微软小冰:全双工语音对话详解
讲师 | 周力
来源 | AI科技大本营在线公开课
微软小冰第六代发布会上正式宣布上线全新的共感模型,同时也开始公测一种融合了文本、全双工语音与实时视觉的新感官。这项新技术可以实时预测人类即将说出的内容,实时生成回应,并控制对话节奏,从而使长程语音交互成为可能。而采用该技术的智能硬件设备不需要用户在每轮交互时都说出唤醒词,仅需一次唤醒,就可以轻松实现连续对话,使人与机器的对话更像人与人的自然交流。
本期公开课中,微软小冰全球首席架构师及研发总监周力博士将介绍微软小冰在全双工语音对话方面的最新成果,及其在智能硬件上的应用和未来将面临的更多技术产品挑战。
以下是公开课演讲速记整理
首先介绍一下微软小冰在全双工对话上的部署。我们这套技术事实上是从两年之前,大约是在2016年的7月份,我们做了第一个落地,那个时候我们是和有信IP电话进行了合作,它可以通过网络电话,你直接在电话上和小冰聊天,同时我们在北京科技馆等等地方,你还能看到小冰的电话亭,你在那里面就可以跟它去打网络电话。
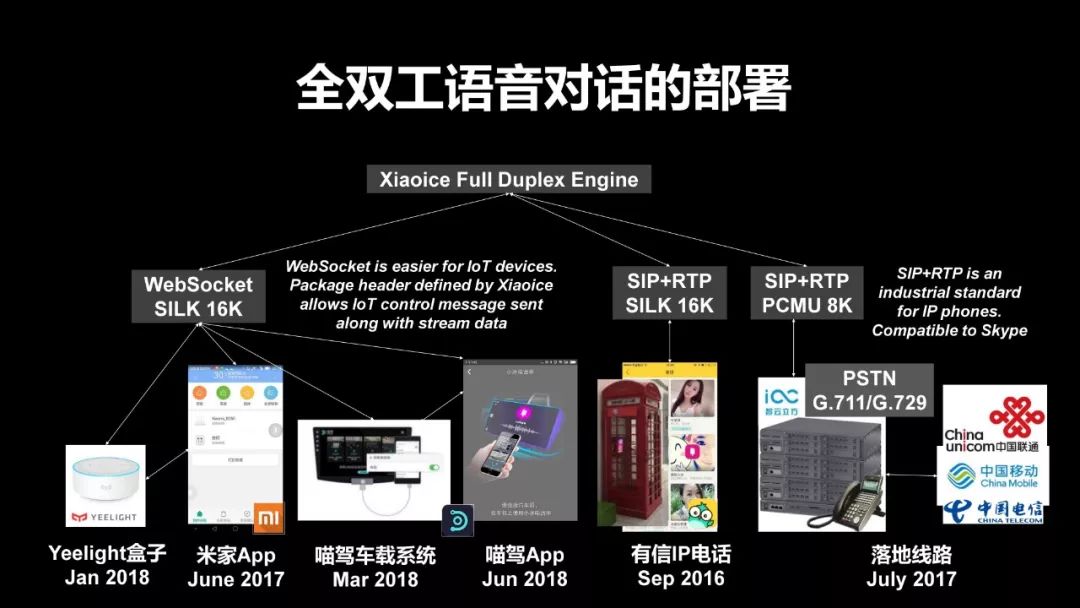
之后我们又和小米合作,在小米控制智能家居的APP米家APP里做了一个可以接通电话,去控制各种智能家居,包括跟它去聊天,使用各种功能的助手,这个是2017年的6月份。在2018年1月份,我们和小米,还有小米生态链的叫Yeelight公司共同推出了一款新的语音设备,它叫Yeelight智能语音盒,这个盒子里同时拥有小米自己的小爱同学和微软小冰两个智能助手。而微软小冰的这个智能助手使用的就是全双工语音对话。最后我们和一个叫喵驾的车载系统进行了对接,同时我们和三大运营商有了落地,我们可以直接让小冰打电话给真实的用户,这个是全双工现在的技术使用的范围。

我们想给大家定义——到底什么是全双工?全双工语音和我们现在所熟悉的一些语音助手,不管是手机上的,还是在智能音箱上和其他的智能家居,它有什么样的不同?
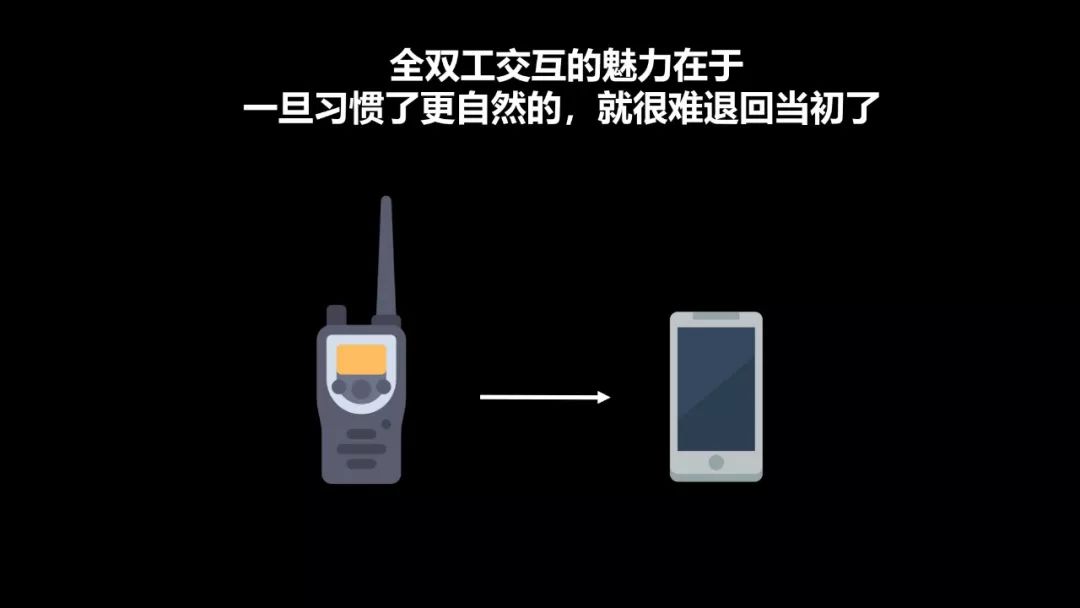
第一,想说明全双工这个名词其实并不是人工智能或者说语音AI的时代才出现的,它的英文叫Full Duplex,Full Duplex这个词事实上早在大概100年前就已经很明确了,它是一个通信的术语,它的通信术语定义的就是一个实时的、双向的语音信息的交互,就叫全双工。而我们大家所熟悉的全双工的最重要的一个应用就是电话,我们以前去打各种各样的电话,双方都可以同时说话,这个就叫全双工。而与之对应的所谓半双工,其实最典型的传统设备就是一个步话机,我们大家都知道步话机,我摁下来的时候就只能我这边在说,我说完了之后我说over,然后对方再把他的步话机的按纽按下去进行对话。这是和全双工对应的半双工。
从通信技术上,如果是人和人之间的对话的话,全双工我们100年之前就已经解决了。到了现在的人工智能时代,到了语音的时代,我们通信有了一个新的需求,就是人和机器人进行对话,我们不再是两个人之间,有一方是一个AI。由于一些历史上的原因,比如说我们最近的10年,即时通讯软件,不管是它的前辈QQ、微信这些风靡,让我们人和人之间从一个面对面或者说打电话这样的一种直接的双向交流的方式,突然人之间开始尝试着采用一个不是实时双向的交流方式。比如说我们有的时候会发个短信,我们会发一个语音的消息,就是人原本的最自然的一种交流的方式,由于科技的发展,我们其实产生了一些分支。那么作为科技的研究者,我们也就自然而然地开始习惯说当我们切换到一个人和一个人工智能进行交流的时候,我们会首先想到的是,我给你发一条语音消息,然后人工智能给你回一条语音的消息。
我们也看到市面上我们熟悉的绝大多数的智能音箱,或者更早期的在手机上的语音助手,都是这么实现,发语音消息。很简单,我发一条消息,收一条消息。所以我们看到语音交互它最开始出现的形态是单轮交互,体现到智能音箱的时候,它其实很不方便,因为智能音箱每次我们都需要一个唤醒词,我需要说Amazon,巴拉巴拉一句话,说第二句话的时候我还要再说唤醒词,巴拉巴拉。

后来,亚马逊自己也意识到这个问题之后,它开始尝试进行一些改进。比如说当它进行一个比较复杂的任务,我们说打一辆出租车,其实很难时间、地点用一句话都说清楚,所以它又引入了一个新的概念叫多轮概念,就是当我的任务机器判断没有完成的时候,机器把这句话说完了,它重新再把麦克风打开再去听,这个就叫多轮交互,就是还是像步话机一样,双方只有一边可以说话,但是等AI说完了之后,它会重新打开它的耳朵去听说接下来人会说什么。
最后,其实像典型的科大讯飞,它尝试了一种叫AIUI的一种模式,它在试图去持续地监听用户发进来的语音消息,然后它每听到给出一个回答。但很可惜,这样的模式其实有非常大的缺陷,因为每播放一个回答,它其实都需要占用一定的时间。比如如果一个人连续问了两个问题的话,对于机器人可能第一个问题没回答完,第二个问题又出来了,就把原来第一个问题覆盖掉。这样的话,一个连续监听的模式事实上体验反而比之前的单轮交互、多轮交互要更差,会变得非常零乱,有的时候会让用户不知所措。这也正是为什么虽然科大讯飞应该在我们推出全双工的模式之后的不到半年,它就在叮咚音箱上给了一个小的开关,说你可以尝试我的一种新技术叫AIUI,但它其实从来没有敢在自己的产品里真正缺省地打开AIUI的模式,因为这里的问题太多了,它甚至还不如单轮交互,每一次让用户说一个唤醒词方便。
最后我们提到的就是微软小冰,应该说在全世界首创的这种全双工的模式,也是Google在去年3月份做了一个很大的发布会,包括他们宣布了Google Duplex。全双工的模式是真正的人和机器都是双向的脱离掉消息的束缚,我们只有一个连续的上行的语音流,把用户的声音传到人工智能耳朵里,然后再有一个同步的下行的语音流,把人工智能的话传到人的耳朵里,就好像人和人在打一个电话一样,我们管这个叫全双工的语音交互。
而从很多实际的使用过我们跟小米推出的Yeelight盒子的用户的反馈和一些科技媒体的反馈,我们也非常有自信地看到,你一旦习惯了这种全双工的交互的话,事实上你很难再退回到每说一句话就要说一次唤醒词这样的使用习惯,因为它确实很不方便,很不接近于一个自然的交互方式。一旦你习惯了像微软小冰这样的全双工交互,你可能再用别的音箱的话你会频频地忘掉说我每说一句话还要讲一个唤醒词,因为那样实在是太累了,也正是这个原因,我觉得它阻止了智能音箱更好的能像手机,我们都知道,智能音箱现在炒得很火,各大厂商都在疯狂地去占领这个山头,但是我们从用户的角度来说,没有觉得它那么地不可或缺,没有像我们手中的智能手机一样,我们恨不得一天都离不开它。为什么?因为使用它所耗的能量还是太大。我们如果使用它不能很放心地去使用一个设备,我们还需要去记住每说一句话要说一个唤醒词的话,那么它一定无法能真正地走入千万百姓家,它只可能提供到一些科技爱好者,一些原因尝新的人的小范围之内。这样,我们认为全双工是整个人机之间语音交互的大趋势。
如果熟悉微软小冰的人可能会知道,我们从2014年就开始在做一个对话的机器人,在对话过程中我们别发现事实上以前很多的助手它都会看中于说我面向单个任务,比如说我去召唤起一个机器人,我就是为了完成一件事,比如说我要定一个餐,或者说我就要查一下今天北京的天气,这是传统像Siri,也包括像微软自己的Cortana它所面向的一个AI。但是作为一个真正的AI,通过微软小冰的探索我们越来越相信它其实应该像你身边的一个普通人,一个朋友一样,它是一个全程的对话。当我们的对话中可能穿插着很多很多的议题,可能会天马行空,我跟你对话的目的是说话,是交流的本身,而不仅仅是为了完成某一个任务,这才是真正我们认为对于我们的未来有意义的一个人工智能。
讲这么多,大家可能稍微吊起胃口说如果能实现全双工的这样一个人机对话,可能是一个很美妙的东西,但是这个里面会遇到很多的技术难题,我现在跟大家一一分析说如果我们想实现全双工,那么它这里边需要有什么?
第一大技术特征,我们管它叫边听边想,也就是说不等一句话说完,再进行语音识别。传统的说,因为以前其他的是我攒够了一个消息,把语音消息发过来再进行识别。可是大家想,人和人之间的交流其实不是这样的,我们在开会的时候,通常老板的问题问到一半的时候,我们已经在开始琢磨该怎么回答了,这样老板语音刚过,我们就可以把答案很流畅地给出来。这个才是人和人之间交流的方式。对于人工智能也一样,当我交互的方式不再是一个语音消息,而是一个语音流的时候,我就不应该再等到一句话都说完了再进行思考,应该随时去思考,它听了一半的话就开始去预测这整句的意思是什么,这样它就能以更快的速度把这个回答给出来,而且能实现很多动态的预估。这是其中的一个重要的技术特征。

全双工语音的第二个重要的技术特征,就是它必须拥有良好的节奏的控制,为什么?因为到了全双工的方式,事实上会变得很复杂。比如说我们在微信中大家互相去发语音消息的时候,什么时候听我收到的一条语音消息是由接收方来决定的,我收到一条语音消息我可以选择我现在就把它播出来听,如果我正好正在说话,我也可以选择先不听,等我把这句话录完了发出去了之后再听前面的用户给我发的语音消息,这是由接收方来确定。所以我们以消息进行语音的交互的时候,好像并不觉得节奏控制是一个多么重要的事情。可是我们一旦进入了一个面对面或者说像电话一样的模式的时候,它会变得非常重要。
如果有年纪大一点的听众的话,他可能会回忆到早年,大概20多年前,如果打一个国际长途,由于那个时候技术的限制,它是有非常高的延迟的,有时候我说一句话,对方可能几秒钟之后才能听到。那个时候人和人之间打国际长途非常容易说乱了,抢话或者说陷入尴尬的沉默,就因为这个里面有非常高的延迟。人和人之间尚且如此的话,那么人和机器之间就会有更多的挑战。

我们第一个需要面对的挑战事实上是说AI自己都需要有一个节奏的控制,为什么?因为AI播的上一句话之间的时候,如果用户又问了一句,那么AI准备了下一个答案的时候,在下一个答案已经被准备好的时候,前面的答案,因为每一句话,它的语音事实上占有了一定的时长,它可能前面的话还都没有播完,那么下一句话的答案它已经想好了。这个时候我该怎么办?它有很多不同的策略。比如说我认为后面一句话非常重要,我立刻就把后面一句话,前面的话就止住不说了,我把后面一句话说出来;或者我觉得后面的话没那么重要,那我就坚持把我现在说的这句话说完就行。最后,还有可能说,我先把我这句话说完了,但是说完之后,第二个问题我也会接着回答。AI自己的话和自己的话之间就有一个很复杂的协调的任务,显而易见的AI和用户之间也有一个节奏协调,如果两个人抢话,那么AI是不是应该止住嘴去让着用户说话?或者说如果AI想说一句话的时候,它是不是会考虑一下说我这句话可能也没那么重要,如果这时候对方的用户正在说,我这句话就不说了?或者反过来是说,我这句话太重要了,虽然你正说到一半,但我也要打断你。这里面有很多节奏协调的技巧。这些技巧哪怕是对于我们人类的成年人来说其实都是一种语言的艺术,我在开会什么时候该我说话,什么时候不该我说话,这个其实都是一个我们在学习和工作的过程中,其实都会不断去摸索,不断去成熟、去掌握的一个技巧,更不要说对于一个人工智能了,这里面其实我们会有很多新的问题在。
除此之外,原来我们在消息的情况下,通常就是你发一条我发一条,这是一个对称的对话,但是真正到了双向实时语音交互的时候,对话有可能就不再是对称的了,就比如说一个心理医生和他的病人进行对话的时候,经典的就是有时候心理医生可能说的很少,他就偶尔去引诱着病人,让他把自己内心的世界倾诉出来就好了。这种对话中有一个倾听者,有一个倾诉者。AI和人之间的对话其实也可以这样,它不一定非得是你说一条我答一条这样的对称模式。这里面就带来了很多更不一样的想象空间。
第三个在全双工中的一个技术特征就是传统意义上我们对语音识别的理解,就是我们听到了一段语音,我们要识别这个语音中所包含的文字,但事实上,在一个真正的全双工语音的环境中,也就是说对于一个人的听觉的理解能力来说远远不止于此。比如说我们要有对身份的识别,有对声纹的识别,这句话是我爸爸说的,还是我爷爷在说,还是我儿子在说。还有对背景噪声的识别,还有回声消除,然后还要判断它是不是在和人工智能对话。

典型的一个例子,比如说我唤醒了一个人工智能,我跟它聊起来了。这时候我突然接了一个电话,从麦克风的收音来讲,我看到我还是在说,但其实我说话的对象已经转移了。那么我如何能去理解这样的场景?
最后还有动态音量的识别,我在什么样的环境下人工智能应该大点儿声,什么样的情况下应该小点儿声?这个里边有很多以前我们在简单的语音消息的交互中不需要去考虑的新的有趣的问题,会在人和AI的全双工语音场景中得到展现。

最后,如果我们想做一个全双工的语音对话的话,很重要的我们必须要有一个核心对话的引擎,它其实也是微软小冰从2014年发布以来,可能最为广大用户所熟知的强项,就是它的通用的语音对话的能力。那么我们在这个里面也就是说微软小冰的语音对话技术,其实最开始我们使用的是检索模型,就是用一个像搜索的方法,把人类以前说过的话用搜索的方法来寻找一个答案。在大概两三年前,渐渐地去转向由深度学习进行的生成模型。至今比如说我们在像微信、QQ,或者那些以消息进行交互的平台上,我们至今使用的是检索模型和生成模型的一个混合。但是在全双工语音环境下,事实上我们发现单纯地使用生成模型它的效果更好。这里边主要的原因是检索模型,大家学过搜索的话,它其实是对一些特别不常见的生僻的词最敏感,哪个词TFIDF最高,它实际上在搜索上就表达得非常显著。但是,对于语音识别引擎来讲,它如果不小心犯一个错误,实际上确实有可能把一个很常见的话,由于我说的不太清楚,经常大家会看到把一个常见的东西会错误地识别成一个不那么常见的东西。由于检索模型它天生的特性,事实上它可能会放大语音识别的错误。而生成模型,由于它深度学习,事实上还是主要学习它一些常见的模板,它对于语音识别结果的容错性会更高。这其实也是微软小冰从对话到全双工语音的探索中得到的一个非常有趣,也希望能跟大家分享的一个经验。
除此之外,由于你是一个长程的对话,就需要一个更好的对于上下文的理解。然后还有,比如你需要开始去判断一些在语音消息中不需要判断的东西,比如说我什么时候应该挂断这个电话?因为可能用户已经不再跟我聊或者说他已经聊的意兴阑珊了,这个智能音箱就应该自觉地把自己关掉。这些是我们会在全双工中遇到的一些新问题。

未来我们会有各种各样的发展方向,我们会从个人的场景,比如说打电话这是一个个人的场景,家庭的场景就是我们现在已经发布的Yeelight盒子,车载场景也是我们发布的。但是再往前走可能在公共场合,比如说一个商场里有一个导购的设备或者有一个大屏幕的设备,甚至说也许未来的某一天,我们试衣的模特是这样,也可以跟你进行交互,但是商场里可能不光你一个顾客,有很多其他的顾客,在公共的场景中他的交互会变得更加复杂。如果你家里同时有多个人,多台设备,他们之间的联动也会非常复杂。
最后一个非常有意思的事情,就是说如果这个机器还有一个眼睛,那么如何跟视觉的感官去结合?如果你有一双眼睛,你看到用户已经在盯着你看说话的时候,可能我们唤醒第一次打通这个电话的唤醒词都不再需要了。或者说我可以借助我的眼睛来察觉你的情绪,察觉你是不是在对我说话,去察觉你的对话应该如何进行调整。这里边都有很多有意思的事情。
刚才黑色的部分其实更多的是给大家介绍了像产品经理也都会感兴趣的,比如对于全双工的一个新的产品形态,它能为人机语音交互带来怎样的不同?它实际上是一个更加复杂,但是拥有更高天花板的一个交互方式。后面我会在剩下的时间,再尽量多讲几点,就是白色底色的就是给技术人员看的更多的全双工的对话技术的细节。

前面也主要介绍了它的一些主要模块,我们现在可以看到这个对比,当我们只需要实现一个以消息作为交互的半双工的时候,事实上我们基本上只需要三个模块:语音识别、对话引擎和文字到语音的转换TTS。而全双工这边事实上至少需要有六个模块,连续的语音识别、语言的对策、对话引擎,然后从文字到语音的转换,我们有一个叫每轮的控制器和节奏的控制器,至少需要这么六个模块。

下面这一个图,应该是说这个技术介绍中最重要的一个图,它会给你去展示全双工是怎么进行连续的识别,进行语言的预测和瓶颈的处理。如果大家今天能看懂这一幅图的话,我觉得今天就没白来,我试图给大家去解释清楚这个图是什么意思。
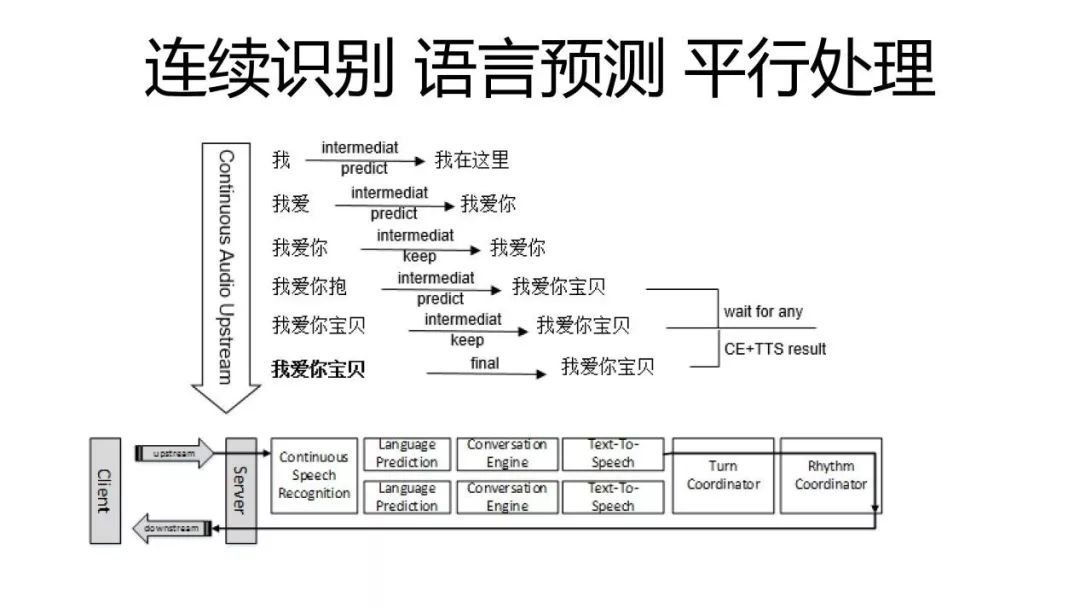
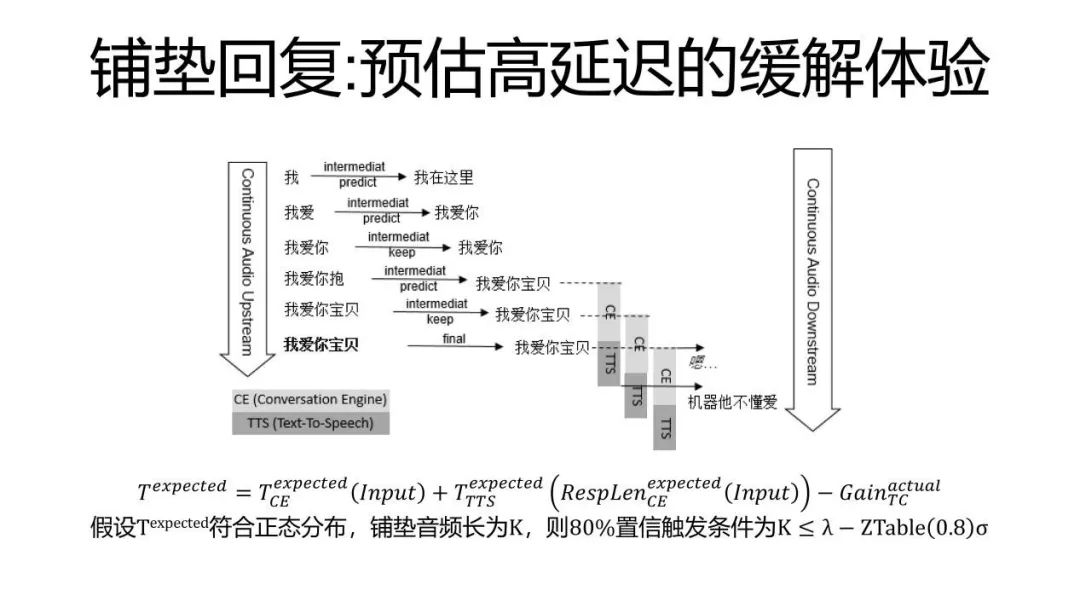
当用户去说了一句“我爱你,宝贝”,这个连续的流,从语音流,从客户端流向了云端,语音识别它会根据它现有听到的最新的语音开始尝试把每一个音节都尽可能地识别出来。这样的话,我们就会看到它每多听到一个音节的时候,它就会突出一个中间的结果,会看到“我,我爱,我爱你,我爱你抱”,这个应该是听了一半,所以它的想象有些不一样。然后“我爱你宝贝”。最后再经过确认,确实这个用户说到这儿的时候有了一定的停顿之后,它最终语音识别的引擎突出了一个最终结果,说这句话最好,最后其实就是“我爱你宝贝”。在这一句话听完整之前,事实上很多的运算就已经被开始进行了。这里边每一个语音识别的中间结果出来的时候,我们都会根据现在的前缀进行一个语言的预测,就是说从概率上来讲,也许用户有可能在说什么,你可以看到,当看到我的时候,我就算猜也猜不到太多。当出了一个“爱”字的时候,它其实已经能猜到“我爱你”了。但后来出了一个“宝”的时候,话锋变了,发现这个最终的话其实也不是“我爱你”,是“我爱你宝贝”。最后事实上当最终结果出来的时候,也验证了我这个猜测是正确的,它就是“我爱你宝贝”。
这里面一个优势就是,其实用户的这个“宝”字刚落下来的时候,经过一个简单的对策,对话的引擎就已经可以开始计算我应该怎么回答“我爱你宝贝”这句话,因为图中的这六条线都在进行平行的计算。等到它确定最后这三个平行的预测全都是正确的时候,它只需要等到这三个回答的计算中最快的那一个结果就可以了,因为它们算的其实都是同一个问题。这无形中就可以让人和AI进行语音交互时候,AI有机会能更快地去给你一个回复,而这个对于一个交互的自然度、流畅度是非常重要的。从我们后台的数据可以看到,哪怕机器的平均回答速度平均起来能快100毫秒,100毫秒其实对于人的感觉来说几乎是感觉不到的,会觉得1/10秒,人是感觉不到。但是只要AI的回答速度能快那么1/10秒的话,那么人类就会很明显地更愿意跟这个机器人聊得更长,我们可以通过像A/B test这样的东西能看到这样的结果。这个就是说,事实上对于人机的语音交互来说,速度是一个非常非常重要的环节。我们有了这种连续识别语音语言的预测,再加上平行的处理,就可以让机器,让AI回答得更快,也能让这整个人机交互变得更加流畅。
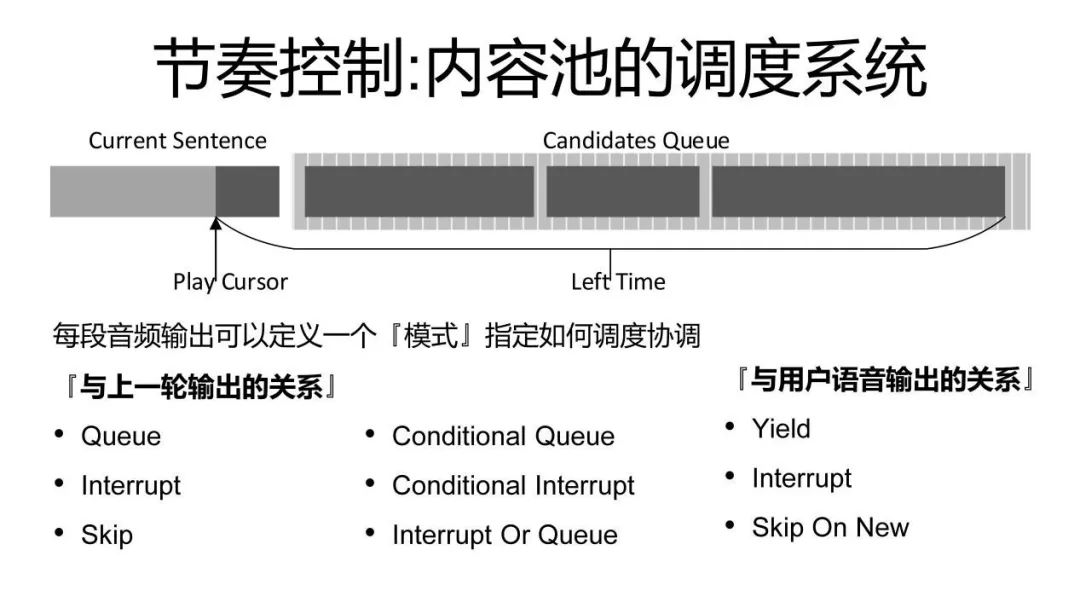
下面一个图解释了说我们如何进行一个节奏控制?事实上我们会把机器现在正在说的话和未来可能要说的话建一个池子,然后它就像有一个播放的指针一样,不断地从这个池子里去拿音频的针,去塞到那个连续的流里。然后每出来一个新的话的时候,我们会通过各种各样不同的输出关系来决定说,我这句话是应该放到播放的最前面,还是应该放到排队的池子里,还是应该直接扔掉?有了这样一个内容的池子的话,我们就可以保证一个稳定的对外音频的输出。这个是节奏控制的方法。
最后还有几分钟时间,我再给大家介绍一下一对多,我们会说非对称的这种动态的回复。这种动态回复又包括几点,其中一个叫铺垫回复,也就是当我觉得可能我还需要想一会儿的时候,人有一个非常重要的技巧,就是我听到了你的话,我会说,嗯,或者说我想想,或者讲英文的人最爱说的well。这句话其实没有表达任何意思,但它在对话的技巧中非常重要,它是让用户立刻知道说我已经听懂你的意思,我知道你跟我说的话了,但是我正在想。我们在全双工的AI实现中同样使用了这样的技术,就是当我听到了这句话,当我自己的预测,觉得我需要较长的时间,我可能需要较长时间才能算出最终回答的语音文件的时候,我先要垫一句“嗯”,或者垫一句“我想想”,然后等什么时候这个语音好了,我就再把它播出来。这样的话,会很大地减轻用户能感知的延迟。第二个避免用户以为你没有听见,我又追问了一句。

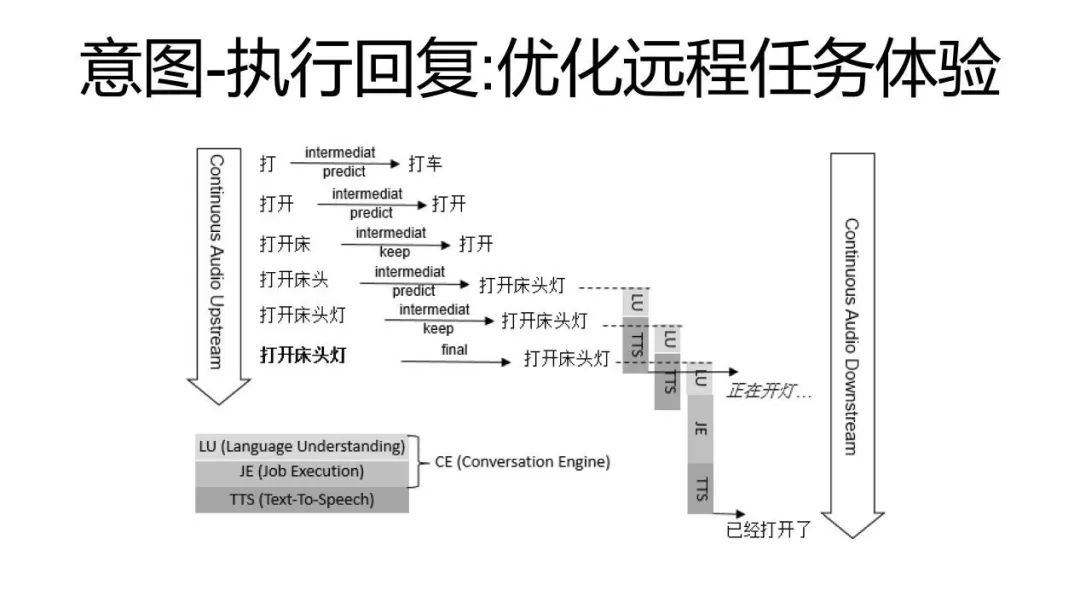
类似的,尤其是在远程的智能家居控制的时候,还有另一种方法,我们叫意图-执行回复。就是在听到中间结果的时候,可能我知道是打开床头灯,但是我事实上如果真正想要把这个床头灯打开,这是一个非常复杂的联动,我需要通过很多的服务器,从云端落到你家里的路由器,然后再由路由器把你的智能家居打开,这是一个非常漫长的过程,通常需要两三秒都是很正常的。对于人工智能来说,这两三秒我再回答,这会让用户说觉得你到底听没听清我?微软小冰在全双工使用的方法是:我首先只要识别出你的意图,那么我不尝试真正执行它,我就先给一个对于你的意图的回复,就是说我先试试或者说我正在开灯,然后等我的智能操作真正完成了,我拿到了它的智能设备传回来的返回设备码的时候,我再告诉他说,你家的智能电视已经打开或者说那个智能电视现在处于离线状态无法打开,再把真正的结果告诉他。所以一个问题事实上我可以拆成两步答案再去回答,这是一种非对称的交互。
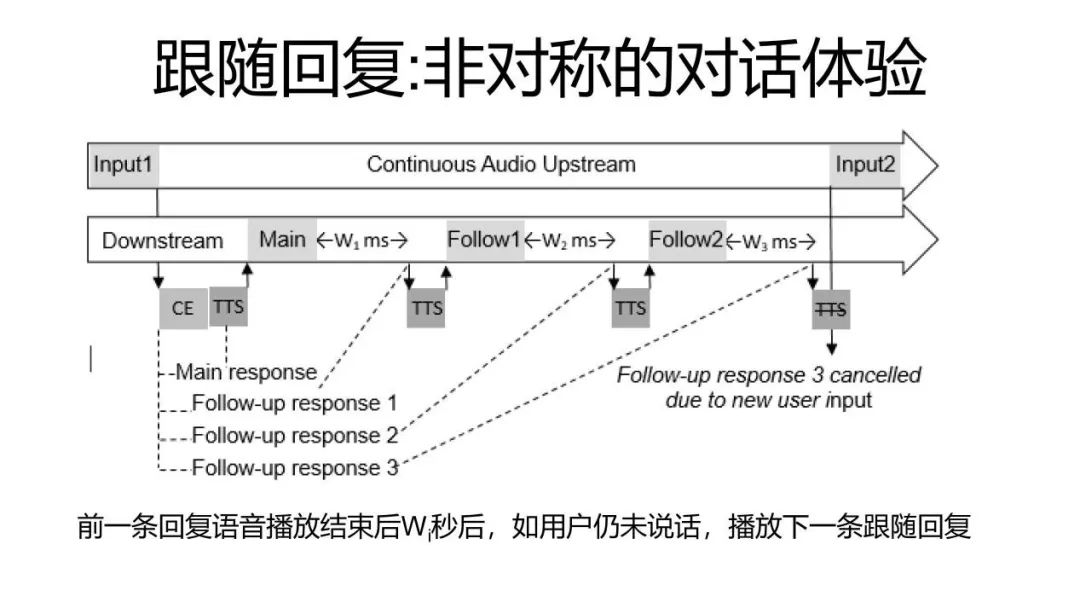
还有更多,比如当一个用户说“我好无聊,你给我讲一个笑话吧”,这个时候人工智能给他讲了一个笑话。讲完笑话之后,它听到用户沉默了,他可能还不高兴,它事实上可以过了几秒钟之后说,“那我再给你讲一个吧”,我可以再讲第二个、第三个,直到用户再说些什么或者说AI自己也觉得无趣了,它再断开。我们可以认为一个主回复中,其实后面可以再挂着很多额外的回复,如果用户没有反应的话,我可以源源不断地把它播出来。
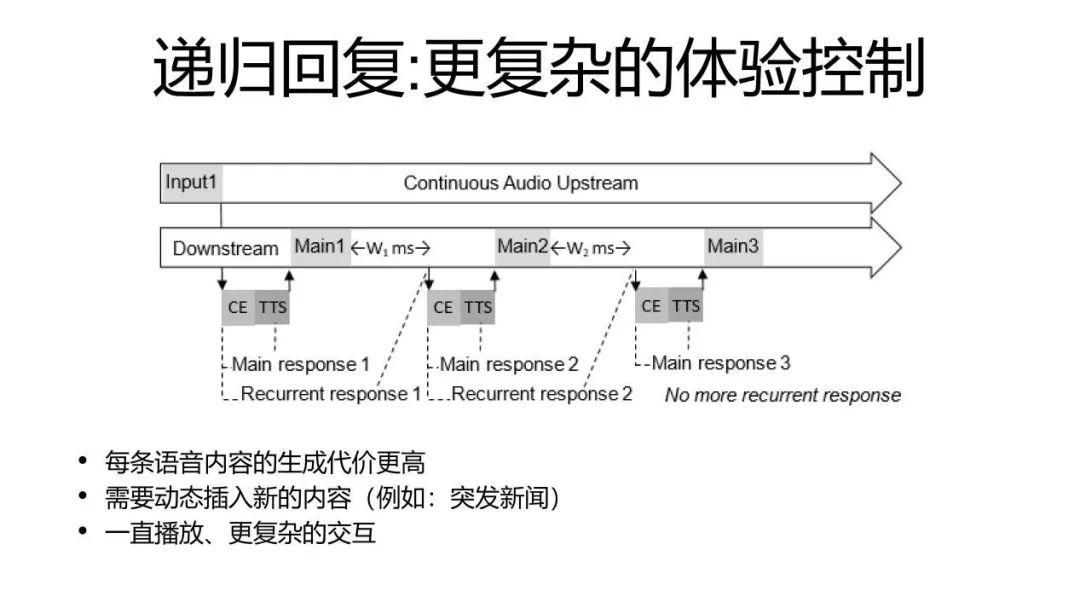
最后还有一种方法是递归的回复,事实上你可以每一次回答完成了之后,如果用户沉默了的话,我可以再向服务端发送一个请求,我再去拿到一些新的内容。这个跟前面这种跟随回复的主要不同在于跟随回复你是一次把所有的结果都拿到了,它是一个一个播,这样它就没有动态调整的能力。而后面这样的方式,每一次其实它都是一个新的计算,比如我在进行一个新闻的播报的话,我就有机会能够插入一些突发的新闻或者说完成一些更复杂的交互。这些都是我们在全双工的技术中引入的一些全新的方式,它也就让我们人和机器之间的交流,从原来这种一问一答的简单交互,可以变成一种可以一对多的或者多对一的一个更复杂的非对称的交互。
今天由于时间的限制,我们就先讲到这里,内容比较多,时间比较少,谢谢大家的参与。
QA
1.小冰是基于LSTM的吗,是检索性的吗?
刚才其实我在介绍的过程中已经跟大家去提了,比如说我们在文字或者普通的语音消息的交互中,小冰她是一个检索式的聊天机器人和深度学习的机器人的融合。全双工语音她是仅基于深度学习模型的,不过在小冰的实现中我们用的是GRU,不是LSTM,主要的原因就是GRU算得更快,而且她对系统的成本,我们每回答用户一个问题她的成本会比LSTM更低一点,所以从工程上最终我们选择了使用GRU,而不是LSTM。通常情况下,类似的模型LSTM得分会稍稍比GRU高一点,但是从工程实践的权衡来说,小冰几乎所有的算法最终选择的都是GRU。
2.预测模型会不会对算力的要求比较高?
确实,本来收到一条消息,我只做一个回答,我如果边听边预测边去想的话,事实上我就会要去回答好多个问题,就是我听一句话,从机器的角度,它其实是平行地进行了好多个计算,确实。但是,这样带来的益处也是非常明显的,所以我们也最终选择了这样的方式,通过优化我们的系统,让这样的平行能变得更有效就可以了。
3.全双工是实时获取对方信息的意思吗?
全双工的意思就是像打电话,就是你时刻在听时刻在说,它的上行流和下行流永远是您每收到一个包你就要发出一个语音包来,哪怕你这个语音包是空包,意思就说我是在沉默。这是一个双向的对称的流,这样我们就叫全双工。比如你用维基或者百科查一下,这是一个很标准的电话的术语,它的定义是非常清晰的。
4.语音识别都需要依赖服务器吗?
应该来讲,从现在的人工智能的实现来讲,你想把那么复杂的人工智能全部放到客户端还不太现实,我们有可能放一小部分逻辑在客户端,但是不管是全双工的语音实现,还是非全双工的语音实现,其实绝大多数的逻辑还都是在云端,而不是在客户端。否则的话,坦率讲,你说你要让客户端能进行一些深度学习模型的计算,这个在成本上也不太划算,我一个智能音箱得卖多贵。
5.全双工怎么过滤AI自身的音频?
这里边有两个,一个事实上硬件上是有非常成熟的回声消解问题,就是绝大多数的智能音箱标准的板上都有回声消解,因为它播放音和收音从物理上来讲它是一个实时的,没有延迟的系统,它在设备端上很容易把这块消除进去。从我们经验来看,除非你把你的智能音箱放到一个大的玻璃板等等的背后,它其实回声消除的效果已经足够好,以至于你收到的音其实是听不到小冰的声音的,但也确实有一些情况下,其实它还会残留一些AI自己的声音。但好在因为AI通常定义自己的声音,它的声音是有自己的特征的。比如小冰的声音,它是有非常典型的小冰声音的声纹的。用户说的声纹和小冰自己说的声纹是不一样的。所以哪怕设备回声消除的消解,由于环境的问题,出现了一点点纰疵,它漏了一些音,回到了我收的这个音里的话,那么通过声纹的识别,在绝大多数的情况下还是可以过滤掉,说原来这块其实不是用户在说,这是不知道怎么把这个音反射回来了。所以就是有了声纹识别的话,就可以为回声消除上双保险。
6.小冰是否可以在聊天的过程中进行情感的判断?
是的,当然这一个问题如果要回答的话就特别复杂了,事实上我们现在有一个很大的议题叫共感模型,也就是我们其实每听到一句话的时候,如果我们说深度模型,它的输入不仅是一句话,它还有很多情感的因素,包含了很多上下文的情感因素在这里边,这个其实是一个非常复杂的议题,有兴趣的人可以去阅读一下跟小冰有关的一些学术论文,我在这里确实不是一句两句能说清楚的,也跟今天全双工的主题延展得比较远,就不详细阐述了。
7.节奏控制里边问题的重要性怎么去评估?
这些评估还是在对话的引擎里就有一些,除了去回答出那句话的时候,你其实就做一些判断,它有很多的信号,我这是一个功能,比如是一个智能家居控制的返回,我自然就是一个重要的东西。如果是普通的聊天,可能是一般。如果我聊天的时候发现这个用户问也没有问,我的回答其实也不知道该回什么的时候,我就认为这是一个没那么重要的。就是对话引擎的设计中其实能看到很多信号,这些信号都能辅助你去判断我的这个回答到底是一个重要的回答,还是一个可有可无的回答。
8.语音助手的智能完善度具体是一个怎么样的评估?
这个好问题,这点小冰其实有一个业界非常独特的评估模型,这个评估的模型也非常地简单粗暴,就是只要人和人工智能聊得越长,我们认为这个聊天就越成功。我们内部管它叫conversation procession,也就是用户和一个AI进行了一次对话的时候,它到底有多少个来回?如果认为说用户说了一句话,人工智能接回来的时候,用户再说一句话我们就认为是第二轮。通常情况下,像传统的助理,比如像Siri这样的助理,它的一次对话的轮数是两到三轮,但是对于微软小冰来说,我们在多数的平台平均是23轮,这是一个非常大的差距。但是从我们过去的经验来看,这是一个评价对话式人工智能的一个非常重要的因素。
9.小冰在噪声环境下的效果如何?
这确实是一个非常难的问题,我们首先需要承认的是在噪声的环境下,不管是半双工、全双工,还是怎么样,其实都非常有挑战,这些挑战可能不光是人工智能的挑战,可能也需要一些硬件的厂商,设计麦克风阵列他们共同的努力和帮忙,才能解决得更好的问题。可能不仅仅是说我是通过AI或者说云端的模型就能单纯地去解决的一个问题,这个在整个业界都是很难的,效果应该说大家都不太好。
10.用什么样的数据结构来保存和更新当前的对话状态?
其实什么样的数据结构不重要,你哪怕就是一个key value table都无所谓,关键你能提取到哪些对话状态?提取得有多准确?这个才是最重要的。
11.如何进行开放域的意图识别?
我觉得这也是一个非常好的题,做一个比喻,就是说很多做人工智能的话,它会试图说我听到一句话,我先去识别它的意图,比如说这是问天气还是问教育,我希望把这分成一个个分支,然后我在每一个分支进行单独的处理。但是从我们小冰在开放领域的对话中的经验来看,这是一个完全错误的方法。就好比说一个披萨上,我们可以撒各种各样的佐料,可以撒菠萝、香肠、青椒,但是我们可以认为说,如果说某一种意图,就是像上面的佐料的话,你哪怕有再多的佐料,你不可能把它拼成一个披萨饼,它一定都会有各种各样的漏洞,而你真要做一个披萨,你首先要做扎实的是那个最基础的饼,你先不要看它是什么意图,你有一个基础的通用的对话引擎能力,你在这个基础之上再去加功能,再去加意图,再往这个饼上去撒各种各样的佐料。用这样的方法才能真正地构建起一个好的人机对话的引擎,如果你试图把它分解成各个意图的子问题的话,那么其实这是一个最终无解的问题。
12.在哪里能体验到微软小冰全双工电话的功能?
当然了,你如果想要体验目前小冰实现得最好的全双工的功能的话,它就是在小米米家卖的Yeelight的语音助手盒子,这个是小冰,包括音乐,包括智能的控制,也包括甚至说那个智能盒子,你找不着手机的时候,它能帮你打通电话,你打通了这个电话又能跟你对话,在功能上是最强大,也是体验最好的。我们之前暖场的时候放的这些视频也全都是小米Yeelight盒子的例子。当然了,如果大家说我不想花这个钱的话,相对一个简单的方法就是下载一个米家的APP,就是小米在控制它的所有智能设备,有一个中控的APP叫米家,在米家里它的首页有一个麦克风,它的麦克风可以支持小冰或者小爱,你到设置里把它的麦克风从小爱改成小冰,再回到主业去点这个麦克的时候,它就会进入到一个微软小冰全双工的电话界面。在这个里面,就算你家里没有真实的小米出的设备也没关系,因为除了能控制设备以外,事实上你可以去跟它聊天,你可以让它唱歌讲笑话。这个应该是零成本的最方便的体验全双工对话的方法。
13.如何保证高效的传输效率?
是这样的,在小冰绝大多数的实现中,我们使用的是RTP的数据压缩,RTP的数据压缩事实上是几乎所有的IP电话使用的一个标准,它最开始应该是Skype做出来并提倡的,所以大多数业界的IP电话其实都在使用这样的协议。所以如果说智能音箱想要去实现全双工的话,其实也有大量的开源的东西去实现了这样的协议,所以它的开发成本其实是挺低的。
好的,今天的主要问题就到这里,谢谢大家。
(本文为AI科技大本营整理文章,转载请微信联系 1092722531)

推荐阅读:
Playboy封面女郎、互联网第一夫人,程序员们的“钢铁审美”
2019全球AI 100强,中国占独角兽半壁江山,但忧患暗存
“百练”成钢:NumPy 100练
这4门AI网课极具人气,逆天好评!(附代码+答疑)

点击“阅读原文”,打开CSDN APP 阅读更贴心!





