「图像编辑」太卷了!谷歌最新论文发布仅6小时就被自己砸了场子
![]()
新智元报道

新智元报道
【新智元导读】谷歌的生产力太猛了...

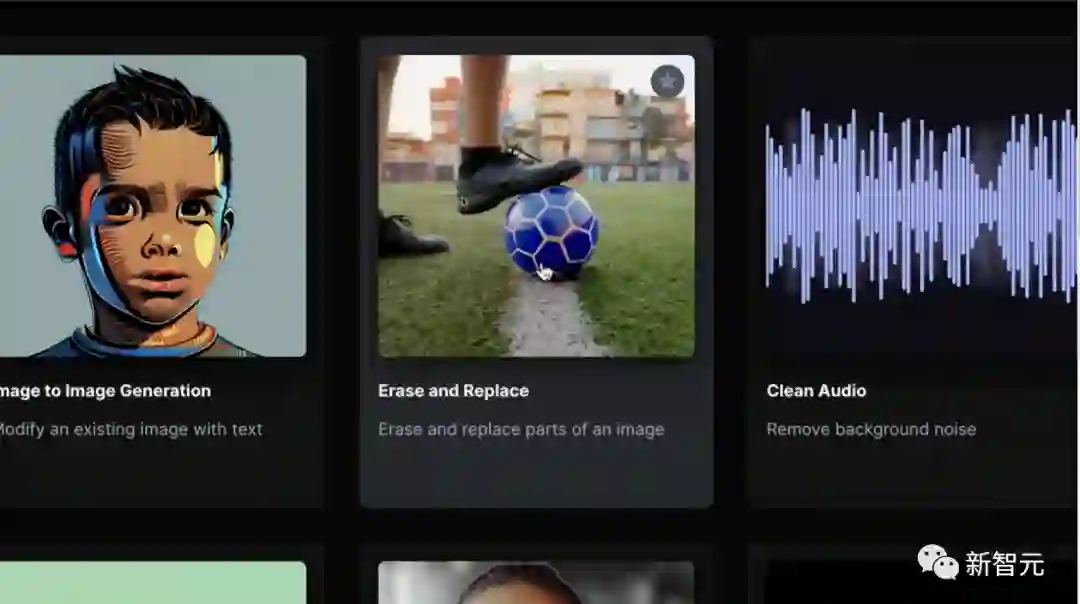




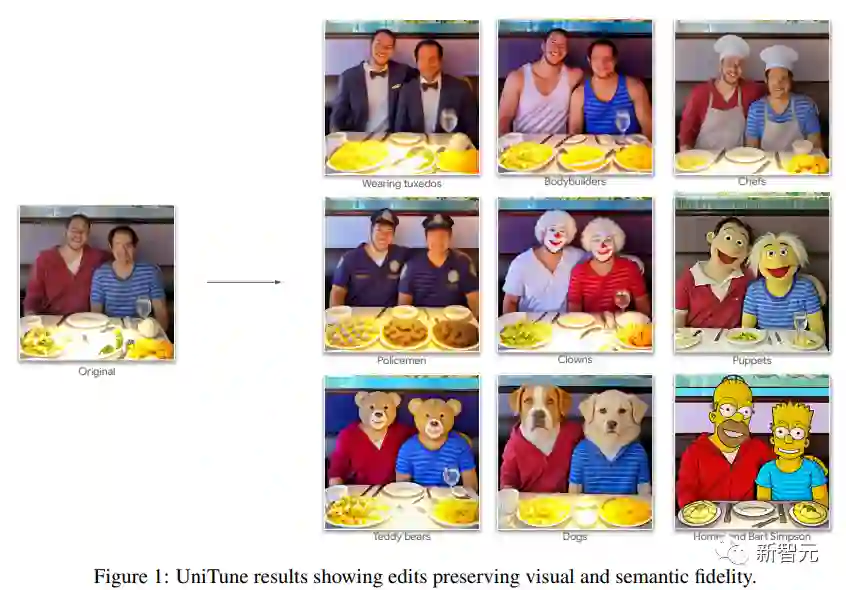
开箱即用的Runway
开箱即用的Runway

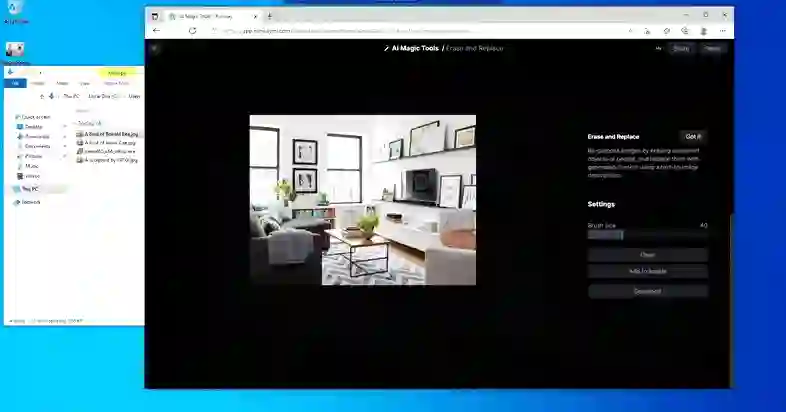

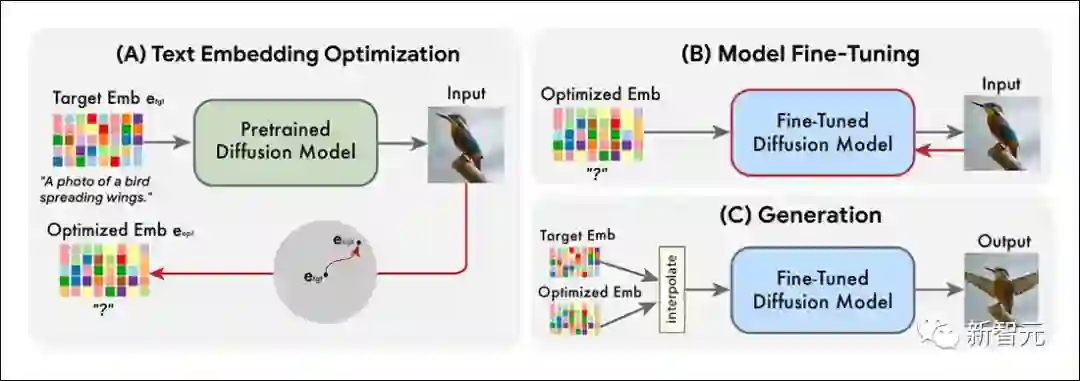
Imagic
Imagic








登录查看更多
相关内容

Arxiv
0+阅读 · 2022年12月12日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年12月12日