博客 | 一文看懂任务型对话中的对话策略学习(DPL)

本文原载于微信公众号:AI部落联盟(AI_Tribe),AI研习社经授权转载。欢迎关注 AI部落联盟 微信公众号、知乎专栏 AI部落、及 AI研习社博客专栏。
社长提醒:本文的相关链接请点击文末【阅读原文】进行查看
前面写了对话系统中的SLU之领域分类和意图识别、槽填充、上下文LU和结构化LU、对话状态追踪(DST)、以及NLG,今天更新任务型对话系统中的DPL。DPL也叫DPO(对话策略优化),跟DST一样,DPL也是对话管理(DM)的一部分,而DM是任务型对话中至关重要的一部分。说个非严格的对比:如果把对话系统比作计算机的话,SLU相当于输入,NLG相当于输出设备,而DM相当于CPU(运算器+控制器)。
1. 简介
对话系统按功能来划分的话,分为闲聊型、任务型、知识问答型和推荐型。在不同类型的聊天系统中,DM也不尽相同。
1.1. 闲聊型对话中的DM就是对上下文进行序列建模、对候选回复进行评分、排序和筛选等,以便于NLG阶段生成更好的回复;
1.2.任务型对话中的DM就是在NLU(领域分类和意图识别、槽填充)的基础上,进行对话状态的追踪(DST)以及对话策略的学习(DPL),以便于DPL阶段策略的学习以及NLG阶段澄清需求、引导用户、询问、确认、对话结束语等。如果不太明白每个阶段的具体流程,可以看看我之前发的文章“任务型对话系统公式建模&&实例说明”。
1.3.知识问答型对话中的DM就是在问句的类型识别与分类的基础上,进行文本的检索以及知识库的匹配,以便于NLG阶段生成用户想要的文本片段或知识库实体。
1.4.推荐型对话系统中的DM就是进行用户兴趣的匹配以及推荐内容评分、排序和筛选等,以便于NLG阶段生成更好的给用户推荐的内容。
今天我们来分享任务型对话系统中的DM之DPL,后续也会分享其他三类对话的DM。
2.DPL中的状态建模和实例说明
2.1 DPL和DST
前面也说了DST+DPL组成了任务型对话中至关重要的DM,在开始介绍DPL前,先来看下DST和DPL的关系,以便于从整体上把握整个对话系统。

任务型对话的整体结构

DST在对话系统中的位置
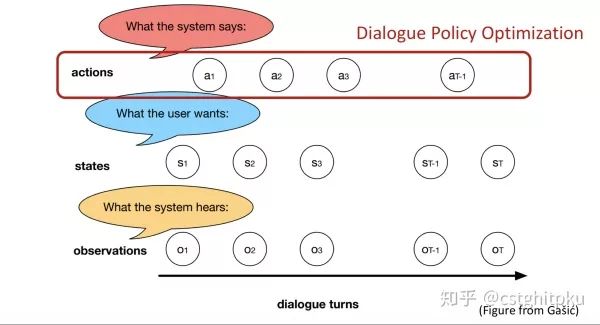
这里说下dialogue act,按我的理解act包括两类:用户的act和系统的act。
针对用户时,主要是识别用户act,dialogue act对应于SLU,包括意图和领域识别(一般是分类)+ 槽填充(一般是序列标注)。
针对系统时,主要是识别系统act,dialogue act对应于DPL,表明在限制条件(之前的累积目标、对话历史等)下系统要执行的动作(接下来的策略),这个动作可能不是追求当前收益最大化,而是未来收益最大化。
至于dialogue act是个什么任务,我感觉分类、序列标注、结构预测都OK。其对应的输入输出应该就是SLU的输入输出、DPL的输入输出。
2.2 DPL建模和实例说明
说到DPL就离不开DST,所以这里再重新回顾一下DST的建模,然后再对DPL建模。
何谓对话状态?其实状态St是一种包含0时刻到t时刻的对话历史、用户目标、意图和槽值对的数据结构,这种数据结构可以供DPL阶段学习策略(比如定机票时,是询问出发地还是确定订单?)并完成NLG阶段的回复。

对话状态追踪DST:作用是根据领域(domain)/意图(intention) 、曹植对(slot-value pairs)、之前的状态以及之前系统的Action等来追踪当前状态。它的输入是Un(n时刻的意图和槽值对,也叫用户Action)、An-1(n-1时刻的系统Action)和Sn-1(n-1时刻的状态),输出是Sn(n时刻的状态)。
S𝑛 = {Gn,Un,Hn},Gn是用户目标、Un同上、Hn是聊天的历史,Hn= {U0, A0, U1, A1, ... , U𝑛−1, A𝑛−1},S𝑛 =f(S𝑛−1,A𝑛−1,U𝑛)。
DST涉及到两方面内容:状态表示、状态追踪。另外为了解决领域数据不足的问题,DST还有很多迁移学习(Transfer Learning)方面的工作。比如基于特征的迁移学习、基于模型的迁移学习等。
DPL基于当前状态(state)决定系统需要采取action。它的输入是Sn,输出是An。
S𝑛 = {Gn,Un,Hn},An是系统的Action,A𝑛 ={Dn, {Ai, Vi}},Dn是对话类型,Ai、Vi是第i轮对话的attribute和其value。DPL一般会建模成强化学习或深度强化学习(从不同维度区分的话有非常非常多的变种,后面一一介绍)。
另外为了解决领域数据不足的问题,DPL还有很多迁移学习(Transfer Learning)方面的工作。比如线性模型迁移学习、高斯过程迁移学习、BCM迁移学习等。
为了在抽象的建模的基础上加深理解,看个小例子:



2.2 DPL的整体框架
前面也说了,DPL一般建模成强化学习或深度强化学习(四个深度学习的主要发展脉络之一,具体见我之前的文章“一文看懂深度学习发展史和常见26个模型”)。下面看看DPL的框架。是很典型的强化学习在NLP领域的应用,因为DPL很适合强化学习(分步决策)。所以如果有人想利用强化学习在对话学习发论文,欢迎联系我,我也感兴趣,咱们可以合作。


3. DPL
先来看看我总结的DPL的方法汇总,注意我没有整理基于规则的DPL(基于规则的方法虽然可以较好利用先验知识从而可以较好解决冷启动等问题,但是需要太多人工、非常不灵活、扩展性和移植性很差)。

下面分别介绍一下对话系统中的不同DPL技术。
3.1 Value Based DPL(http://mi.eng.cam.ac.uk/~sjy/papers/lgjk09.pdf Lefevre et al., SIGDIAL 2009 )(Gaši ́c et al. 2014)(Li et al., Interspeech 2009)( Daubigney et al., 2012)
Lefevre et al., SIGDIAL 2009
k近邻+ 蒙特卡罗算法+ POMDP(部分可观察马尔可夫决策过程)做DPL,这个题目起的很贴近原文,也是这方面开创性的工作之一,虽然时间有点久远,但还不失是一篇好文,尤其是一些场景下的工程实现,因为本方法适合加规则和trick。


Gaši ́c et al. 2014
高斯过程 + POMDP(部分可观察马尔可夫决策过程)做DPL,本文一作是对话领域非常非常有名的学者,本文也算是开创性工作,不过感觉除了公式就是公式,看起来可能比较枯燥。另外,这个文章感觉对现在(深度学习和强化学习火起来之后)的论文没多大帮助,所以不再赘述。
Li et al., Interspeech 2009
LSPI-FFS(最小二乘策略迭代+快速特征选择)做DPL,具有很高的效率,并且可以从静态语料库或在线中学习。另外,这个方法能够更好地处理在对话模拟中评估的大量特征,设计者可以提出一大组潜在的有用特征,因此在当时达到了SOTA的效果。
Daubigney et al., 2012
POMDP(部分可观察马尔可夫决策过程)+离线学习做DPL。提出了一个样本有效、在线和非策略强化学习算法来学习最优策略。该算法结合到一个紧凑的非线性值函数表示(即多层感知器),能够处理大规模系统。之前在线学习的,一般处理的规模比较受限。
3.2 Policy Based DPL(Jurcícek et al. 2011)(Wen et al. 2016b)(Su et al. 2016)
Jurcícek et al. 2011
Natural Actor and Belief Critic: 基于POMDP利用强化学习算法来学习DPL的参数。本文的理论还是很扎实的,分析也比较到位。另外提出了几个算法,我感觉还是不错的。感兴趣的可以看看,如果不明白,咱们可以讨论。这几个算法我大概都看过了,也基本都懂。
Wen et al. 2016b
前面哪些论文比较久远,只有一部分参考价值,这篇文章非常有价值,算是端到端任务型对话的开创性工作之一,同时也是代表性工作之一,说他是做任务型对话必看的论文之一也不为过,质量非常高,本文几个作者在这个领域也都很高产。这篇论文,我后面应该会单独细讲,感兴趣的可以先看看,也可以等我分享。

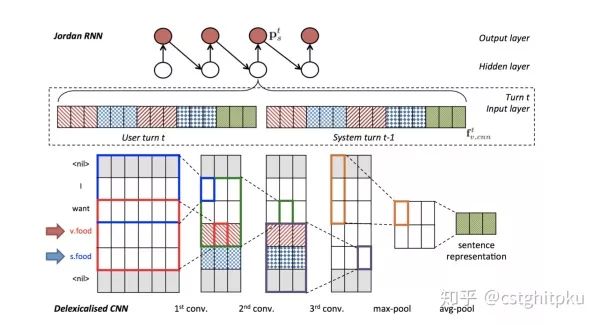
Su et al. 2016
跟上一篇基本上是同一拨作者,同一时期做的类似的内容。本文主要体现出DM中的持续学习。系统首先通过监督学习从一组对话数据中学习,然后通过强化学习不断改进其行为,所有这些都基于梯度的单一模型上做。使用强化学习进一步提高了模型在两种交互设置下的性能,特别是在高噪声条件下。
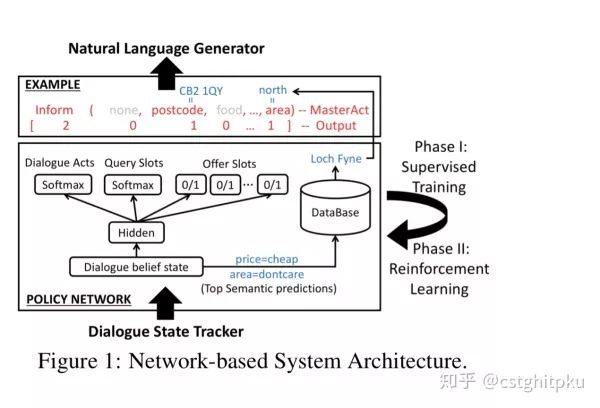
系统结构
3.3 Actor Critic DPL(Su et al., SIGDIAL 2017)
Su et al., SIGDIAL 2017
基于监督学习,利用Actor-Critic强化学习做DPL,具有很强的样本有效性。针对深度强化学习算法学习速度慢、初始性能差的问题,本文提出了两种兼容的方法。主要解决了效率问题和早期阶段学习的问题。

3.4 基于迁移学习的DPL (Genevay and Laroche 2016 )(Gaši ́c et al. 2015b )(Gaši ́c et al. 2015)
Genevay and Laroche 2016
本文主要针对User Adaptation,提出了迁移强化学习方法,定义跨领域的相似度计算方法,仅将不同的数据点传输到目标域。
Gaši ́c et al. 2015b
基于高斯过程的Q-learning,传递均值函数和协方差函数依赖于跨域核函数,Cardinality based slot matching。
Gaši ́c et al. 2015
BCM(Bayesian Committee Machine)迁移学习的Q-learning,BCM是在不同领域的不同数据集上训练的高斯过程策略的集合,本文提出了基于熵的跨域核函数。
3.5 其他方法
除了以上方法,还有 Online Training DPL (Su et al., Interspeech 2015 )(Su et al., ACL 2016);Interactive RL DPL (Shah et al., 2016)等。这些方法都有很不错的参考价值,但是他们不是只关注DPL一方面了,还会关注对话系统中的其他东西,所以不再单独讲解,感兴趣的可以私下找我一起讨论和学习。


简单总结下,目前DPL相关的论文其实在任务型对话中相对算少的,至少远远少于SLU和DST,很多方法比较久远,而最新的一些方法又容易忽略DPL(毕竟DPL相比DST更容易点),更甚至很多DPL跟DST或NLG已经joint一起训练和学习了。目前主流的方法是(深度)强化学习。不过我感觉这一块还是值得深挖的。
4.不同DPL方法的对比
以上介绍了多种对话系统中的DPL技术,下面简单总结下它们的优势和劣势。

5.DPL技术的评估
任何一项技术想要取得进步,那么他的评测方法是至关重要的(就相当于目标函数之于机器学习算法),所以我列出一些关于DPL的评估。遗憾的是,目前DPL的评估我感觉并不成熟,这也是制约DPL发展的一个重要原因,如果谁能想出更好的评估方法或整理出一个业内公认的高质量数据集,那么一定会在DPL(甚至是对话系统)领域有一席之地,引用量也会蹭蹭的上涨。

6.本文涉及到的Paper
6.1 Policy-Value Based
6.1.1 Grid based Q-function
k-nearest neighbor monte-carlo control algorithm for pomdp-based dialogue systems. In Proceedings of the SIGDIAL 2009 Conference. Lefevre et al., SIGDIAL 2009
6.1.2 Linear model Q-function
Reinforcement learning for dialog management using least-squares policy iteration and fast feature selection. Li et al., Interspeech 2009
6.1.3 Gaussian Process based Q-function
Gaussian processes for pomdp-based dialogue manager optimization. IEEE/ACM Transactions on Audio, Speech, 2014. Gaši ́c et al. 2014
6.1.4 Neural Network based Q-function
Off-policy learning in large-scale pomdpbased dialogue systems. In 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Daubigney et al., 2012
6.2 Policy-Policy Based
6.2.1 Softmax policy function
Natural actor and belief critic: Reinforcement algorithm for learning parameters of dialogue systems modelled as pomdps. ACM Transactions on Speech and Language Processing (TSLP), 7(3):6, 2011. Jurcícek et al. 2011
6.2.2 Neural network policy function
Continuously learning neural dialogue management. Su et al. 2016
A network-based end-to-end trainable task-oriented dialogue system. Wen et al. 2016b
6.3 Policy-Actor Critic
6.3.1 A Q-function is used as critic and a policy function is used as actor.
Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management ,Su et al., SIGDIAL 2017
6.4 Transfer learning for Policy
6.4.1 Linear Model transfer for Q-learning
Transfer learning for user adaptation in spoken dialogue systems. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems. Genevay and Laroche 2016
6.4.2 Gaussian Process transfer for Q-learning
Incremental on-line adaptation of POMDP-based dialogue managers to extended domains. In Proceedings of the 15th Annual Conference of the International Speech Communication 2014.
POMDP-based dialogue manager adaptation to extended domains. In Proceedings of the 14th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 2013.
Distributed dialogue policies for multi domain statistical dialogue management. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Gaši ́c et al. 2015
6.4.3 Bayesian Committee Machine transfer for Q-learning
Policy committee for adaptation in multi-domain spoken dialogue systems. 2015. Gaši ́c et al. 2015b
6.5 Neural Dialogue Manager
Deep Q-network for training DM policy
End-to-End Task-Completion Neural Dialogue Systems, Li et al., 2017 IJCNLP
6.6 SL + RL for Sample Efficiency
Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management ,Su et al., SIGDIAL 2017
6.7 Online Training
Policy learning from real users
6.7.1 Infer reward directly from dialogues
Learning from Real Users: Rating Dialogue Success with Neural Networks for Reinforcement Learning in Spoken Dialogue Systems, Su et al., Interspeech 2015
6.7.2 User rating
On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems, Su et al., ACL 2016
6.8 Interactive RL for DM
Interpreting Interactive Feedback
Interactive reinforcement learning for task-oriented dialogue management, Shah et al., 2016
以上,我几乎涉及到DPL中的所有内容,如果看完之后不懂,欢迎找我私聊讨论。因为还没回去,本文完全是挤时间写的,可能会有问题,如果有问题欢迎告知。另外,我这两天就回去了,到时候会更新的更好。

点击 阅读原文 ,查看本文更多内容↙


