一文详解启发式对话中的知识管理 | 公开课笔记

来源 | AI科技大本营在线公开课
分享嘉宾 | 葛付江(思必驰 NLP 部门负责人)
整理 | Jane
【导读】自然语言对话系统正在覆盖越来越多的生活和服务场景,同时,自然语言对话的理解能力和对精细知识的对话召回率在技术上仍有很大挑战。
启发式对话通过建立知识点之间的话题关联,使对话系统能够主动发现相关知识,充分发挥知识的协同作用,引导对话过程,把知识在合适的时间主动送达用户。知识不只是以知识图谱或问答库等形式被动被搜索,启发式对话中的知识结合了先验经验和用户对话习惯,从而拥有知识角色,让对话理解和对话流程更加自然,也更有用户价值。
在本期公开课课程中,AI 科技大本营邀请到了思必驰 NLP 部门负责人葛付江针对“启发式对话中的知识管理”做系统的讲解和梳理。
以下内容为大本营公开课整理。
今天给大家分享一下,关于启发式对话中的知识管理系统,分享的内容包括以下五个方面:

▌对话系统的架构
首先是对话系统的架构,我们来看一下对话系统流程。

在一般的对话系统应用场景,比如在智能音箱、智能电视,包括现在车载的设备等,当用户说了一个问句,智能客服自动的问答和对话,这样的系统的基本流程是它接收到用户的一个问句或者用户说的一句话,然后系统里做一些处理,给用户一个答复。
我们今天说的对话系统和传统的问答系统有一个重要的区别,对话系统它是维护上下文的,在做一个对话的时候是有上下文场景,在这个上下文的过程中需要控制一些对话的状态,来完整地理解用户的意图。
例如,用户问一句明天会下雨吗?系统会做一些预处理,即一些自然语言处理上的特征处理,比如分词、词性标注、命名实体识别这样的模块,在这里可以识别到一些实体,比如里边的时间是明天,关于天气现象是下雨,这是命名实体可以做到的。
经过特征的预处理以及命名实体的识别,然后进入正式的对于这句话的理解。首先是对于用户的每一个问句需要做一个领域的判断,一般做这个领域判断是因为在对话系统里会支持各种场景,首先把用户的这句话限定在一个固定的场景下,然后才能做相应的后续处理。
领域的判断一般情况下有各种方式,不管是写模板,还是一些分类的算法,比如这句话我们送到一个分类器里,它可能能判断出它是一个天气领域相关的。在这里边,通过 Slot Filling,它就可以得到天气领域的一个意图,这个意图领域是天气领域,有它的地点和时间。当然这句话没有提到地点,因为一般这样的系统会通过传感器或者是定位的信息,或者是 IP,或者各种设备相关的场景的信息获取到他一个默认的地点或者默认的城市,根据这些信息,然后我们得到一个结构化的意图。
这个结构化的意图,然后送给一个对话管理或者对话状态追踪的模块,这个对话状态的管理去做一个判断,说以当前这个领域,比如天气这个领域它的 Slot 是否是满足的。对于天气这个领域比较简单,发现这句话实际上它的领域意图、时间、地点都已经满足了,然后把这些槽位都补充上。
根据这些补充好的信息,实际上它就是一个结构化的信息,根据它的时间、地点、天气现象,然后去后台的数据服务里做一个查找,把真正的天气,比如明天需要下雨或者是晴天这样一个信息取出来,然后经过一个答案生成,Response Generation 这样一个模块,然后生成一句比较自然的话,比如说明天可能是一个晴天,然后就说明天是一个晴天,如果再说得更自然一点,可能说是一个出游的好时间,类似这样的,整个流程大概是这样,实际上是一个比较简单的过程。
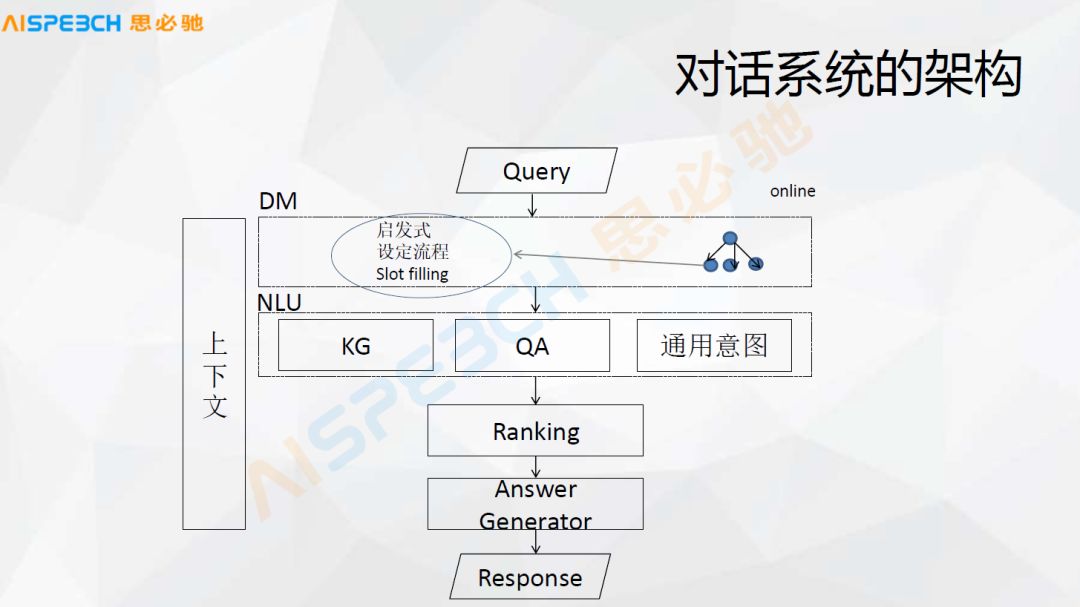
通过这个流程我想跟大家分享一下对话系统的基本架构,首先它要处理一个用户的 Query,然后它要经过一个对话管理的模块,这个对话管理实际上就是维护上下文的信息。再下面是一个意图的理解,这个意图的理解可能有各种方式,包括知识库或者叫知识图谱,包括问答的形式,这种问句相似度匹配,还有一些通用的各种其他的意图的理解,包括意图分类的这些东西。
在这个里边,对话管理在这个里边,一般情况下对话管理实际上是一个类似于流程图的东西,比如以刚才天气的里边,它实际上是一种叫 Slot Filling,有几个信息填满之后就可以了。然后在一些其他的对话过程中,比如说典型的客服,实际上一般在客服的具体场景下,比如金融领域的某一种金融业务或者是用户查询一种金融产品,比如保险这种产品,某一种保险产品,它有一些信息,它实际上是一个流程图的形式。
还有一种是我们后面会提到的启发式的对话,这几种形式的结合,其实是一个对话的管理。现在一般的系统可能都是处理某一种对话,要么就是 Slot Filling,要么就是一个设定好的流程,要么是一种启发式,能把它做到融合的可能还不是特别多。
继续在这个图里边,刚才提到对话管理就是 DM,对话的理解就是知识库,问答对,还有一些通用的,比如说抱怨,一种通用的状态,一般情况下可能是一种分类的方式来做的这种 NLU 的理解之后,各个模块做到这个 NLU 之后,它需要去做一个抉择,因为在各种系统里边,用户的一句话可能都会找到一个答案,我们到底选哪一个答案,所以就做一个排序,排序完之后经过一个答案的生成,最后给用户一个答复。
当然这里边,边上还有一个模块就是上下文的管理,它在对话管理、NLU 以及排序和答案生成这些模块里都会用多,它会维护一些上下文的信息。当然这张图结构是比较简单的,但是每一个里边实际上有挺多东西,我们后面看具体的内容,最后我们回过头再来看这张图,可能就会有一些不一样的东西。
看之前我们先总结一下现在一些对话机器人的现状,一般对话机器人怎么来评价或者它现在的状态,一般评价的标准,我们对机器人的评价是不太好评价的,我们做一个系统或者做一个学术的研究,一般情况下它怎么来衡量这个机器人的效果,实际上是一个很重要的事,我们要做这个事前需要先定一个标准。

一般的像对话系统主要的几种评价的东西,一个是准确率,准确率可能就是基于一些问答对还是不对,或者对话答的对还是不对,比如这个对话进行了十轮,这十轮里有几次对的,几次错的,直接给一个零一的判断,然后算出准确率。
另外一个,人工打分,因为这个对话过程中它可能并不是一个绝对的零一的判断,有的时候它给的答案可能不那么合理,但是一定程度上能够接受,所以人一般可以给它打一个分数,比如说 1 到 10 分或者 1 到 5 分,给一个分数,最后给这个机器人一个综合的打分。
学术上可能借鉴一些其他系统的标准,比如说困惑度或者 BLEU 值这样的方式来给一些打分,一般这种标准更多是在一个限定的数据集里去衡量这句话,生成的这句答复它的语言流畅程度,可能更多的是从语言流畅程度的角度来衡量,当然这些困惑度或者BLEU值,它的好处是能自动地来判断,但是坏处是它其实很难严格地从语意上来判断这个系统好或坏。
在一些极窄的领域里,比如说订餐,甚至更窄一点,比如订一个披萨或者订咖啡,或者拨打电话,这种很窄的领域,实际上现在机器学习的方法和模板的方法都能够做到一个比较好的精度。
机器学习或者深度学习,但是深度学习在这种场景下它也依赖于一个比较大的数据量,相对于这个场景来说,因为一般在这种实验上,它的场景还是比较小的。如果场景比较多的话,现在在一个比较复杂的场景里,可能现在深度学习的效果还不是很好,就是在多轮对话的场景下,并且有多个场景混合的话。
另外在一些较大的领域,比如客服,客服这个场景,它一般情况下对于一个企业的客服,一个企业的客服可能会涉及到几种产品,既使是一类产品也会涉及到这一类产品不同的产品线以及它各种型号这些东西,客服它相对来说是一个比较宽的领域。
现在不管是深度学习,还是其他传统的机器学习,如果在整体都用深度学习的方式,它的准确率是比较低的,很少能做到 50% 以上的,就是在一个比较大的领域里。所以现在在客服领域里,很多系统是基于检索式或者是基于模板的,检索式就是它准备好了一些标准的问答对,因为企业做自己的客服的时候,一般情况下积累了一些它自己对自己产品的标准问题和答案的,用户的一个问题就到这里找一个最相似的问题,然后给它一个答案。这种方式目前是用得比较多的。
另外一种就是模板,人工去写一些规则的模板或者叫语义的模板,然后去解释用户的这个问句包含哪些主要的信息,然后把它对到一个意图上给一个答案,在这些领域里边,较大的领域实际上机器学习的算法还是有一些挑战的,即使用模板它也有很多的挑战,因为模板多了之后它就会有冲突以及不好维护的问题。
▌启发式对话系统
启发式对话系统,是我们正在做的一个启发式对话系统,启发式对话系统现在有一些相似的概念,比如说主动式对话,思必驰提出来这个启发式对话可能主要是在这样,在一些企业的场景下很多时候用户实际上是面对一个对话机器人,他不太清楚能问什么样的问题,以及这个机器人的能力是什么样,它能回答什么样的问题,或者用户大概知道他要什么东西,但是他对于问问题这个事,让他去问很多问题还是要费一点脑筋的。
启发式对话大概就是这么一个流程。它实际上通过这些问题背后的一些联系,能让这个对话一直持续下去。当然你说你不想了解然后它就结束了。这是一个基本的概念。
我们来看一下启发式对话有哪些基本的特点,首先根据用户的问题主动引导对话交互,用户问了一个问题,系统会根据这个问题把一些相关的问题列出来或者问用户他想不想了解。用户的问题是以多种形式连接到知识点,当然这个对话后面,我们叫知识点,以一个知识点的方式,连接一个知识点可能就是对于一个具体的问题,这个问题可能有各种不同的问法,我们都认为它是一个知识点。
以多种形式指的是现在常见的形式,它可能是一个问答对的形式,在这个对话系统后面可能是一个问答对的形式,也可能是一个知识图谱的形式来存在的,但是它们的连接是统一的,都是以一种知识点来管理它们。

知识点如果直观地理解,我们可以认为它就是问答对或者知识图谱里面的一个实体相关的属性这样的东西,这些知识点之间或者问题之间,它通过话题来融合,话题实际上对用户是一个不可见的概念,它是为了去做推荐,因为我们把问题通过话题做一个连接之后,后面这个启发式对话实际上是根据话题来做一些选择,用户问了一个问题,我们把这个问题所在的知识点,这个知识点它所在的话题,根据这个话题去找到一些相关的话题,然后在那些话题下面找到一些对应的问题,然后推荐给用户。
话题之间有一些语义或者逻辑关系的,后面会具体讲这些话题之间是怎么组织的。整个对话过程可能就是根据话题来做整体的规划以及跳转的。这是现在整个启发式对话它的一些特点。
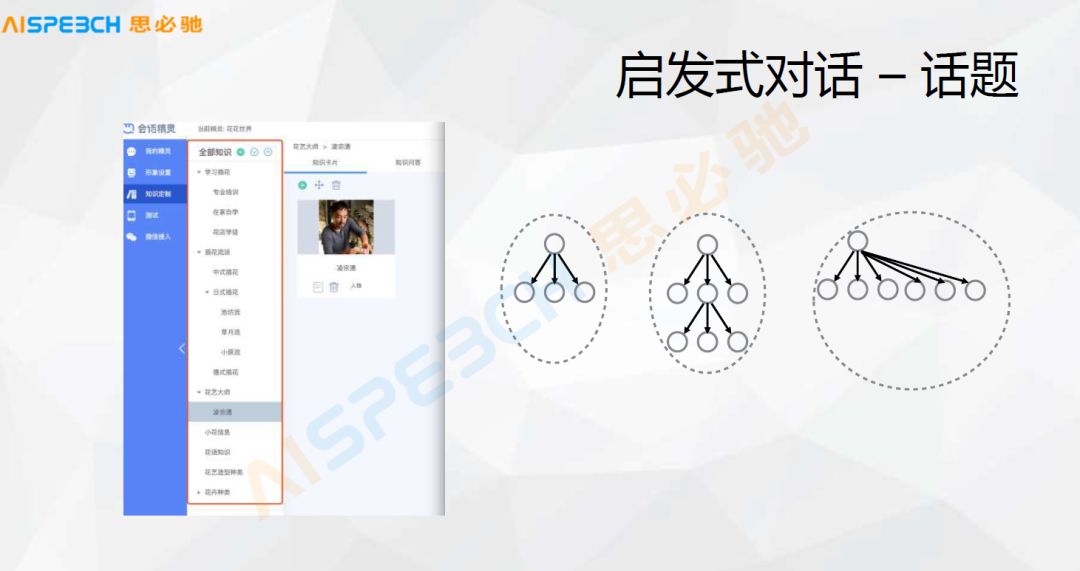
这是一个具体的例子,这是一个产品的形态,就是说这个话题的组织。对于一个企业的客户,它如果想做一个它的对话系统,它可以人为地去设定一些话题,这个话题是以树型的组织,比如在这个里边就是一个关于花相关的话题,比如怎么学习花艺,各种花艺相关的信息,每一个话题,橙色的这部分是这个话题的组织,话题树,用户可以设定这样一个话题的组织。在这个话题下面,每一个话题下面用户都可以去定一些,比如花艺大师,花艺大师下面用户可以定义它在这下面一些人相关的信息,然后具体把这些人相关的信息列出来。
一个终端的用户就可以去问这些关于人的信息,所以话题大概有这么几种形式,首先以右边这个图的形式,某一个话题下面可能有两三个这样的话题,当然这个话题还可以有层次,它可以有子话题、孙子话题,这个层次结构可以来组织扩展,当然一个话题下面可以有很多话题,这个话题的一个组织形式,这些基本的概念。
▌对话系统中的知识管理
再我们来看一下,在对话系统里边这些知识它在对话的理解以及对话管理中是怎么来发生作用的,后面我会结合现有的技术,现有的大家常见的做对话里边的相关技术,然后和启发式对话一起来介绍对话系统中的知识管理。
首先来看几个例子,在机器人理解语言中可能遇到的一些问题,这个给大家一个直观的感觉,可能遇到哪些问题。比如说在理解上,机器人理解语言的过程中,比如说“今天天津适合洗车吗”这样一个输入,如果是语音或者拼音输入都可能会有这样的问题,“今天天津适合洗车吗”可能和“今天天津市河西”,天津市有一个河西区,可能就会理解错,从拼音到文字可能就会出错,实际上这个非常相似的。
这是我们在语言上可能会有一些问题,机器来做这个事的时候,它实际上很难来判断,人是有一些背景的知识和上下文知识的。

我们来看一下,刚才列了那么多问题,一般情况下来做这个对话里边核心的,刚才我们在最开始的架构图里已经看到对话系统里边核心的三大块,一个是自然语言理解,一个是对话意图理解,对话管理和对话答案的生成三个部分。
大家比较关注的是前两个方面,对话的理解和管理,理解这部分可能最常见的是基于规则的系统,比如我们就写一个 pattern,科研人员、时间、发表过的文章,类似这样的,这个规则系统里有一些词典和规则的组织,当然这有一系列规则组织的问题,实际上它也是一个比较浩大的工程,但是我们从算法或者是我们理解的角度,可能觉得它还是一个比较简单的方式,当然规则多了之后是挺难维护的。

另外一种可能就是通过意图的分类的方式,比如通过一些机器学习的方式给它做一个分类。比如我们做一点简单的,比如天气,对话系统只要理解出来它是天气,然后我们就给它播一个天气预报,很多场景下用户也可以接受,系统不理解它里边具体的东西,只理解是某一种意图,然后就给它做一个播报。这里面常见的这种分类的算法都可以用得到。

另外一种是问句检索的方式,比如在闲聊或者客服中实际上都大量地用到。我们说闲聊,实际上从学术上来说可能很多研究是在做深度学习的闲聊,但实际场景的闲聊里边,有很多也是通过问答检索的方式检索出来的,当然它需要有大量的问答对,这些问答对都是人手工事先整理出来的,这是一个比较耗费人力的东西,并且它覆盖的范围有限。
一般做这个事的方式是说先通过一个倒排索引,这个用户问题来了之后检索出一组问题,然后对它进行一个侯选,然后再做一些排序,这个排序的算法可能有各种加权,有传统的 learning to rank,还有深度学习下来这种深度的语意匹配的算法,这些算法我们后面可以具体地看几个例子。

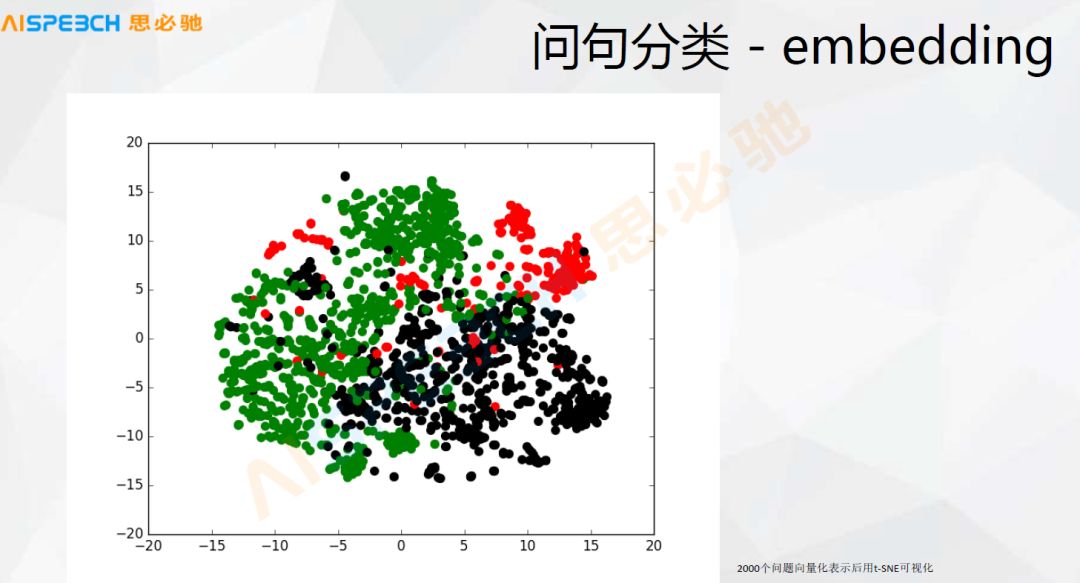
问句分类也有一些直接拿现在深度学习的,比如embedding,实际现在深度学习,比如前面提到的 Sequence to sequence 模型可以直接把用户的问题 embedding 成一个向量,我们直接拿这个向量实际上就可以做一些问句的分类或者相似度计算,这张图是大概 2000 多个用户的问题,然后做了一个 embedding,就是用 Sequence to sequence 做了一个 embedding。
这个时候拿这种可视化的工具把它可视化出来,我们可以看出来它大概是能分出来的,这是三类问题,实上它确实也就是三类问题,虽然它们之间有一些交叉,现在这种深度学习的方法对于这种东西的建模能力还是挺强的,基本的问题类别还是能区分出来的。
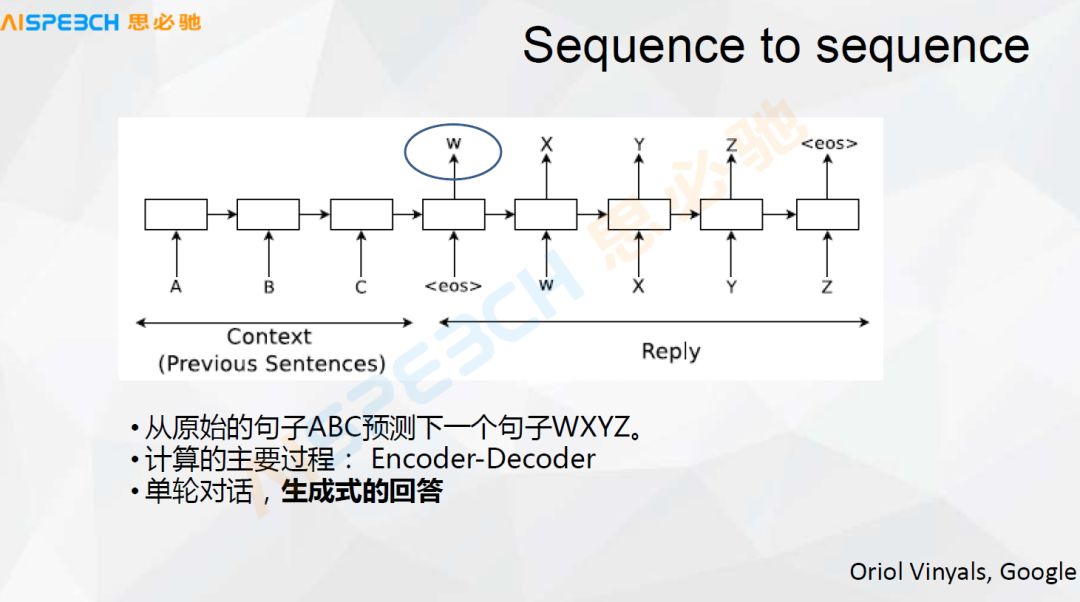
下面这张图,现在这种基本的深度学习里边的这些算法有一个很基础的模型,就是 Sequence to sequence 的模型,它是基于把用户说的里边的每一个词,比如 ABC 是一个输入的词,ABC 是输入的这个问句,A 是一个词,B 是一个词,C 是一个词,然后它的输出有可能就是 XYZ,它把它送到 Sequence to sequence 这个神经网络里边,A 是一个词,进去之后是一个 RN 的模型,它就做这样一个 embedding,实际上到了 ABC,然后 eos,就是这个句子结束了。
结束之后这个神经网络中间层就是一个 W,这个 W 可以表示这个句子的语意的表示,用这个 W 再去解码出来一个答案,经过大量的数据训练实际上就可以生成一个答案,生成式的闲聊可能主要就是这么来做的,这个模型,包括中间的这个表示 W,实际上也可以用来做问句的分类或者问句相似度的计算。
这是一个基本的模型,现在做问句,我们刚才提到现在大量的实际使用中做问句的相似度匹配,可能一种方法就是做句子相似度的计算,这张图是一个做句子相似度计算的基础模型,这里面这些都是现有的方法。
比如说用 LSTM 来对句子做一个编码,这个 LSTM 这个基本的模型和刚才的 Sequence to sequence 的编码阶段类似,用户的一个问题和一个系统中的问题,两个都经过一个 LSTM,这个 X 代表了输入,H 代表的是模型中间的隐藏层,用户的这句话经过 LSTM 把它编码成一个 h3(a) 这么一个状态,还有一个标准问题(被检索的问题),经过一个编码,编码成了 h4(b) 这么一个状态,两个经过一个距离的计算,就可以送到一个分类器里,给它做一个相似或者不相似的判断。
这个方法是把用户转换成一个分类的问题,二分类的问题,这个用户的问题和我们标准库里的问题相似或者不相似,然后做一个判断。这样也可以做这个事,这是一种比较经典的方式,其实它的效果也还挺好,很多场景下都是挺适合的。
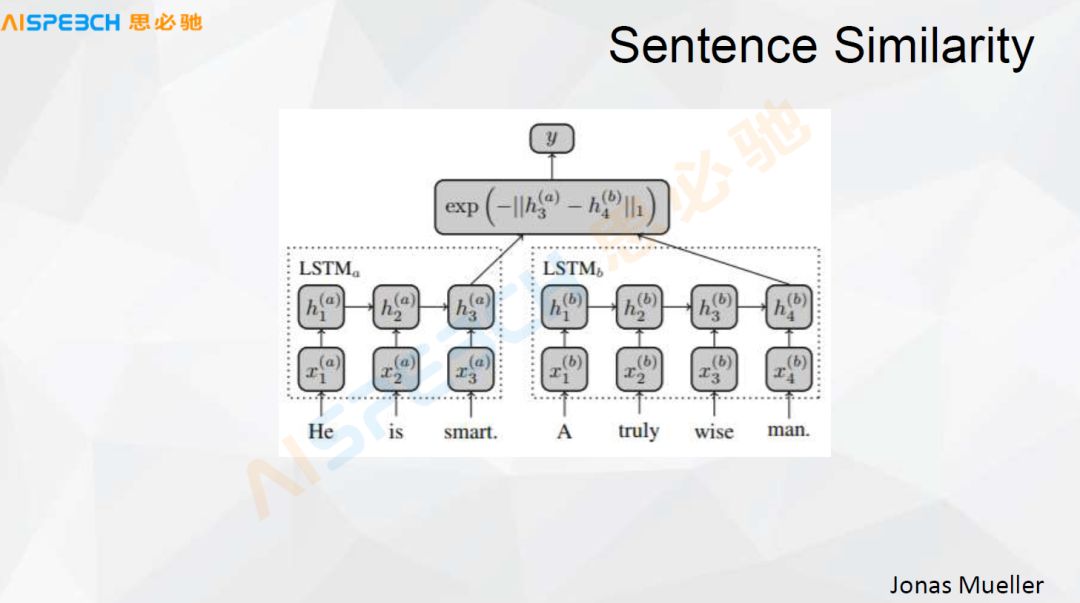
我们看一下下面这篇文章,这篇文章我觉得是在做相似度计算方面比较经典的一篇文章,它还做得比较好。它左边是输入,比如有 u_1、u_n-1、u_n是用户的输入,u_1 到 u_n 是用户输入的整个上下文,他可能说了多句。r是response响应。
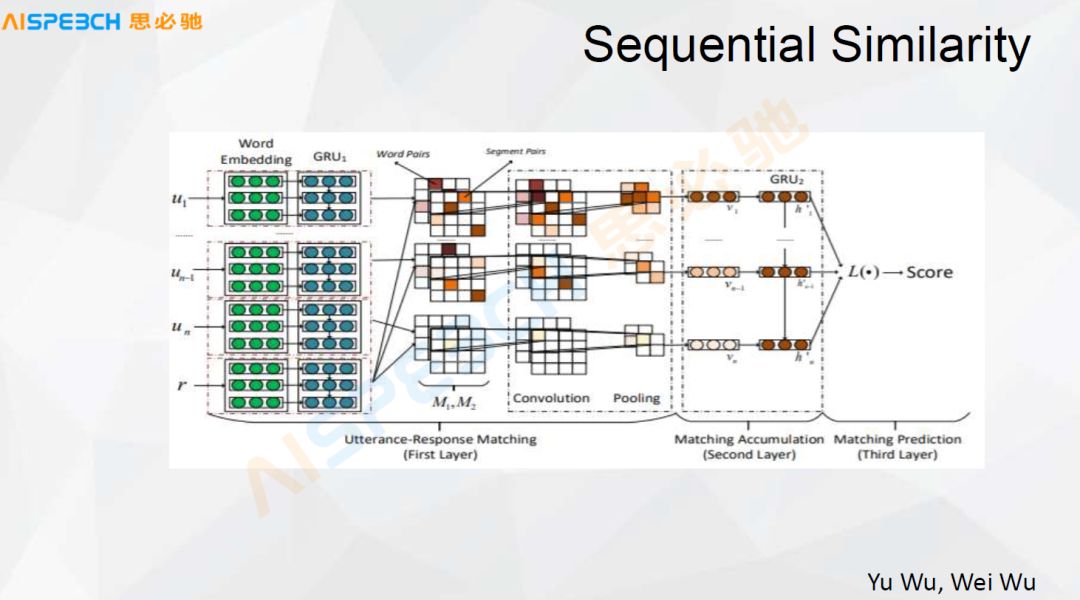
这个上下文经过一个 Word Embedding,每一个都可以 Embedding 成一个词向量的表示,然后经过一个 GRU 或者 LSTM 都可以,然后把它编码成一个向量。这里边做了一个比较复杂的操作,中间这部分,M1M2 这部分,它是把用户的输入和答案分别交叉去做了一个内积的计算,都是向量,实际上表示出来都是矩阵,它们之间做一个内积混合的运算,充分的交叉之后再经过 CNN,CNN 然后经过一个Pooling,Pooling 之后再经过一个类似于这里边又过了一个 GRU,最后输出一个分值。
这个和刚才 LSTM 那个方式最大的区别是,首先它层数增多了,因为它最前面是 GRU,最后边这儿也是一个 GRU,中间多了一个 CNN 的层,这个 CNN 层的作用实际上是把问题和答案的信息充分地混合,去找到它里边匹配的相似或者结合的点,然后来给出一个答复。这个模型在很多场景下的效果是比较好的,我们在一些实验中它的实际确实也是比较好的,但是它的问题是,因为它经过了一个很充分的混合,我们看到它对输入的要求是有一定要求的,这个输入相对比较长一点,它的信息比较充分,这样做是比较好的。但是在有一些对话场景下,当这个对话比较短的时候,它的效果实际上是有限的。这是一种方式。
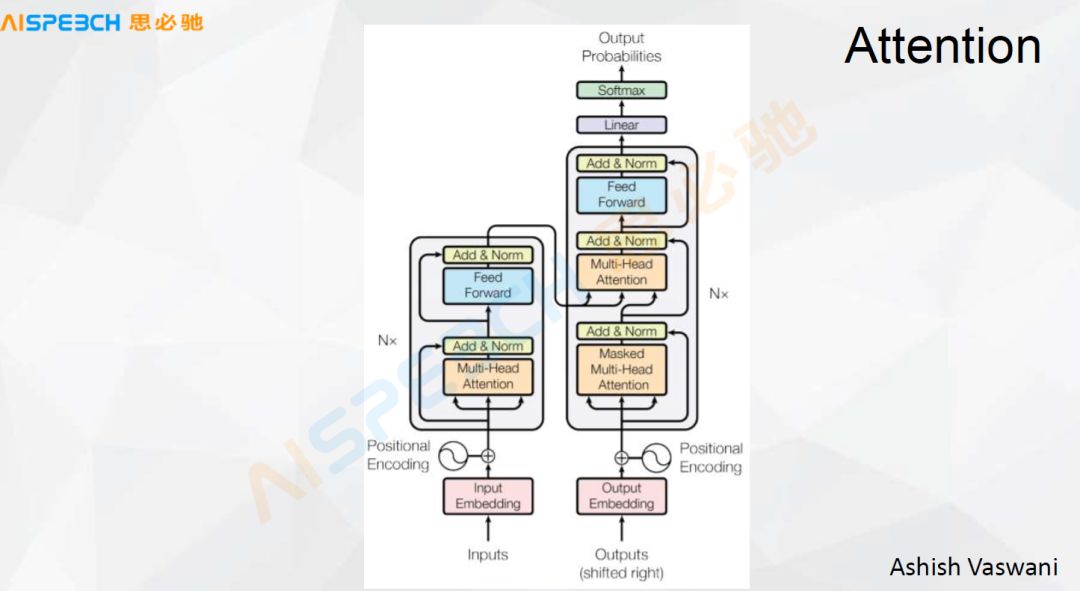
这张图是谷歌的一篇文章里,它只用 Attention来解决,比如 Input 和 Output 这两个地方,经过一系列的 Attention 最后输出出来,我们做一个分类决策。我们借助于 Attention 的这个模型,多层 Attention 的模型去做这个分类任务的时候,这个在一些比较短文本的场景下,问题都比较短的情况下,它的效果实际上是比较好的。实际上这些模型可能都不是万能的,每一种模型都有它适用的场景,根据数据我们才能看到它在哪些场景下更好或者是有它的长处。每一种模型都有它的长处和缺点。
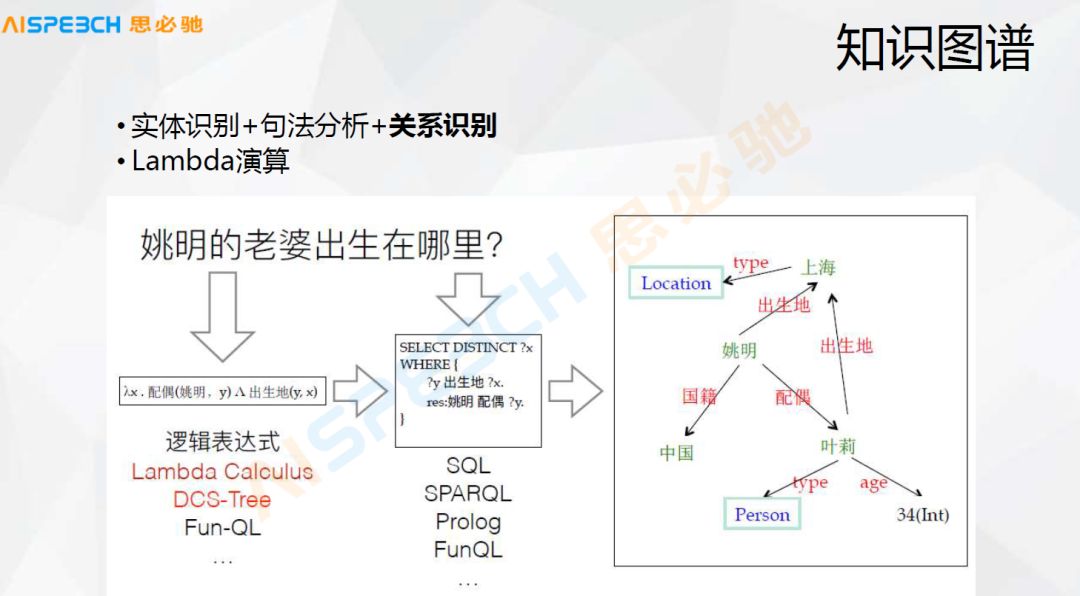
还有一些知识图谱的方式,最直观的可能知识图谱是通过一些逻辑表达式来做的,比如说一个简单的问题,就是姚明的老婆出生在哪里这种,知识图谱里边存储了姚明以及他的配偶叶丽,这个方式我们理解起来也比较简单,就是做了这么一个查找,但是当知识图谱比较大的时候,实际上知识图谱上的问答还是比较难做的。主要是用户的表达很难去和知识图谱里的东西严格地匹配上,一般情况下这种方式,把用户的一个问句严格地解析出来问句里各个实体及其关系,然后把这些转换成一个逻辑表达式,通过这个逻辑表达式到这个知识图谱里去查找。这种方式其实也很常用。
刚才介绍了现在理解方面主要的方法,但是现在也有很多方式是说集成,我集成上面各种方法,然后做一个集成学习,比如问句理解的方法,问答的方式,就是检索、知识图谱、 embedding 的,都可以用来做问答,任务型的问答可能有规则的,也可以做embedding,也可以做分类,复杂问题可能就是客服里边有很多问题其实挺复杂,长度也比较长,可以用这种分类或者检索的,也可以用更严格的语意解析的方式来做。这些不同的方式、算法做一个集成,实际上现在有挺多是这样做的,效果也还是挺好。

就是我们在做一个模型去做选择,上面比如做了三个或者五个模型来去理解,用户来一句话对这几个模型都去理解,理解出来之后然后做一个集成,集成之后再做最后的输出,集成实际上是为了做选择,到底用哪个模型的答案,当然集成方式主要是两种,一种是流水线,这些模型我排成一个顺序,哪个模型解决了我就出了,我就把答案出出来,然后就不再往后走了,另外一个是模型集成,每个模型都走,然后做一个决策判断,选哪个模型的结果。
上面是关于对话中 NLU 的部分,另外一部分是关于对话中的知识管理,或者对话管理里的知识管理,对话管理这部分。
对话管理一般是这样,我们在有上下文的情况下,对话管理就是用户当前我们可能能分析出来一个意图,有的时候甚至当前我们都分析不出来一个意图。比如说用户说了一个上海,我们实际上不知道用户说上海是什么意思,如果前面是在说天气,那上海就是跟天气有关,如果前面在说订票,那上海就是和订票有关。有当前的一个用户的意图,甚至这个都不是一个意图,然后有上文,有一些上文是在哪个领域里边,有用户的信息,这个有时候可能还有一些用户长时间的信息,根据这些信息做出一些行为,到底是要答复,还是拒绝,还是去问用户的补充,用户需要补充一些信息。
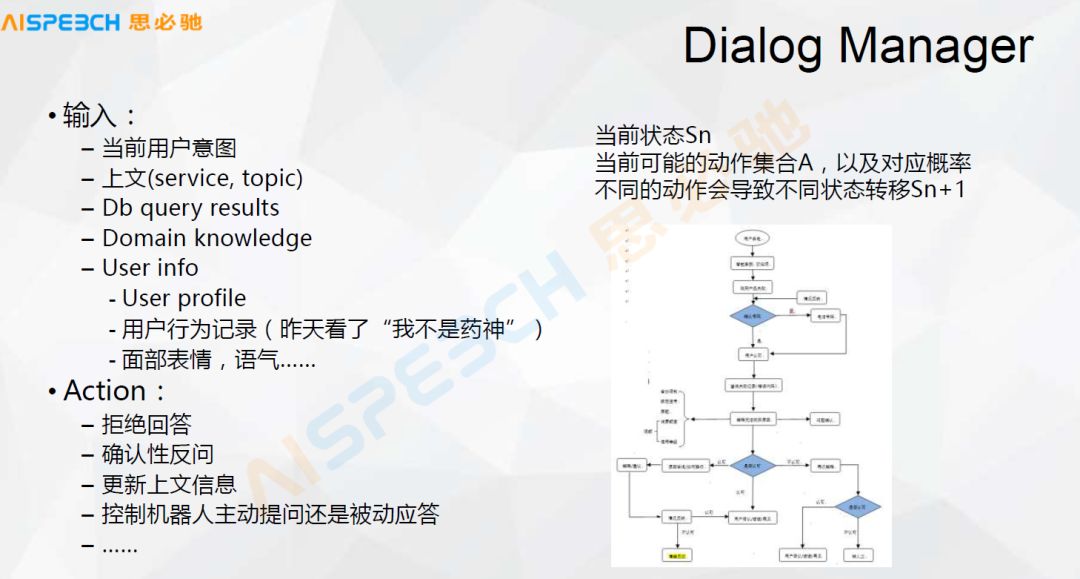
对话管理里面有几种主要的形式,一种是基于 slot 的,slot 可能就是一个填槽,如果有三个槽位,时间、地点、天气现象,我就把它填完就行了,缺哪个我就问用户有哪个。另外一种用 slot 不是特别好解决的就是有些流程很复杂的,特别是在客服,比如这张图里的场景,这是一个客服的场景,它的流程就很复杂,用户到了某一个地方,他需要去判断关于这个地方的信息,然后再做下一步的操作,这是这个对话管理主要的东西。

这张图介绍一下关于最基础的对话管理,比如 SlotFilling,它是在有没有上下文,事先定义好了这张订票的场景,然后它有一些上下文的信息怎么来控制,这个场景是刚才已经提到的,就不详细说了。
在启发式对话里边还有一种基于话题的对话管理,首先话题本身,因为它引入了一个新的概念就是话题,在问用户的问题之外引入了话题,话题可以是人工建的,也可以是系统自动计算出来的,也可以是系统引导用户来创建,这个话题就是我刚才在最开始讲启发式对话的时候,我们看到的,比如说关于花的一些相关话题的组织,也可以通过一些学习的方式去挖掘问题之间有哪些话题,特别在一些企业服务的场景中,因为企业本身有它明确的应用场景,所以它是有一些话题,它本身已经组织好的关于这些话题的组织。

当然话题的组织实际上是有很多问题的,我们比如拿树型来组织这些话题,这个系统的后面怎么来组织这个话题。比如按产品、人物来组织话题,所有的产品是一个话题,所有的人物是一个话题,但是当我真正要去问这个系统的时候,你会发现产品和人物它们之间是有交叉的,因为人物,比如说科技领域的人物和娱乐领域的人物,他们可能就没有什么交叉领域,我们把它放在一个话题下面也不合适。所以说话题的划分实际上是有一定交叉的,当然我们显示出来一般情况下是一种树型的方式来组织,这样对用户也比较容易理解。但是它真正的管理后面实际上有很多的交叉。
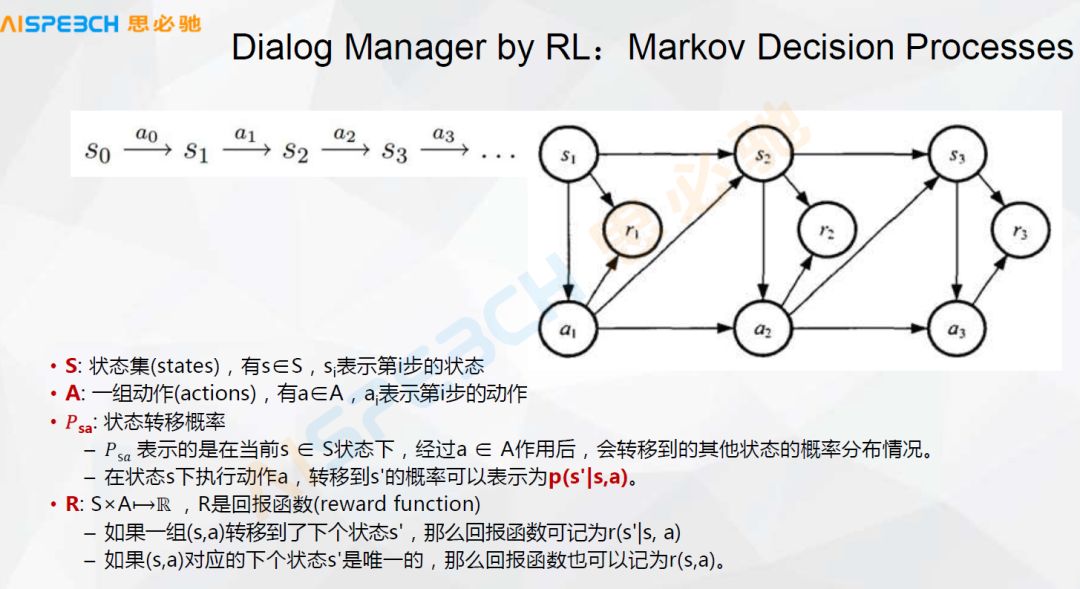
对话的管理,实际上一般情况下我们可以认为它是这种状态,这种状态转换的过程,比较典型的可能就是一个 Markov 决策过程,这里边 S 是一组状态集,A 是一组动作,在某一个状态下它遇到一个什么东西,然后要做一个什么样的响应或者什么样的动作,机器学习的方式可能就需要把这个对话组织成这样一个状态,在这里边一个重要的地方是需要有一些回报的函数。
比如说在强化学习做这种对话的时候,不一定是做对话管理,做对话生成的时候也有这种场景,就是说它去定义一个在对话里边,它模拟多轮,根据一个定好的回报函数,然后来做一个判断,这是对话管理,对话管理用强化学习可以来做。实际上强化学习就是模拟多轮的对话,然后再回过来判断当前的状态到底走哪一步合适。
这是一个用深度强化学习来做对话状态跟踪的简单状态,比如用户输入了一句话,通过语音识别,它可以有一个状态的管理,然后去管理这个状态,通过一个策略来控制它的输出。当然它中间核心的一个部分是有这个 Reward 函数,在对话里,这个 Reward 函数就非常重要,一般情况下它也不太好定义,因为我们对话,它到底什么算合适,什么算不合适,这个还不是特别好控制的。
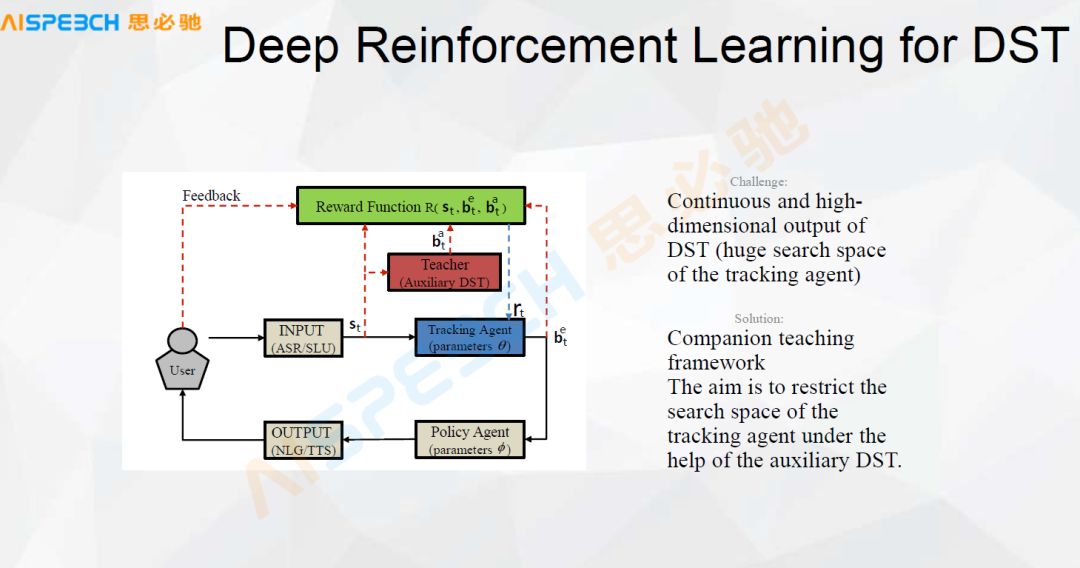
我们来看一下用强化学习来做对话,简单总结一下,在一个状态 S 下它可能有 m 种操作,我们不知道这个 m 种操作哪一种能带来什么样的回报,所以我们做一个探索,去探索每一种可能操作的回报,利用这种回报做一个响应,做一个决策或者对这个回报做一个打分。
另外也有用对抗网络做的,但对抗网络有一个问题,实际上也不太好控制,并且有些情况下可能会强制这些对话的走向,并且对抗网络它的稳定性也是一个问题,这个训练过程中的稳定性也是一个问题。

不管是深度学习,还是传统机器学习,在对话的 NLU 以及对话管理中的一些方法或者作用,前面讲的都是一些现有的方法,怎么来做的,但是它里边都会有一些问题,机器学习的方法很多时候,如果生成式的那就不好控制它到底生成的和这个相关还是不相关,很难判断。如果是检索式的,用户说的这句话,不管怎么着都会给它一个检索答案,到底这个答案是给用户还是不给用户,用户说了一个不相关的问题,我可能也会给它检索出来一个答案,答案是给还是不给?这也是一个问题。实际上这里边就用到知识,这个过程中就非常重要了。
知识在这里边分为两种,一种是知识图谱,严格的知识图谱,这里边 KG 的这部分。另外一些是语言的知识,比如说语言的搭配、语言语法的转换、拼写的问题、领域的问题,实际上还包括一些领域词的问题,相似词、同义词,这些东西在自然语言发展,这么多年实际上已经积累了很多这方面的知识,但是这些东西在现在深度学习里边实际上很难结合进去。
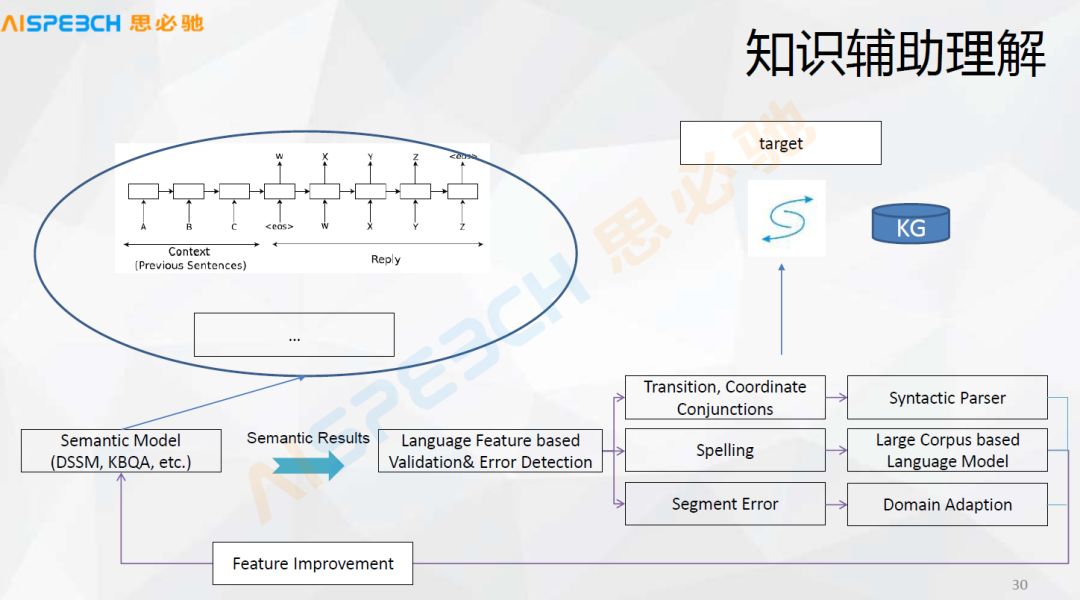
通过上面提到的相似度计算模型我们可以完成前面说的自然语言的相似度计算的问题,但是我们给了这个答案很有可能是不对的,所以说经过这些语言的特征以及 KG 的知识,把知识作为验证候选的证据,深度语义模型给出多个候选答案,我们对于这种可能的各种侯选,通过知识图谱或者语言现象对它做一个分析,然后去找到一些证据,这些证据再来验证去选哪一个答案。因为一般情况下对于直接用严格的知识图谱来解析一个问题的时候有一个问题,很多时候我们无法严格地去解析出来这个问题,只能解析出来一部分。
附葛付江老师建议,及相关基础内容的工具包。

——【完】——
在线公开课 知识图谱专场
◆
精彩继续
◆
时间:8月23日 20:00-21:00
添加微信csdnai,备注:公开课,加入课程交流群
参加公开课,向讲师提问,即有机会获得定制T恤或者技术书籍



