综述:目标检测二十年
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
导读
以2014年为分水岭,作者将过去二十年的目标检测发展进程分为两个阶段:2014年之前的传统目标检测,以及之后基于深度学习的目标检测。接下来,文章列举了二十年来目标检测领域的关键技术,思路非常清晰。
注:文末附39页的目标检测最全综述下载
本文主要参考自文献[1]:Zhengxia Zou, Zhenwei Shi, Member, IEEE, Yuhong Guo, and Jieping Ye, Object Detection in 20 Years: A Survey Senior Member, IEEE
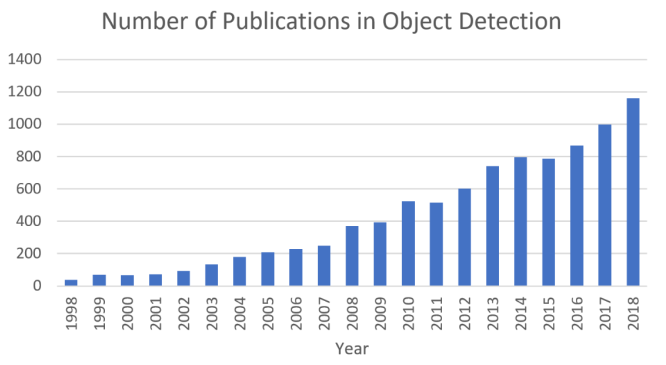
过去二十年中与 “ 目标检测 ” 相关的出版物数量的增长
二十年
在计算机视觉领域中有几个基本的任务:图像分类[3]、目标检测[4]、实例分割[5]及语义分割[6],其中目标检测作为计算机视觉中最基本的任务在近年来引起了广泛关注。某种意义上,它在过去二十年内的发展也是计算机视觉发展史的缩影。如果我们将今天基于深度学习的目标检测技术比作一场“热兵器革命”,那么回顾20年前的技术时即可窥探“冷兵器”时代的智慧。
目标检测是一项计算机视觉任务。正如视觉对于人的作用一样,目标检测旨在解决计算机视觉应用中两个最基本的问题:1. 该物体是什么?2. 该物体在哪里?当然,聪明的人可能会立即想到第三个问题:“该物体在干什么?”这即是更进一步的逻辑及认知推理,这一点在近年来的目标检测技术中也越来越被重视。不管怎样,作为计算机视觉的基本任务,它也是其他计算机视觉任务的主要成分,如实例分割、图像字幕、目标跟踪等。
从应用的角度来看,目标检测可以被分为两个研究主题:“ 通用目标检测(General Object Detection) ” 及 “检测应用(Detection Applications)” ,前者旨在探索在统一的框架下检测不同类型物体的方法,以模拟人类的视觉和认知;后者是指特定应用场景下的检测,如行人检测、人脸检测、文本检测等。
近年来,随着深度学习技术[7]的快速发展,为目标检测注入了新鲜血液,取得了显著的突破,也将其推向了一个前所未有的研究热点。目前,目标检测已广泛应用于自动驾驶、机器人视觉、视频监控等领域。
二十年间的发展
如下图所示,以2014年为分水岭,目标检测在过去的二十年中可大致分为两个时期:2014年前的“传统目标检测期”及之后的“基于深度学习的目标检测期”。接下来我们详细谈论两个时期的发展。
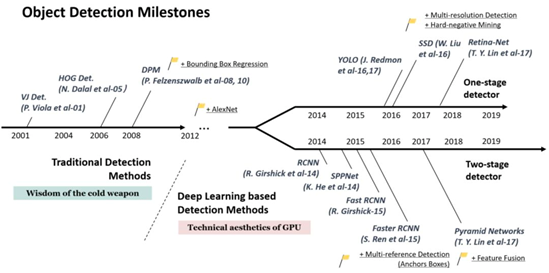
1、传统检测
早期的目标检测算法大多是基于手工特征构建的。由于当时缺乏有效的图像表示,人们别无选择,只能设计复杂的特征表示及各种加速技术对有限的计算资源物尽其用。
(1) Viola Jones检测器
18年前,P. Viola和M. Jones在没有任何约束(如肤色分割)的情况下首次实现了人脸的实时检测[8][9]。他们所设计的检测器在一台配备700MHz Pentium III CPU的电脑上运行,在保持同等检测精度的条件下的运算速度是其他算法的数十甚至数百倍。这种检测算法以共同作者的名字命名为“Viola-Jones (VJ) 检测器”以纪念他们的重大贡献。
VJ检测器采用最直接的检测方法,即滑动窗口(slide window):查看一张图像中所有可能的窗口尺寸和位置并判断是否有窗口包含人脸。这一过程虽然听上去简单,但它背后所需的计算量远远超出了当时计算机的算力。VJ检测器结合了 “ 积分图像 ”、“ 特征选择 ” 和 “ 检测级联 ” 三种重要技术,大大提高了检测速度。
1)积分图像:这是一种计算方法,以加快盒滤波或卷积过程。与当时的其他目标检测算法一样[10],在VJ检测器中使用Haar小波作为图像的特征表示。积分图像使得VJ检测器中每个窗口的计算复杂度与其窗口大小无关。
2)特征选择:作者没有使用一组手动选择的Haar基过滤器,而是使用Adaboost算法从一组巨大的随机特征池 (大约18万维) 中选择一组对人脸检测最有帮助的小特征。
3)检测级联:在VJ检测器中引入了一个多级检测范例 ( 又称“检测级联”,detection cascades ),通过减少对背景窗口的计算,而增加对人脸目标的计算,从而减少了计算开销。
(2) HOG 检测器
方向梯度直方图(HOG)特征描述器最初是由N. Dalal和B.Triggs在2005年提出的[11]。HOG对当时的尺度不变特征变换(scale-invariant feature transform)和形状语境(shape contexts)做出重要改进。为了平衡特征不变性 ( 包括平移、尺度、光照等 ) 和非线性 ( 区分不同对象类别 ),HOG描述器被设计为在密集的均匀间隔单元网格(称为一个“区块”)上计算,并使用重叠局部对比度归一化方法来提高精度。虽然HOG可以用来检测各种对象类,但它的主要目标是行人检测问题。如若要检测不同大小的对象,则要让HOG检测器在保持检测窗口大小不变的情况下,对输入图像进行多次重设尺寸(rescale)。这么多年来,HOG检测器一直是许多目标检测器和各种计算机视觉应用的重要基础。
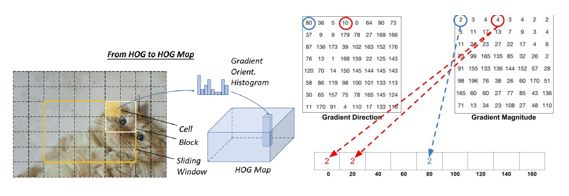
方向梯度直方图(HOG),计算出每个像素朝四周的梯度方向和梯度强度,并统计形成梯度直方图
(3) 基于可变形部件的模型(DPM)
DPM作为voco -07、-08、-09届检测挑战赛的优胜者,它曾是传统目标检测方法的巅峰。DPM最初是由P. Felzenszwalb提出的[12],于2008年作为HOG检测器的扩展,之后R. Girshick进行了各种改进[13][14]。
DPM遵循“分而治之”的检测思想,训练可以简单地看作是学习一种正确的分解对象的方法,推理可以看作是对不同对象部件的检测的集合。例如,检测“汽车”的问题可以看作是检测它的窗口、车身和车轮。工作的这一部分,也就是“star model”由P.Felzenszwalb等人完成。后来,R. Girshick进一步将star model扩展到 “ 混合模型 ”,以处理更显著变化下的现实世界中的物体。
一个典型的DPM检测器由一个根过滤器(root-filter)和一些零件滤波器(part-filters)组成。该方法不需要手动设定零件滤波器的配置(如尺寸和位置),而是在开发了一种弱监督学习方法并使用到了DPM中,所有零件滤波器的配置都可以作为潜在变量自动学习。R. Girshick将这个过程进一步表述为一个多实例学习的特殊案例,同时还应用了“困难负样本挖掘(hard-negative mining)”、“边界框回归”、“语境启动”等重要技术以提高检测精度。而为了加快检测速度,Girshick开发了一种技术,将检测模型“ 编译 ”成一个更快的模型,实现了级联结构,在不牺牲任何精度的情况下实现了超过10倍的加速。
虽然今天的目标探测器在检测精度方面已经远远超过了DPM,但仍然受到DPM的许多有价值的见解的影响,如混合模型、困难负样本挖掘、边界框回归等。2010年,P. Felzenszwalb和R. Girshick被授予PASCAL VOC的 “终身成就奖”。
2、基于卷积神经网络的双级检测器
随着手动选取特征技术的性能趋于饱和,目标检测在2010年之后达到了一个平稳的发展期。2012年,卷积神经网络在世界范围内重新焕发生机[15]。由于深卷积网络能够学习图像的鲁棒性和高层次特征表示,一个自然而然的问题是:我们能否将其应用到目标检测中?R. Girshick等人在2014年率先打破僵局,提出了具有CNN特征的区域(RCNN)用于目标检测[16]。从那时起,目标检测开始以前所未有的速度发展。在深度学习时代,目标检测可以分为两类:“双级检测(two-stage detection)” 和 “单级检测(one-stage detection)”,前者将检测框定为一个“从粗到细 ”的过程,而后者将其定义为“一步到位”。
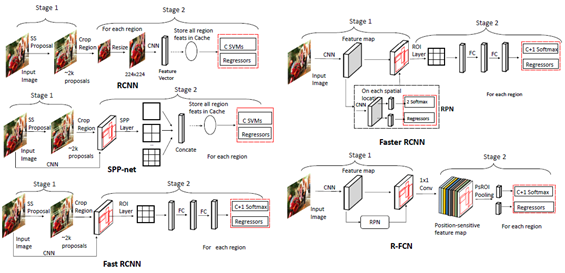
双级检测的发展及各类检测器的结构[2]
(1) RCNN
RCNN[17]的思路很简单:它首先通过选择性搜索来提取一组对象作为“提案(proposal)”并当做对象的候选框。然后将每个提案重新调整成一个固定大小的图像,再输入到一个在ImageNet上训练得到的CNN模型(如AlexNet) 来提取特征。最后,利用线性SVM分类器对每个区域内的目标进行预测,识别目标类别。RCNN在VOC07测试集上有明显的性能提升,平均精准度 (mean Average Precision,mAP) 从33.7%(DPM-v5) 大幅提高到58.5%。
虽然RCNN已经取得了很大的进步,但它的缺点是显而易见的:需要在大量重叠的提案上进行冗余的特征计算 (一张图片超过2000个框),导致检测速度极慢(使用GPU时每张图片耗时14秒)。同年晚些时候,有人提出了SPPNet并克服了这个问题。
(2) SPPNet
2014年,K. He等人提出了空间金字塔池化网络( Spatial Pyramid Pooling Networks,SPPNet)[18]。以前的CNN模型需要固定大小的输入,例如AlexNet需要224x224图像。SPPNet的主要贡献是引入了空间金字塔池化(SPP)层,它使CNN能够生成固定长度的表示,而不需要重新调节有意义图像的尺寸。利用SPPNet进行目标检测时,只对整个图像进行一次特征映射计算,然后生成任意区域的定长表示以训练检测器,避免了卷积特征的重复计算。SPPNet的速度是R-CNN的20多倍,并且没有牺牲任何检测精度(VOC07 mAP=59.2%)。
SPPNet虽然有效地提高了检测速度,但仍然存在一些不足:第一,训练仍然是多阶段的,第二,SPPNet只对其全连接层进行微调,而忽略了之前的所有层。而次年晚些时候出现Fast RCNN并解决了这些问题。
(3) Fast RCNN
2015年,R. Girshick提出了Fast RCNN检测器[19],这是对R-CNN和SPPNet的进一步改进。Fast RCNN使我们能够在相同的网络配置下同时训练检测器和边界框回归器。在VOC07数据集上,Fast RCNN将mAP从58.5%( RCNN)提高到70.0%,检测速度是R-CNN的200多倍。
虽然Fast-RCNN成功地融合了R-CNN和SPPNet的优点,但其检测速度仍然受到提案检测的限制。然后,一个问题自然而然地出现了:“ 我们能用CNN模型生成对象提案吗? ” 之后的Faster R-CNN解决了这个问题。
(4) Faster RCNN
2015年,S. Ren等人提出了Faster RCNN检测器[20],在Fast RCNN之后不久。Faster RCNN 是第一个端到端的,也是第一个接近实时的深度学习检测器(COCO mAP@.5=42.7%,COCO mAP@[.5,.95]=21.9%, VOC07 mAP=73.2%,VOC12 mAP=70.4%)。Faster RCNN的主要贡献是引入了区域提案网络 (RPN)从而允许几乎所有的cost-free的区域提案。从RCNN到Faster RCNN,一个目标检测系统中的大部分独立块,如提案检测、特征提取、边界框回归等,都已经逐渐集成到一个统一的端到端学习框架中。
虽然Faster RCNN突破了Fast RCNN的速度瓶颈,但是在后续的检测阶段仍然存在计算冗余。后来提出了多种改进方案,包括RFCN和 Light head RCNN。
(5) Feature Pyramid Networks(FPN)
2017年,T.-Y.Lin等人基于Faster RCNN提出了特征金字塔网络(FPN)[21]。在FPN之前,大多数基于深度学习的检测器只在网络的顶层进行检测。虽然CNN较深层的特征有利于分类识别,但不利于对象的定位。为此,开发了具有横向连接的自顶向下体系结构,用于在所有级别构建高级语义。由于CNN通过它的正向传播,自然形成了一个特征金字塔,FPN在检测各种尺度的目标方面显示出了巨大的进步。在基础的Faster RCNN系统中使用FPN骨架可在无任何修饰的条件下在MS-COCO数据集上以单模型实现state-of-the-art 的效果(COCO mAP@.5=59.1%,COCO mAP@[.5,.95]= 36.2%)。FPN现在已经成为许多最新探测器的基本组成部分。
3、基于卷积神经网络的单级检测器
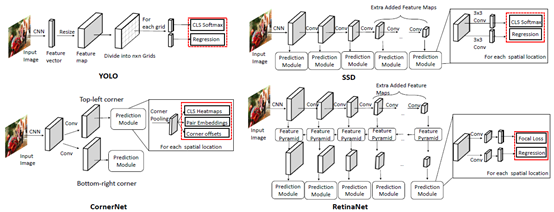
单阶段检测的发展及各类检测器的结构[2]
(1) You Only Look Once (YOLO)
YOLO由R. Joseph等人于2015年提出[22]。它是深度学习时代的第一个单级检测器。YOLO非常快:YOLO的一个快速版本运行速度为155fps, VOC07 mAP=52.7%,而它的增强版本运行速度为45fps, VOC07 mAP=63.4%, VOC12 mAP=57.9%。YOLO是“ You Only Look Once ” 的缩写。从它的名字可以看出,作者完全抛弃了之前的“提案检测+验证”的检测范式。相反,它遵循一个完全不同的设计思路:将单个神经网络应用于整个图像。该网络将图像分割成多个区域,同时预测每个区域的边界框和概率。后来R. Joseph在 YOLO 的基础上进行了一系列改进,其中包括以路径聚合网络(Path aggregation Network, PAN)取代FPN,定义新的损失函数等,陆续提出了其 v2、v3及v4版本(截止本文的2020年7月,Ultralytics发布了“YOLO v5”,但并没有得到官方承认),在保持高检测速度的同时进一步提高了检测精度。
必须指出的是,尽管与双级探测器相比YOLO的探测速度有了很大的提高,但它的定位精度有所下降,特别是对于一些小目标而言。YOLO的后续版本及在它之后提出的SSD更关注这个问题。
(2) Single Shot MultiBox Detector (SSD)
SSD由W. Liu等人于2015年提出[23]。这是深度学习时代的第二款单级探测器。SSD的主要贡献是引入了多参考和多分辨率检测技术,这大大提高了单级检测器的检测精度,特别是对于一些小目标。SSD在检测速度和准确度上都有优势(VOC07 mAP=76.8%,VOC12 mAP=74.9%, COCO mAP@.5=46.5%,mAP@[.5,.95]=26.8%,快速版本运行速度为59fps) 。SSD与其他的检测器的主要区别在于,前者在网络的不同层检测不同尺度的对象,而后者仅在其顶层运行检测。
(3) RetinaNet
单级检测器有速度快、结构简单的优点,但在精度上多年来一直落后于双级检测器。T.-Y.Lin等人发现了背后的原因,并在2017年提出了RetinaNet[24]。他们的观点为精度不高的原因是在密集探测器训练过程中极端的前景-背景阶层不平衡(the extreme foreground-background class imbalance)现象。为此,他们在RetinaNet中引入了一个新的损失函数 “ 焦点损失(focal loss)”,通过对标准交叉熵损失的重构,使检测器在训练过程中更加关注难分类的样本。焦损耗使得单级检测器在保持很高的检测速度的同时,可以达到与双级检测器相当的精度。(COCO mAP@.5=59.1%,mAP@[.5, .95]=39.1% )。
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓





