对话式交互技术原理及流程揭秘

以智能音箱、智能电视为代表的对话式交互,是时下非常火热的、且能够走近我们生活的人工智能子领域。从本篇开始,我们将一起走进对话式交互。
什么是对话式交互呢?我们首先从一个例子开始。贾维斯,电影《钢铁侠》中那位钢铁侠的 AI 管家,他能独立思考、可以实时帮钢铁侠处理各种事情,包括计算海量数据。其中最让观众印象深刻的就是,贾维斯可以随时随地像人一样进行口语交流,来解决钢铁侠的问题。
贾维斯能听、会说,能实时理解主人的对话意图并根据实际场景进行下一步的对话,如果在对话过程中碰到有歧义的情况,他还会追问钢铁侠,让他提供更多的信息来消除歧义。贾维斯的这些能力就是对话式交互要提供的,其中的核心是 VUI (Voice User Interface,语音用户界面)的设计。相对于 GUI(Graphical User Interface,图形用户界面),VUI 解放了人的双手,某些场景下,简单的一句语音命令就能代替 GUI 下鼠标 / 遥控器的多次点击,这带来的不只是方便,还节省了时间。一个好的 VUI 系统,能够让用户尽可能通过最少轮次的对话实现既定意图的执行。贾维斯总能在危机时刻帮到钢铁侠,他是一个具有完美 VUI 的语音助手。
嗯,我们不要入戏过深,贾维斯是一部电影里的虚拟系统。那么,现实生活中,我们能创造出来一个接近贾维斯的对话式交互系统吗?我们该怎么做呢?呃,很遗憾,以当前的科技发展水平,我们还做不到电影里那么智能,更不用说让机器有意识。但人机交互并不是昨天才发明出来的,人类在这个领域已经探索了几十年,我们可以实现钢铁侠与贾维斯的交互方式,并用这种方式来帮我们处理一些数据或控制我们身边的一些硬件设备(比如让语音助手根据天气提供穿衣建议或者控制厨房和卧室的各个家电),这就是我们要聊的对话式交互技术。
对话式交互技术包括了语音识别 / 合成、语义理解和对话管理三个部分。当下的对话式交互产品主要分两类:以微软小冰为代表的开放域(Open Domain)对话系统和以亚马逊 Alex 为代表的任务导向(Task Oriented)对话系统。以现在的技术能力,在开放域聊天中,准确理解用户的话并给出正确答案的难度是很大的,因为面对用户千奇百怪的提问,机器对意图的理解很可能出现错误,知识库也可能涵盖不了那么广。开放域聊天更像是一个信息检索系统,基于已有知识库,为用户的输入匹配到一个答案。这样的对话能力是十分有限的,构造一个完善的知识库更是困难重重。而任务导向的对话系统旨在帮助用户完成特定领域的任务,比如”查询天气“、“订酒店”,这种领域特定的对话系统的最大优势是实现起来相对有效并且易于产品化。本系列的后续文章,我们将深入 Amazon、Google 和 Microsoft 三家任务导向的对话平台。在此之前,我们先一起领略对话式交互技术流程的各个环节。
回顾一下钢铁侠和贾维斯的交互过程,我们以钢铁侠询问贾维斯当前装备的损伤状况为例,他们的对话可以概括如下:钢铁侠向贾维斯询问,贾维斯接收到钢铁侠的话并理解他的意图,然后去查询相关数据,最后把数据展示在屏幕上或读出相关数据给钢铁侠听。这个交互的过程可以总结成下面这张图:
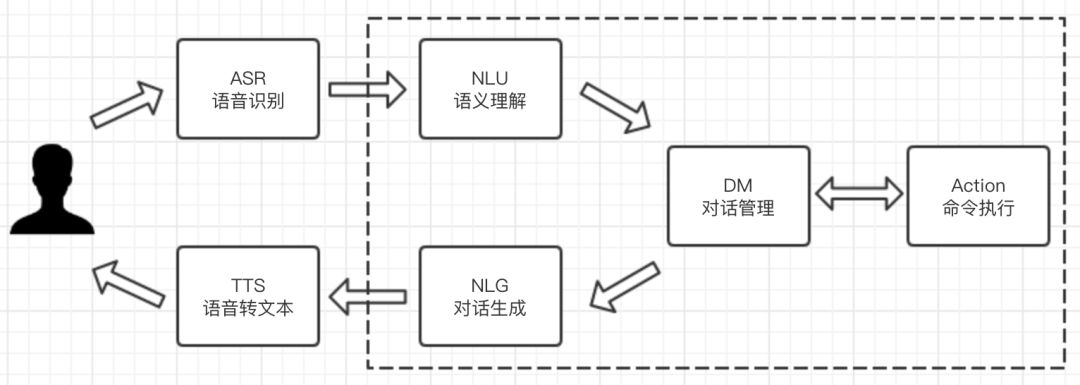
钢铁侠向贾维斯询问:钢铁侠的语音流发送给贾维斯。
贾维斯接收到钢铁侠的话:贾维斯将语音识别为对应的文字,并将口语化的文本归一、纠错,并书面化。
理解他的意图:贾维斯进行语义理解,并进入对话管理。这里省去了多轮对话的示意,当意图相关信息不明确时,贾维斯会发起确认对话,钢铁侠也可以根据贾维斯的反馈,继续问其他相关内容,这些都是语义理解和对话管理服务的范畴。
然后去查询相关数据:在对话式交互服务中,这个流程的提供者我们称其为内容服务。
最后把数据展示在屏幕上:对话结束,产生执行动作。
或读出相关数据给钢铁侠听:对话结束,语言生成文本经过语音合成服务,转换为语音流,播报给用户。
我们一般称将这样的对话式交互系统为语音对话系统(Spoken Dialog System)。这里简单描述下各个组件。
ASR(Automatic Speech Recognition)直译为自动语音识别,是一种通过声学模型和语言模型,将人的语音识别为文本的技术。近年来,随着深度学习在语音识别中的广泛使用,识别的准确率大大提高,让这项技术能被广泛地应用于语音输入、语音搜索、实时翻译、智能家居等领域,让人与机器的语音交互变为可能。
语音识别只是知道我们说了什么,但真正要理解我们说的是什么,就需要依靠 NLU 这项技术。NLU(Natural Language Understand)直译为自然语言理解,是 NLP(Natural Language Processing,自然语言处理)的一个子集,专注于“口语表达和对话”方向的自然语言处理。我们首先快速了解一下 NLP,NLP 研究主要用来解决下面这些问题:
分词:中文的书写词语之间不会用空格等符号来分割,分词就是将汉字序列切分成词序列,因为在汉语中,词是承载语义的基本单元。比如从北京飞上海这句话的分词为:从 北京 飞 上海。
词性标注:词性用来描述一个词在上下文中的作用,如名词、动词、形容词等,词性标注就是识别这些词的词性,来确定其在上下文中的作用。
命名实体识别:在句子中定位并识别人名、地名、机构名、数字、日期等实体。
文本分类:文本分类就是将一篇文档归入预定义类别中的一个或几个,比如将某一类邮件归类为垃圾邮件,区分不同新闻的类型等。
情感分析:情感分析是找出说话者或文本作者对某个话题的两极性观点(积极或消极)、情绪(高兴、悲伤、喜欢、厌恶等)。
自然语言理解通过使用上述技术,完成指代消解、否定判断、语句泛化、口语归一化、ASR 纠错等工作,识别人机对话中的领域和意图,获得对话任务的语义信息。我们可以通过下面几个例子感受一下:
第 45 任美国总统是谁?
他是哪里出生的?他 = 唐纳德·特朗普
感觉怎么样?
不太好 不要紧 没问题 有问题 没有问题 没没没 没事
我要看温情的电影 来个柔情的片子 我想看看暖心的影片
语义表示有多种形式,本系列使用的是最常见也是目前为止最成功的"框架语义(Frame Semantics)",即采用领域(Domain)、意图(Intent)和词槽(Slot)来表示语义结果。
领域(Domain):领域是指同一类型的数据或资源,以及围绕这些数据或资源提供的服务。比如“天气”、“音乐”、“酒店”等。
意图(Intent):意图是指对于领域数据的操作,一般以动宾短语来命名,比如音乐领域有“查询歌曲”、“播放音乐”、“暂停音乐”等意图。
词槽(Slot):词槽用来存放领域的属性,比如音乐领域有“歌曲名”、“歌手”等词槽。
举个例子,从“北京明天天气怎么样”这句话中,NLU 可以得到以下语义结果:
领域(Domain):天气
意图(Intent):查询天气
词槽(Slot):
城市(city) = 北京
时间(date) = 明天
DM(Dialog Management)直译为对话管理,是对话式交互系统的核心,负责控制整个对话过程。主要包括对话上下文(Dialog Context)、对话状态跟踪(Dialog State Tracking)和对话策略(Dialog Policy)几部分。
对话上下文:记录对话的领域、意图和词槽数据,每个领域可能包含多个意图的数据, 一般以队列的形式存储。
对话状态跟踪:每轮对话开始后,会结合本轮对话提供的语义信息和上下文数据,确定当前对话状态,同时会补全或替换词槽。
对话策略:根据对话状态和具体任务决定要执行什么动作,比如进一步询问用户以获得更多的信息、调用内容服务等。
同样以天气场景的对话举例说明:
Q:明天天气怎么样?(intent=query_weather,date= 明天,city=null )
A:您要查询哪个城市的天气?(action= 询问查询哪个城市)
Q:北京的 (intent=query_weather,date= 明天,city= 北京)
A:北京明天晴(action= 调用天气服务)
Q:那杭州呢?(intent=query_weather,date= 明天,city= 杭州)
A:杭州明天小雨(action= 调用天气服务)
Q:后天天气(intent=query_weather,date= 后天,city= 杭州)
A:杭州后天小雪(action= 调用天气服务)
假设我们要查询天气信息。查询天气这个意图需要两个必选词槽,城市和日期。也就是说,只有当这两个词槽都有数据时才能查询天气服务,得到天气数据。从上面对话场景中可以看到,对话管理模块会维护多轮对话上下文数据(包含意图和词槽等),跟踪对话状态,填补或替换词槽数据,并决定如何与用户交互或执行什么样的动作。比如缺少必选词槽时,对话系统会追问用户,以补全词槽。
NLG(Natural Language Generation)直译为自然语言生成,即对话生成的技术。对于任务导向的对话来说,NLG 基本以模板形式来实现。模板中的回复信息可由词槽或通过内容服务得到的数据来替换。对话生成的原则是符合自然语言交互的习惯,易于用户理解,最快完成对话。此外,NLG 还可以用于引导用户的交流习惯,比如 NLG 的内容为"已经为你开启导航",可以引导用户在希望导航时,说"开启导航"。
TTS(Text To Speech)是指语音合成技术。对话系统的输出是文本形式的 NLG 或者指令,当对话返回的内容是 NLG 时,通过 TTS 技术能将这些文本转换成流畅的语音,播放给用户。TTS 技术提供语速、音调、音量、音频码率上的控制,打破 GUI 中传统的文字式人机交互方式,让人机沟通更自然。
讲完了对话式交互的流程和关键技术,接下来来我们再深入思考下对话式交互的产品化。
GUI(Graphical User Interface),即图形用户界面,是我们最熟悉的人机交互方式。我们每天面对的 PC 和手机,无论是使用鼠标点击还是手指操作触摸屏,我们早已习惯了这种无声的图形界面交流方式。随着 AI 技术的发展,对话式交互逐渐走近我们的生活,我们和机器之间的交互从 GUI 迈向了 VUI(Voice User Interface),即语音用户界面。VUI 是语音应用 / 设备的入口,当你说"Hey Google"的时候,Google Home 的音箱就会被唤醒,进而与你交流。语音成为了 VUI 世界的连接者,就像 GUI 时代的鼠标和手指。
相比 GUI 需要用户动手触发某个动作后结果只能以视觉形式展现给用户,VUI 有自己独特的优点,它可以解放用户的双手和双眼,无需手持或者紧盯着设备,用说话这种更自然的方式去触发动作,而返回结果则以语音方式播放给用户听。这在一些像驾驶、做饭、跑步等无法动手操作的场景下特别有用。设计良好的 VUI,会以最少的交互完成用户的意图,能极大地提升用户体验。比如,通过学习用户习惯从而为用户提供"条件反射式"的服务、更口语化的交流、引导用户收敛话题,通过询问纠正异常情况(当用户不按套路出牌时)等。
在 GUI 中,用户的行为流程是预先设计好的,比如在某个界面能触发什么动作都是固定的,或者有个一级一级的引导关系,用户只能按照设定好的流程去做。而在 VUI 中,用户的行为则是无法预测的,不同用户在不同的场景下的行为可能完全不一样,而且语音交互需要用户高度集中注意力去听系统说了什么。在一些场景下反而会带来不便,比如在电视上想看一个节目列表,用图形界面展示的方式会更直观一点,用户可以慢慢看,但用语音播报的话,数据量大的时候,用户很可能听了后面的忘记前面的,效果反而不如 GUI 好。所以设计 VUI 时千万不要让用户有认知负荷,不要挑战人类短暂的记忆力。
声音是自然的交互方式,但却不能完全取代 GUI,它们是一个互补协作的关系。所以在设计语音交互界面时,可以把 VUI 和 GUI 结合起来,以实现多模态的智能交互。通过上面的描述,我们对 VUI 有了大致的了解,趁热打铁,我们来设计一个对话式交互产品。一起体会下对话平台要注意哪些问题。
设计一个好的对话式交互产品首先要突破 GUI 的设计思维。我们设计一个对话任务的目标是最快速地解决用户的问题。对话式交互产品重点是交互,因此一定要结合场景来设计,要把自己代入对话场景中,想象如果自己使用这个语音界面,会在什么情况下使用、以怎样的方式跟它对话、希望它怎么回复我们。下面我总结出了一些设计步骤和原则,可以作为参考:
1. 选择正确的用户场景,提供优质对话体验
不要尝试直接把现有的手机或桌面应用的交互方式转变成语音交互,这样可能会让语音交互变得更加复杂。我们应该结合用户使用语音交互时的状态,比如在户外不方便看网页或屏幕,或者双手被占用无法操作别的东西。
这里有以下几点建议来帮忙选择适合转换成语音交互的场景:
需要用户输入的特别熟悉的信息,比如个人信息、位置、时间等。
能快速提供有用信息的场景,用户说几句话就能节省很多操作,比如订餐、叫车。
天生适合语音交互的场景,比如做饭时听菜谱、开车时做笔记。
2. 创建符合当前场景的对话风格和形象
开始设计语音交互之前,先考虑你希望它听起来怎么样,能带给人怎样的感受。比如要设计个趣味游戏,你可能想要一种搞笑风格;而设计个新闻阅读器,就需要严肃认真的语气,给人靠谱的感觉。
3. 编写对话
选好场景、确定形象后,你可能想要马上投入开发,但是一定要拒绝冲动。相反,我们要用纸和笔先构思一下对话。写下用户可能参与的独立或多轮对话,下面是一些对话类型和可能需要考虑的问题:
完成对话任务最简单的方式,不要太复杂。
完成对话任务的其他方式,这可能是多样化的,因为有的用户一次只说一部分信息,这就需要多次交互才能完成任务,而有的用户则一次把所有信息说完。
需要修正的对话场景,比如系统不支持,或不理解用户的意图。
用户中途结束对话,或完成对话任务后,怎么确认结束对话场景。
问候语,以及怎么引出对话场景。
语音交互部分搞定后,需要考虑怎么在设备屏幕上展示对话内容。比如对话通过语音方式说出了一部分内容,而还有一些数据需要展示在屏幕上。
4. 进行测试
测试没有想象中的麻烦,你需要做的就是找一些开发团队之外的人,在没有提示的情况下,让他们用平时正常说话的方式使用你的产品,从各个角度测试对话。多试几次可能就会发现哪些对话任务完成有困难,或者交互给人的感受怎么样。
设计对话的目标是满足用户的意图,而不仅仅是完成一个功能。
给语音交互界面赋予一个拟人化的形象,不要让用户觉得太生硬,是在跟机器对话。
保持简洁,节省用户的时间,提供有效的信息。
信任用户,用户知道怎么讲话,所以不要试图教用户怎么说,我们只需要提供最自然的方式,推进对话进展就可以。
可以增加个性化能力,使用户听起来感到愉悦,但不要分散用户注意力。
使新用户感兴趣,也要吸引专家用户,设计要面向海量用户,而不是只满足低端需求。
轮流说话,当轮到用户说话时,不要贸然打断。如果是问用户问题,那就不要在他们回答问题的时候又突然插入其他指令。
不要猜测用户的意图,给用户展现事实,让他们自己决定。
结合上下文语境,追踪对话的来龙去脉,保证准确理解用户的话。
综上,我们对对话式交互有了比较全面的认识,本系列接下来的三篇文章将以本篇讲述的对话式交互知识为背景,深度讲述亚马逊、谷歌和微软的语音交互平台,和大家一起分享如何在这三大平台上,实现我们自己的对话式交互技能。这里对技能的定义是特定领域的对话能力,包括语义理解、对话逻辑控制和相关的内容服务。
https://developer.amazon.com/designing-for-voice/
https://developer.amazon.com/alexa-skills-kit/vui
https://developers.google.com/actions/design/principles
https://design.google/library/conversation-design-speaking-same-language/
https://yq.aliyun.com/articles/8301
我们来自阿里巴巴智能语音交互团队,隶属于阿里巴巴机器智能技术部门。我们的主攻方向是对话式交互技术,对外输出 Spoken Language System 产品 (http://nls.console.aliyun.com )。我们是上汽集团智联网汽车、上海地铁语音购票、海尔人工智能电视等产品,语音交互能力背后的男人。
本文选自极客时间《智能语音对话技术揭秘》免费专题第一篇,完整专题请点击「阅读原文」查看。


如果你希望看到更多类似优质报道,记得点个赞再走!
┏(^0^)┛明天见!


