什么时候值得去使用上下文嵌入?

作者:Viktor Karlsson
编译:ronghuaiyang
使用来自BERT的上下文嵌入是很昂贵的,而且并不是所有的情况下都能带来价值,我们来看看在什么情况下是值得使用的。
使用最先进的模型,如BERT,或它的任何后代,不适合资源有限或预算受限的研究者或实践者。仅仅是一个预训练的BERT-base,一个在当前的标准下几乎可以被认为是“小”的模型,在16个TPU芯片上花了超过4天进行训练,这将花费数千美元。这还甚至没有考虑进一步的微调或模型的最终服务,这两者都会增加总成本。
我之前的文章都是试图找出创建更小的Transformer模型的方法,现在,我会后退一步,问:什么时候来自Transformer模型的上下文嵌入是值得使用的?在什么情况下,用更少的计算开销,非上下文嵌入像GloVe或甚至随机嵌入,可以达到类似的性能?是否有数据集的特征可以表明何时会出现这种情况?
这些是Arora等人在Contextual Embeddings: When Are They Worth It?中回答的一些问题。这篇文章将给出他们研究的概述,并重点介绍他们的主要发现。
研究
本研究分为两部分,首先检验训练数据量的效果,然后检验这些数据集的语言特征。
训练数据容量
研究发现,训练数据量在确定GloVe和随机嵌入的相对性能方面起着关键作用。使用更多的训练数据,非上下文嵌入可以快速改进,并且在使用所有可用数据时,表现通常能够达到BERT的5% - 10%的范围内。
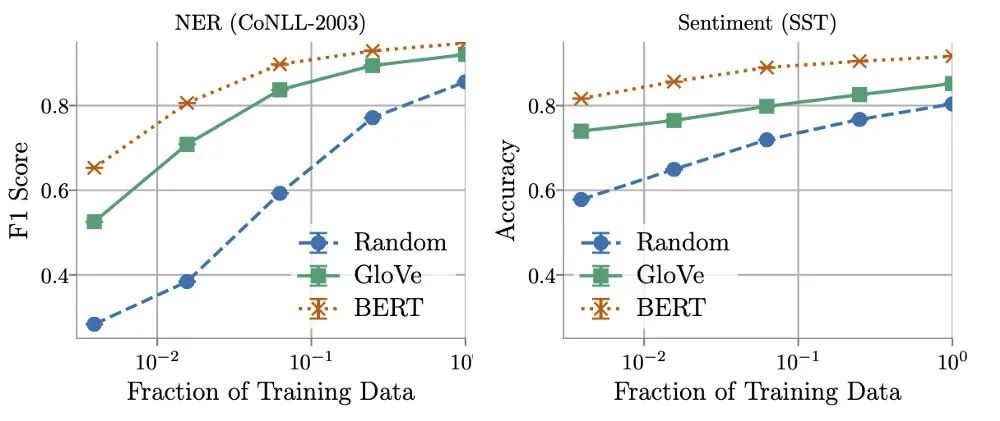
另一方面,作者发现在某些情况下可以用16倍更少的数据训练上下文化的嵌入,同时仍然匹配非上下文化的嵌入所获得的最佳性能。这就提出了推理成本(计算和内存)和标注数据成本之间的权衡,或者如Arora等人所言:
ML实践者可能会发现,对于某些现实世界的任务,在使用非上下文嵌入时,在效率上的巨大收获值得为更多数据添加标签。
数据集的语言特性
训练数据量的研究表明,在某些任务中,上下文嵌入的表现明显优于非上下文化的嵌入,而在其他情况下,这种差异要小得多。这些结果促使作者们思考,是否有可能找到并量化语言特性,以表明什么时候会出现这种情况。
为此,他们定义了三个度量标准,用于量化每个数据集和其中的特征。根据设计,这些度量标准没有给出一个单一的定义,而是用于编码哪些特征影响模型性能的直觉。这使得它们能够被解释,并随后被严格定义,用于我们所研究的任务。因此,在下面的列表中,我将分享作者提出的指标以及在命名实体识别数据集上的示例定义:
-
文本结构的复杂性。每个实体跨越的tokens数量表明了复杂性。“George Washington” 具有两个tokens。 -
单词用法的歧义性。在训练数据集中,每个token分配不同的标签的数量。“Washington”可以被指定为人员、地点和组织,这需要考虑其上下文。 -
没有见过的词的流行度。token出现的次数的倒数。如果前面的句子是我们的数据集,单词“of”将被赋值1/2 = 0.5。
这些指标被用来给数据集中的每个评估指标打分,从而允许我们将它们分割成“困难”和“容易”的子集。这使得作者可以比较来自同一数据集的这两个子集的嵌入性能。
总结
在Contextual Embeddings: When Are They Worth It?中,Arora等人强调了数据集的关键特征,这些特征表明上下文嵌入何时值得使用。首先,训练数据集容量决定了非上下文化嵌入的潜在有用性,越多越好。其次,数据集的特征也起着重要的作用。作者定义le 三个度量标准,文本结构的复杂性,单词用法的歧义性,和没见过单词的流行度,这有助于我们理解使用上下文嵌入可能带来的潜在好处。

英文原文:https://medium.com/dair-ai/when-are-contextual-embeddings-worth-using-b509008cc325
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


