实验
实验使用了 QALD-6 数据集和 WebQuestions 数据集。QALD 中复杂问题较多,相比之下,WebQuestions 中的简单问题(一个问题可以由一个三元组表示)居多。
如图3所示的表格,在 QALD-6 的比赛中,NFF(节点优先框架)取得了第二名的成绩,而第一名的 CANaLI 需要用户手动输入实体和谓词,大大减少了系统难度,而 NFF/RFF 不需要这样的人工操作。
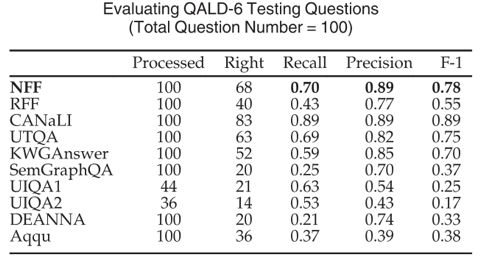
图3 QALD-6测试结果
从图 4 所示的表格可以见到,在 WebQuestions 的测试中,NFF 排在第三位,这是由于关系指称词典的覆盖率在 WebQuestions 较低导致。而且,本文系统更加由于复杂问题的处理,所以将 Aqqu 放到 QALD 中,其效果降低了很多,远远不及本文系统
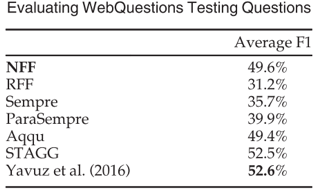
图4 WebQuestions测试结果
关于错误回答问题的分析,其一是由于词典中的未登录实体/类/关系,导致匹配错误;其二是对于聚集型问题,本文的方法无法回答。
总结
这篇文章,主要工作为:提出了一种基于图匹配的方法,来进行自然语言问题的回答。与之前的工作不同的是,在本文的工作中,实体识别、关系识别的歧义性问题是在查询评分的阶段中完成的,而之前的工作是将这两个阶段分开进行。由于是利用结构化查询图来进行答案检索以及解决歧义,这是个高效的方法。所以,基于图匹配的方法,不仅可以提高系统准确性(尤其是对于复杂问题),而减少了整个系统的响应时间。此外,这些工作都可以利用文本来进行工程化地实现,并不涉及复杂的神经网络模型,在应用或项目中,容易实现。
论文笔记整理:花云程,东南大学博士,研究方向为自然语言处理、深度学习、问答系统。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


