打造专属对话机器人,百度UNIT平台任务型对话体验
很多NLP爱好者都对多轮对话很感兴趣,晴天一号团队自然也不例外。国内大厂们动作很快,去年我们发现百度、微信都推出了自己的对话平台,阿里小蜜更是早已在内部生态中广泛应用。就在前不久(2月10号),百度UNIT上线了图形化对话流编辑器TaskFlow,引起了我们很浓厚的兴趣,今天就带大家一起体验一下百度大脑的UNIT。
事先声明,这不是UNIT的软文,我们希望以一个NLP爱好者的角度客观地体验一下这个产品。但如果百度的朋友们觉得这篇文章写的不错,欢迎赞赏支持
提示:这篇图多字小,请点击查看大图
UNIT的对话元素
百度UNIT平台的顶级元素是机器人,一个机器人可以理解成一个入口。机器人界面较简单,在此就不展示了。
第二层是技能,技能用来完成某个特定的功能。一个机器人可以绑定多个技能。“我的技能”界面如下图所示,可以看出系统预置了一些技能,这些技能一方面可以作为DEMO让用户更快地熟悉这个系统;另一方面可以让用户直接使用,从而更方便地构建出有趣的机器人。点击新建技能,可以发现UNIT把自定义技能分为两种类型:问答型和对话型。其实在NLP圈,这里所谓对话型技能更专业的名字应该叫“任务导向型(task-oriented)问答”,我们今天要体验的就是对话型技能。
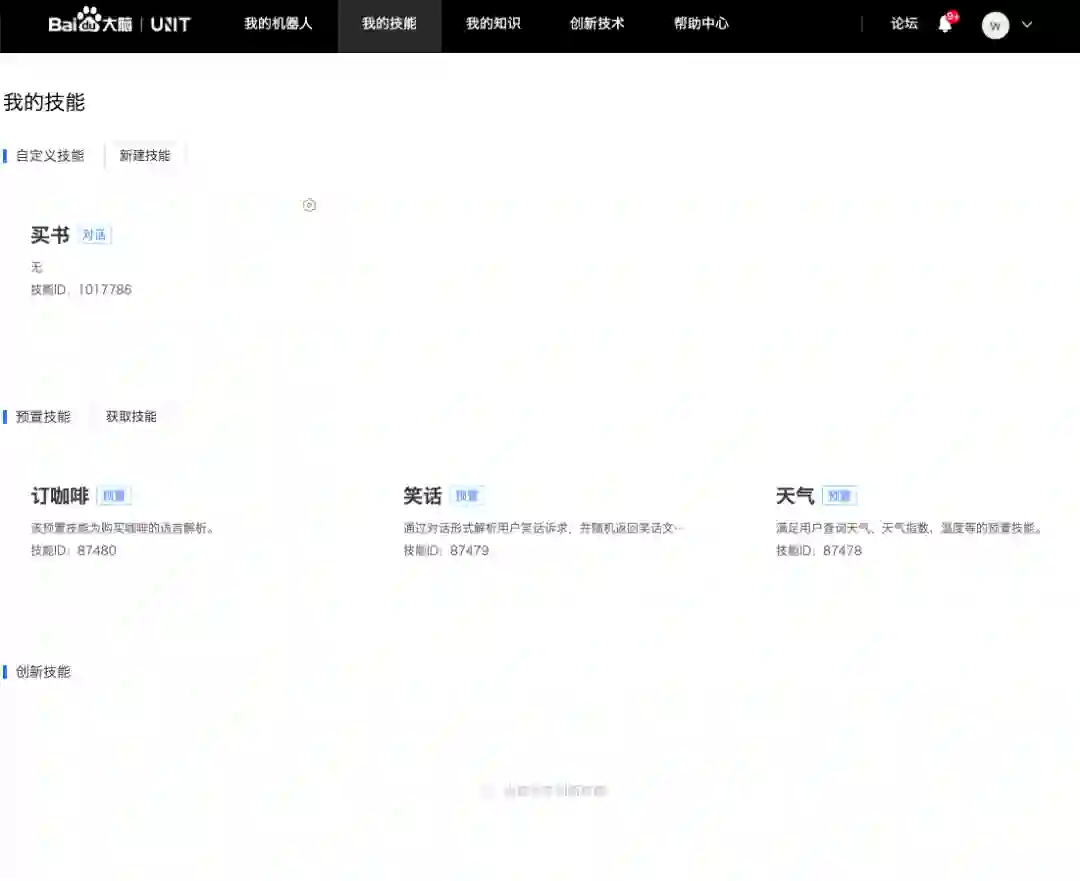
在每个UNIT的对话型技能里,用户可以定义多个意图(intent)。下图是技能编辑的默认界面,管理的就是意图。我个人是比较赞同这种建模逻辑的,要建立一个有效的机器人,必须首先对用户在特定对话空间内表达的意图有完整的把握。
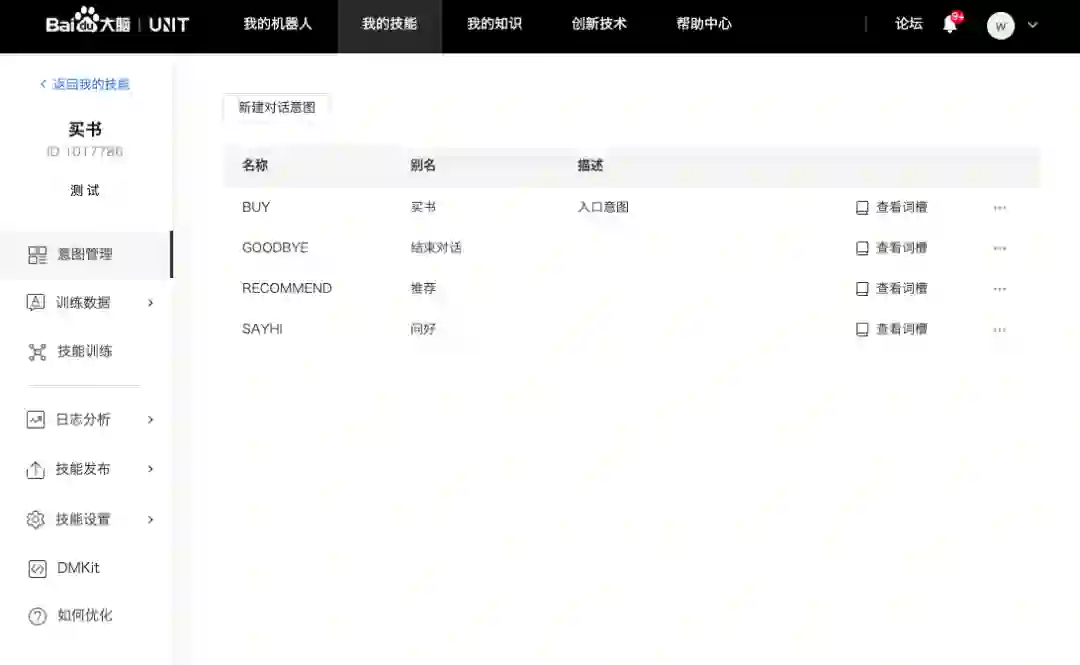
下图是意图编辑界面。在每个意图里,你需要定义它的基本信息、关联词槽和对话回应。
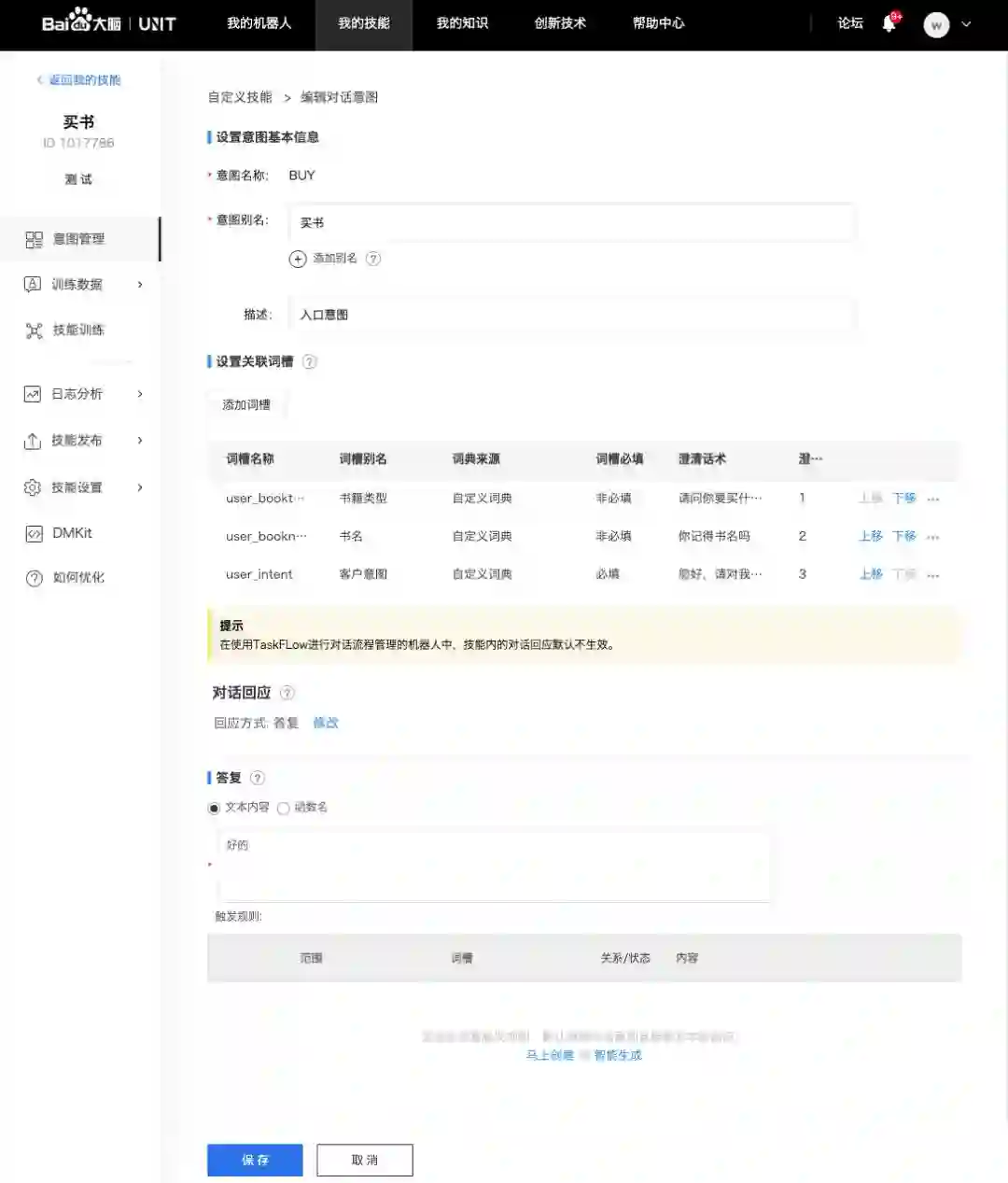
基本信息包括名称(名称只能使用英文)和别名(可以使用中文),如果你还意犹未尽,还可以写一段描述来帮助你区分不同意图。
词槽(slot)是在任务导向型问答里一个很重要的元素,通常是指为了完成用户指定的任务所需的关键信息。例如要完成一个查天气的任务,可能就需要指定地点和时间等等。
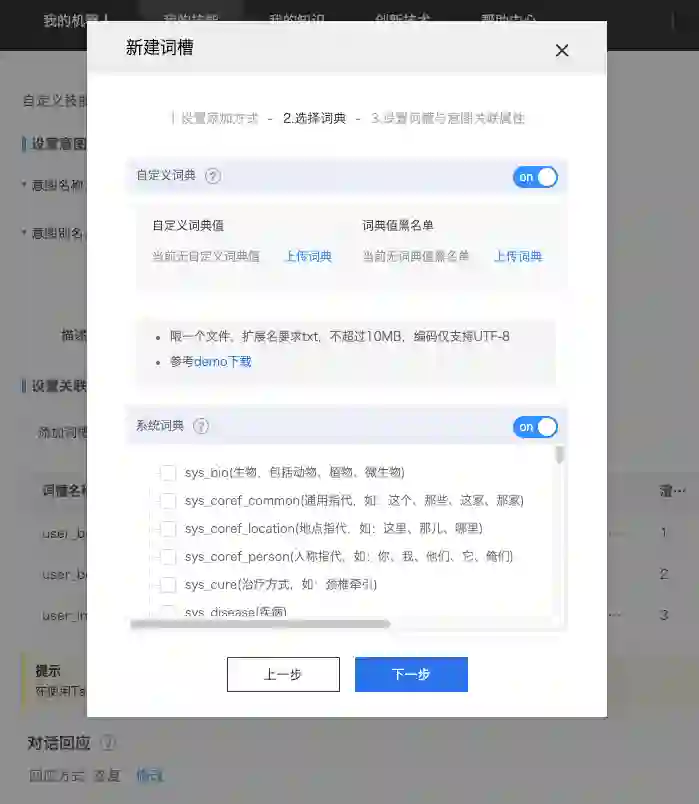
定义词槽的时候除了名称、别名等常规项外,需要给出一个词槽词典,词典中列举该词槽中可能出现的值,词典定义支持指定同义词近义词。这个词典除了可以由用户提供外,还可以选择系统的内置词典。从下图可以看出,系统词典是相当丰富的,除了名词,还包含了代词,百度在NLP领域的基本功在此可见一斑。为了防止误识别,还可以给出一个黑名单,在黑名单里的词不会识别为该词槽。
对话的回应方式有两种:“答复”和“引导至对话意图”。当选择答复型回应时需要进一步配置答复,答复可以是一段文本,也可以是一个函数名。但其实在我们今天要重点体验的TaskFlow模式下这里的设置并不会生效。
训练数据
定义好了各个元素之后还需要给模型输入一些训练数据。UNIT这个页面做的还是蛮好的,输入训练数据很便捷。对输入的句子,系统会自动分词,用户可以调节分词并且给句子标注意图和词槽值。由于时间有限,我们只准备了20几条数据。
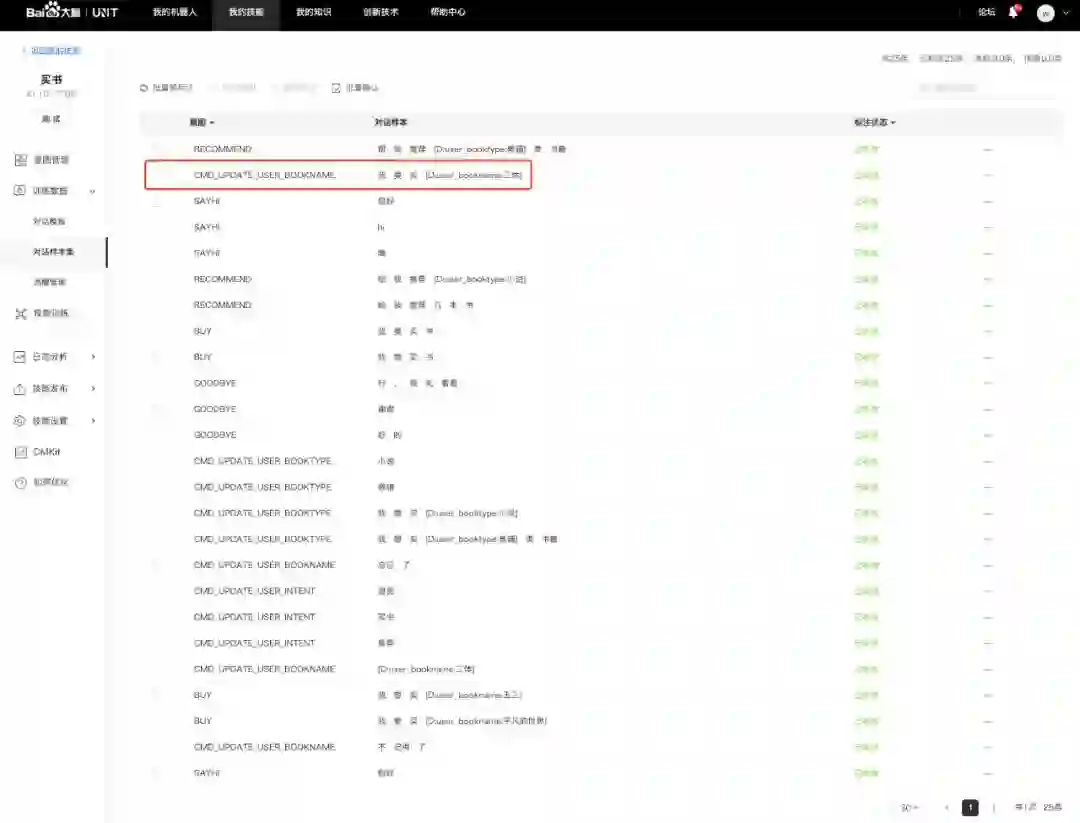
注意图中红框部分,系统会给每一个槽新建一个更新值的意图,名字叫CMD_UPDATE_USER_****,注意这个意图并没有跟母意图绑定。而实际上在TaskFlow里也确实可以自由使用一个技能内的所有槽。
TaskFlow
在建立机器人的时候选择TaskFlow就可以使用新的图形化对话流编辑器,利用它来对刚才定义好的对话元素进行高效直观地编排。
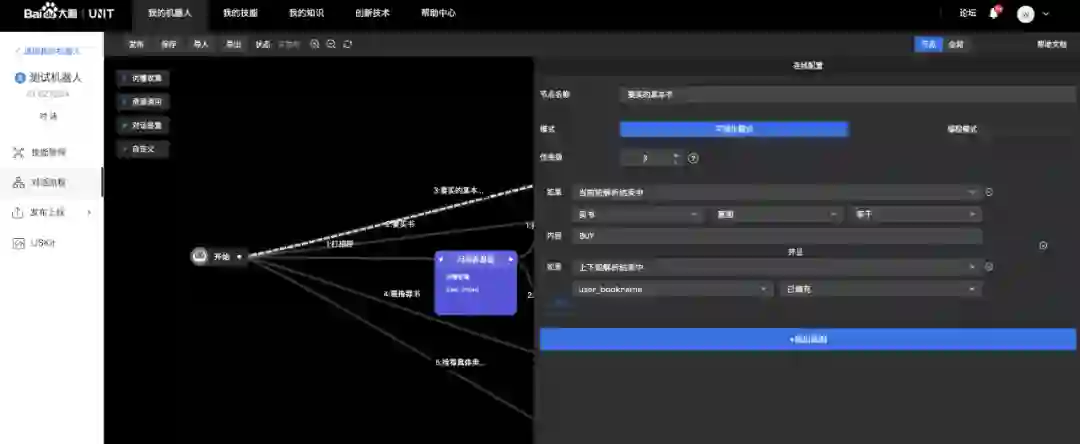
TaskFlow提供了四种模块,分别是词槽收集、资源调用、对话答复和自定义。自定义最好理解,就是在里面写python代码,但其他的几个模块也都可以自定义Python代码。每个模块有一个出口和入口,整个对话流由一个叫“开始”的内置模块启动。在模块间连线就可以建立对话流,而连线也是配置最丰富的地方。如下图所示,可以在连线中根据意图和槽的匹配结果来设置跳转的逻辑。
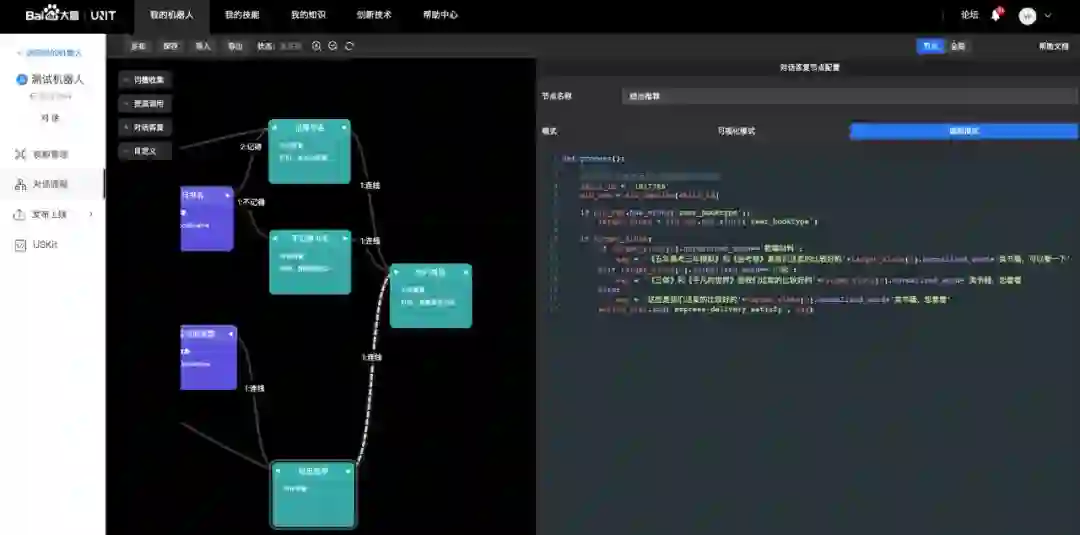
另外再讲一下TaskFlow的自定义代码功能,还是比较方便的,可以很容易实现一些逻辑。通过全局变量可以访问到NLU模块得到的意图和槽信息,下图是我们测试时的例子。
简易测试
为了进行测试,我们设计了一个简单的买书场景。一共定义了4个意图:SAYHI, BUY, RECOMMEND和GOODBYE。
-
SAYHI中定义了一个槽叫做user_intent,包含买书和推荐两个槽值; BUY定义了两个槽,为booktype和bookname,实际只使用了bookname这个槽,包含了一些书名;
RECOMMEND定义了一个槽,绑定的也是booktype字典,包含小说和教辅两个值;
GOODBYE用来识别客户例如“好的”,“再见”之类的结束语
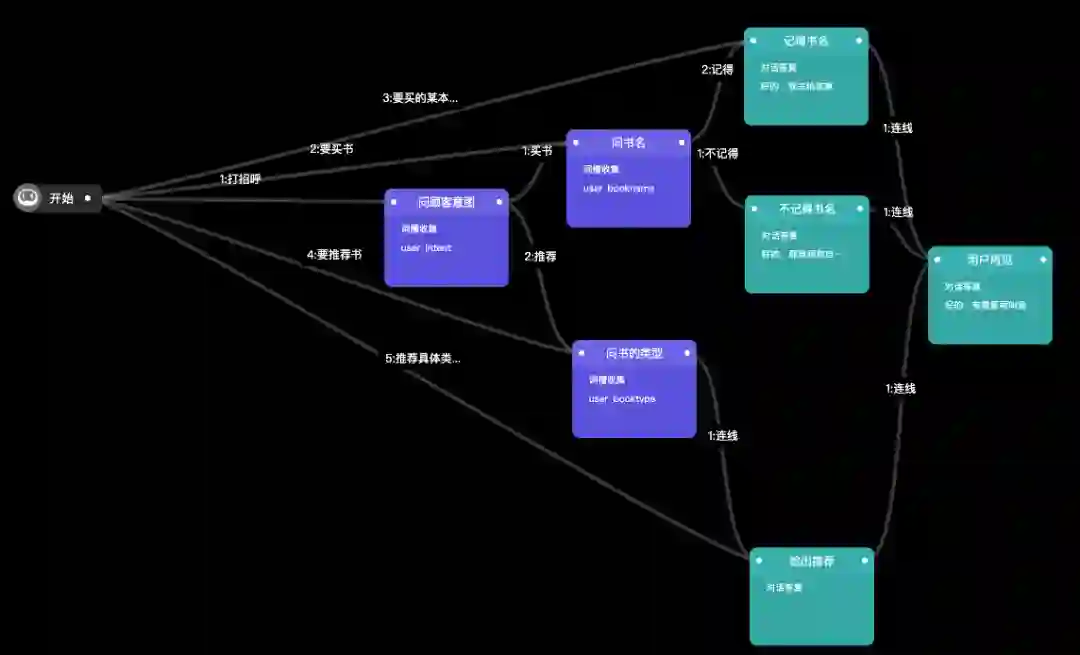
我们定义的对话流如上图所示,只用了槽值收集和对话回复两种模块。其他一些意图、词槽数据相关的信息可以在前面的图中找到。对话流应该总共有8条可能的路径,按照图上从上到下的顺序是:
-
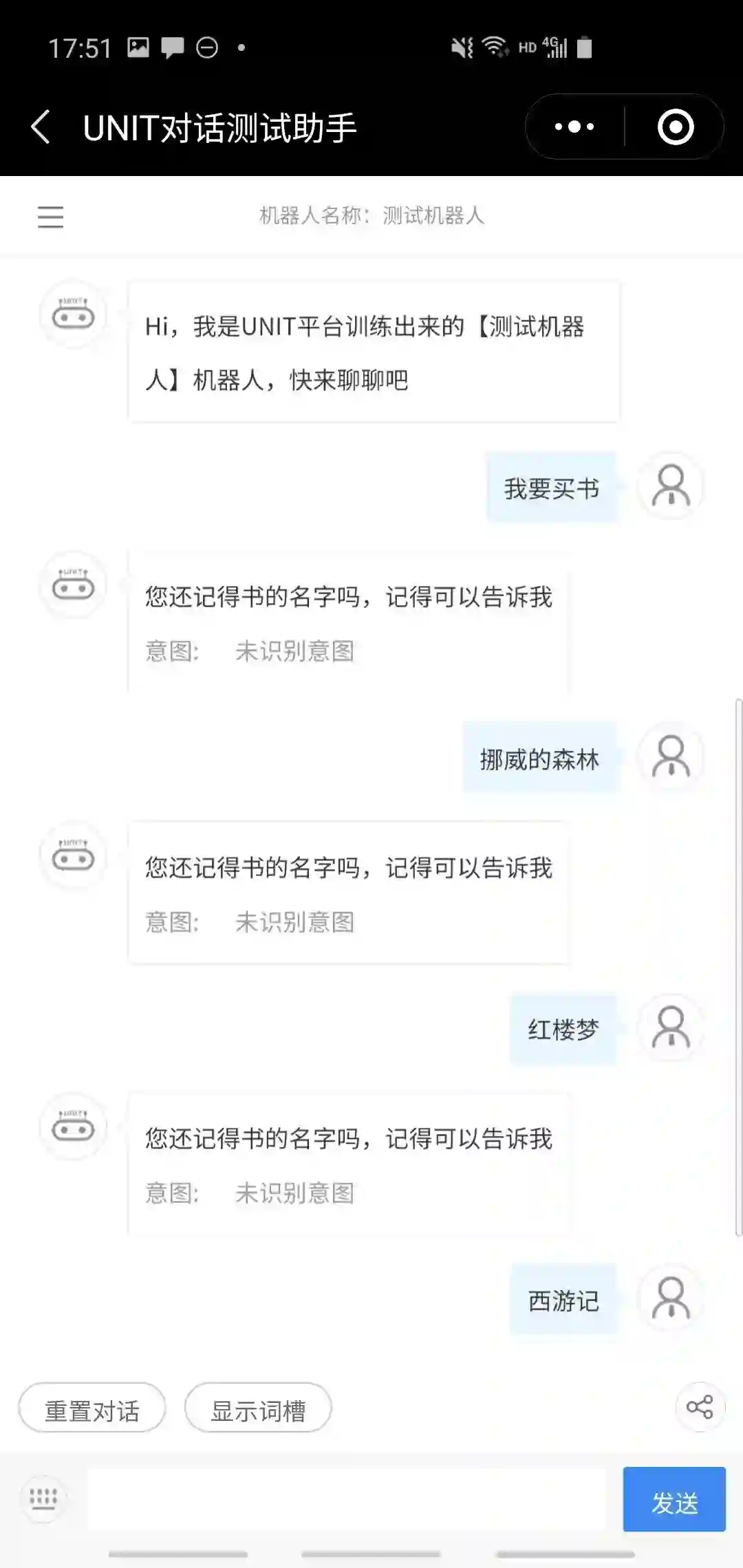
用户直接说要买某本书,返回“好的,帮你去取”; 用户直接说要买书,但没说书名,系统询问是否记得书名,若告知书名则结果同1,若说不记得,则返回“那你自己看看”;
用户SAYHI,系统询问意图是买书还是推荐,用户回答若是买书则同2,若是推荐则同4;
用户说帮我推荐书,系统询问推荐哪类书,用户回答后进入5;
用户直接说要推荐某类书,系统返回该类别中两本书的名字;
我们遍历了这几条路径,发现总体来说任务完成率还是很好的,基本都能顺利完成任务。考虑到我们提供的训练数据很少,这样的结果是比较令人满意的。下面几个是成功的案例。
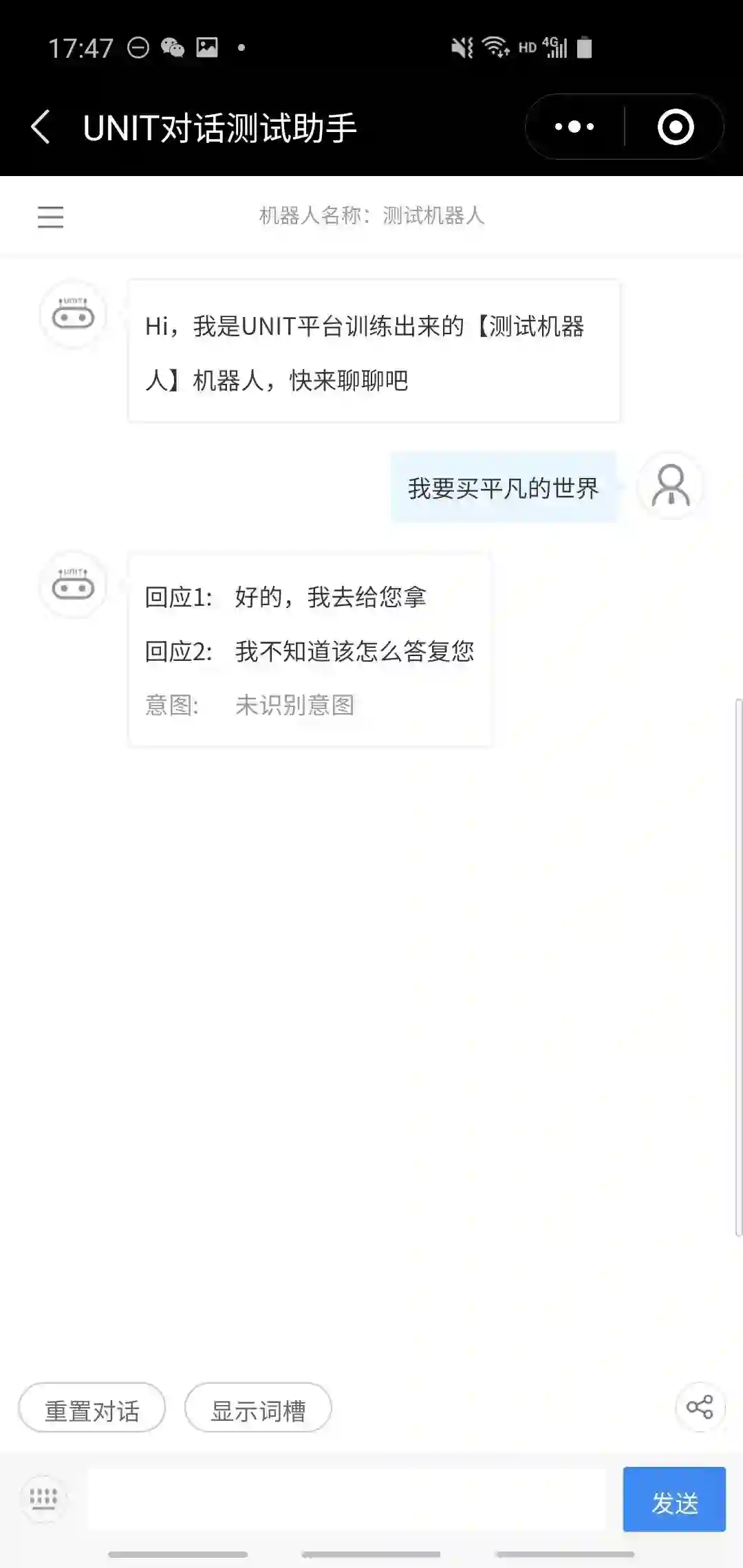
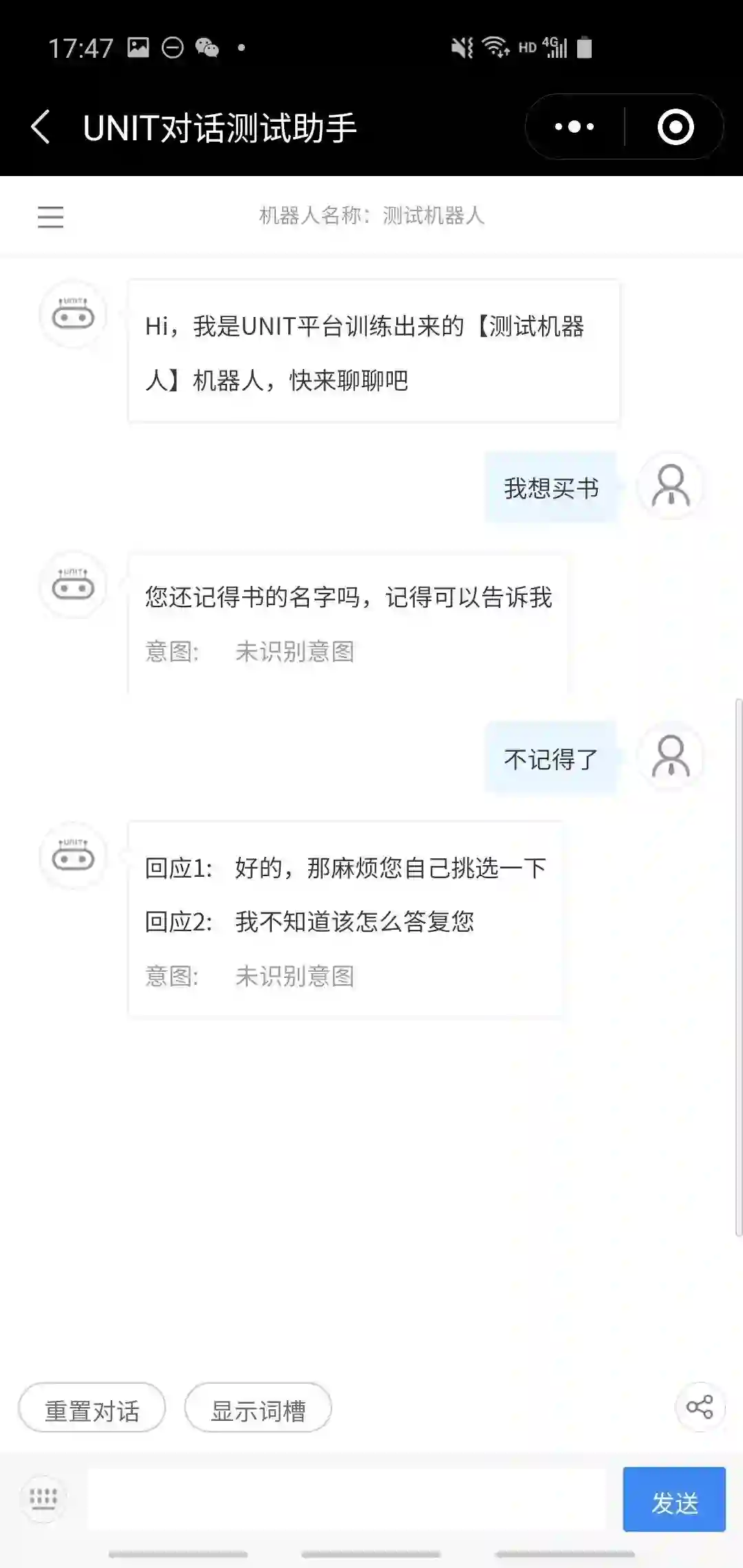
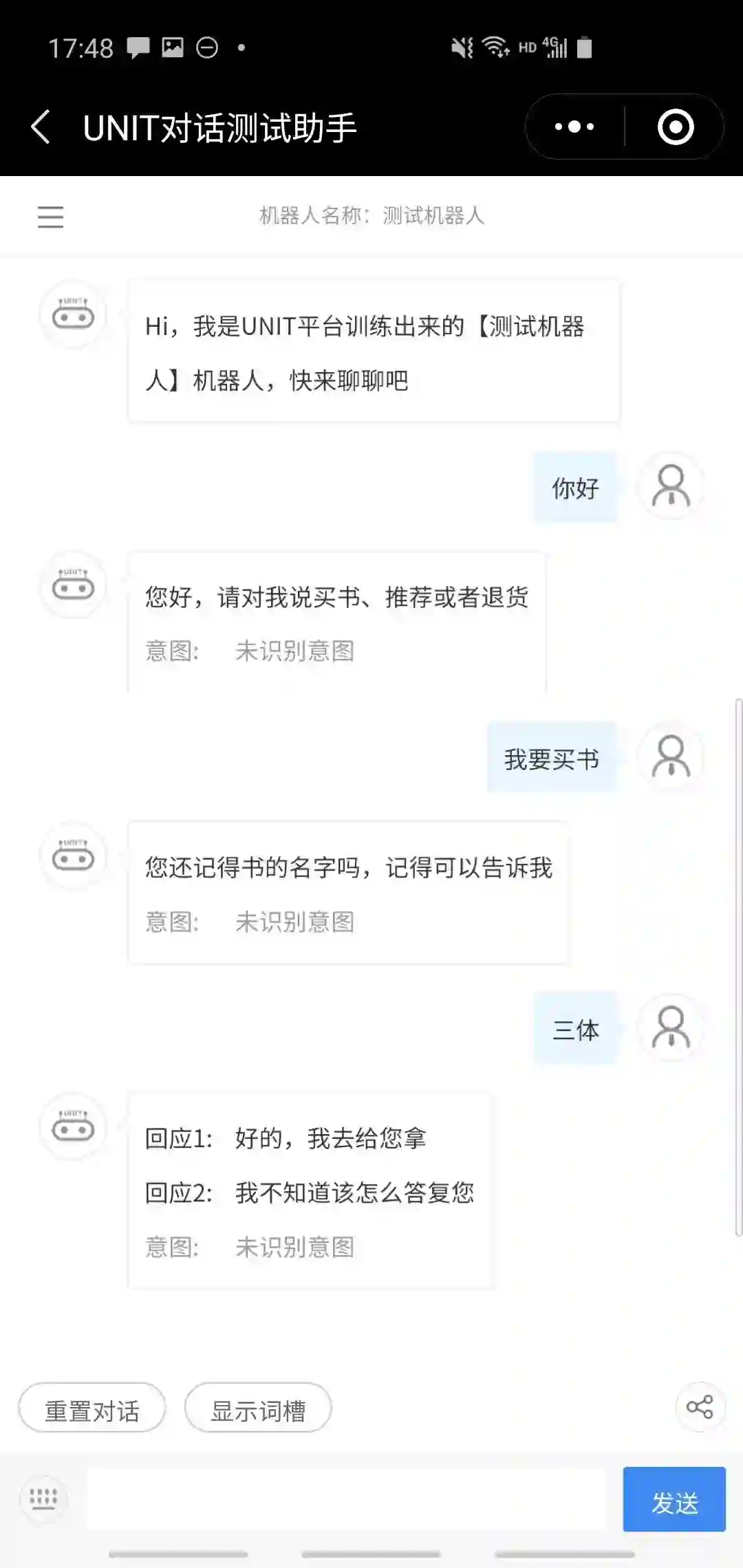
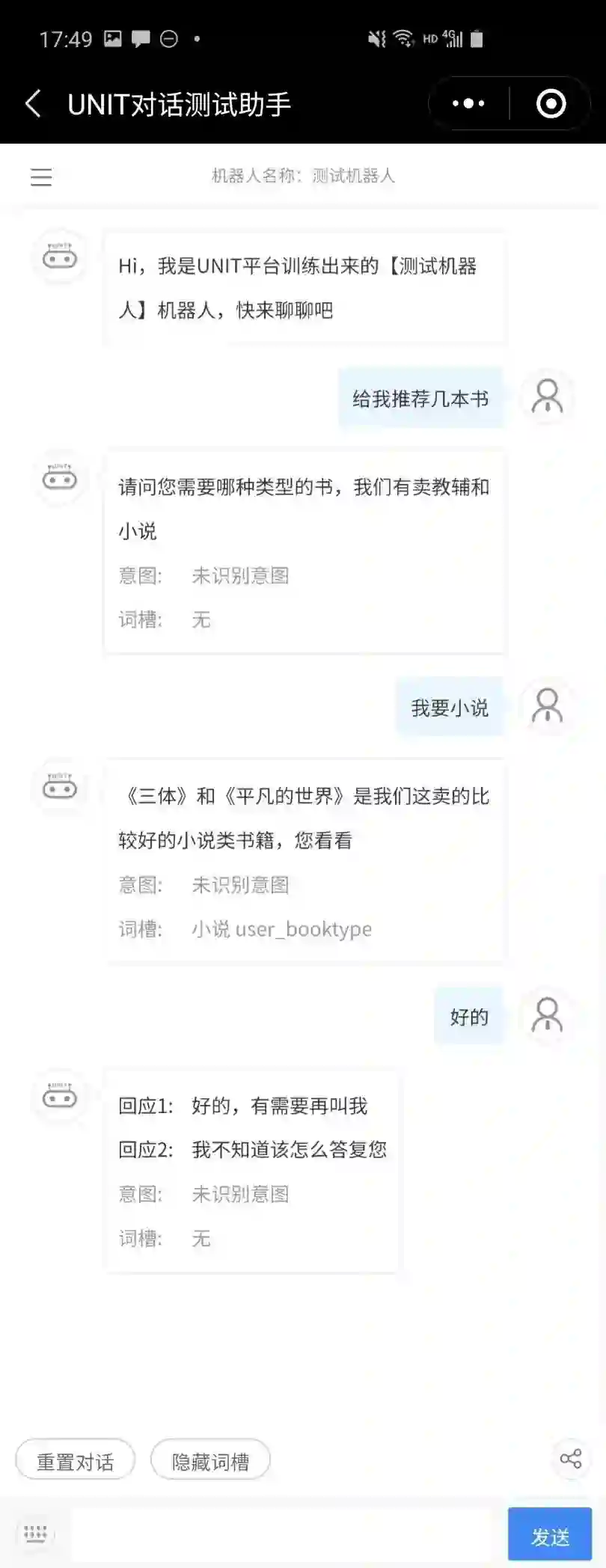
下面是两个失败的案例。左边的例子期望能像最后一个成功案例一样直接进入推荐书节点,但可能是被那个“你好”给干扰了;右边的例子则表面UNIT的slot filling只能识别出词典中已经被定义的词。严格意义上这也不算失败,只是一种策略选择。
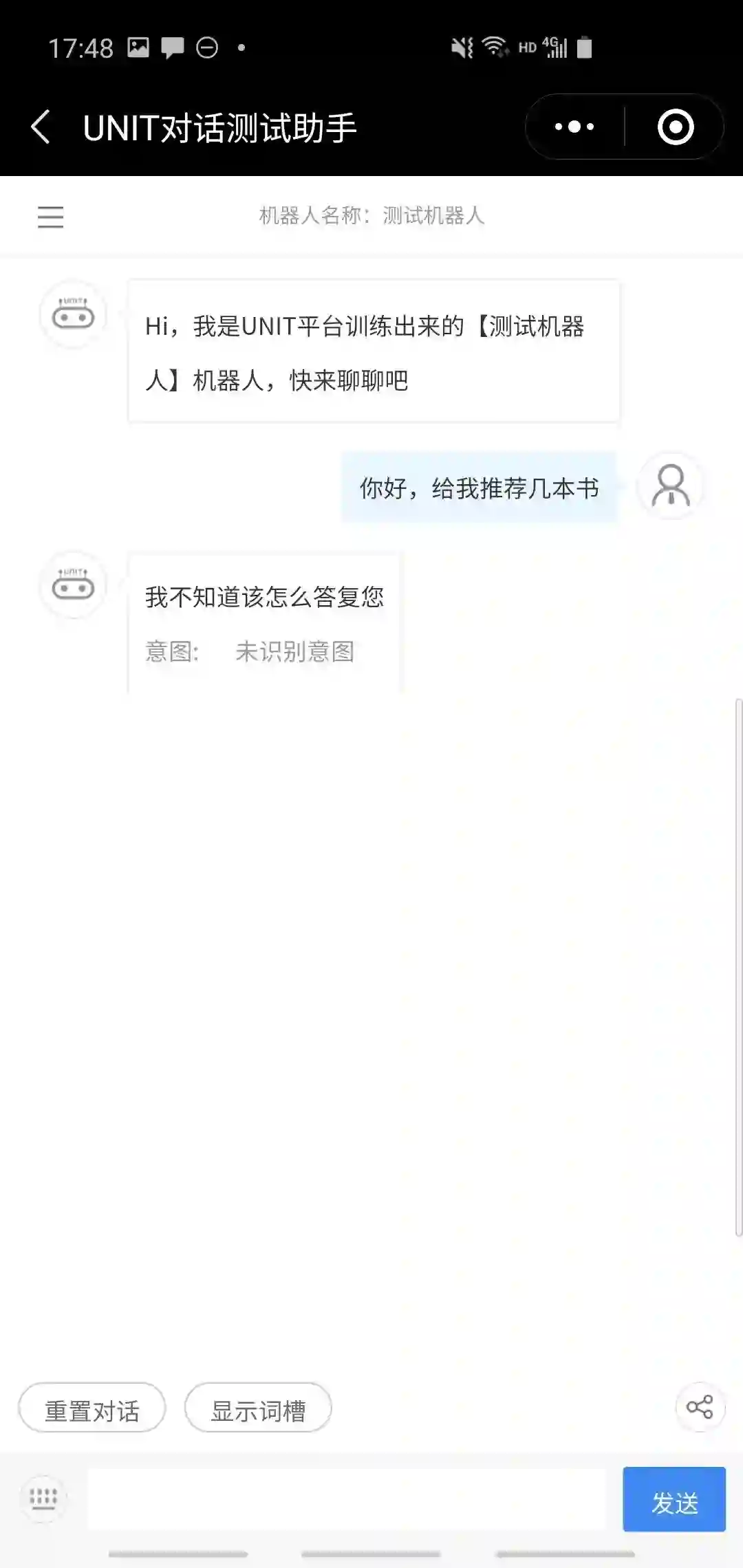
总的来说这个平台目前的完成度是比较高的,比较严重的问题是在定义对话流的时候需要使用者手动输意图名,不过这个问题应该很好修改。
后记
这个体验大概就到这里了,但我们实际上还想更进一步地评测一下这个系统,以及国内其他的平台,做成一个Benchmark。我们在GitHub建了一个项目(https://github.com/thuwyh/dialog-platform-evaluation),后面会把所有的测试数据以及场景定义数据发在上面。但这涉及到大量的数据准备工作,光凭我们的力量会比较吃力,在此真诚邀请有兴趣的朋友们一起加入到这个项目中来。
为了让大家可以快速测试,我们在公众号后台绑定了这个机器人,欢迎大家关注我们后到后台试试。UNIT研发环境每天请求次数有限,大家先测先得。
如果你想自己在UNIT里完善和体验这个机器人,请在后台发送“技能分享码”,便可以在UNIT上用收到的分享码码导入卖书机器人啦。
推荐阅读
【ICML 2020】REALM: Retrieval-Augmented Language Model PreTraining
大幅减少GPU显存占用:可逆残差网络(The Reversible Residual Network)
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




