
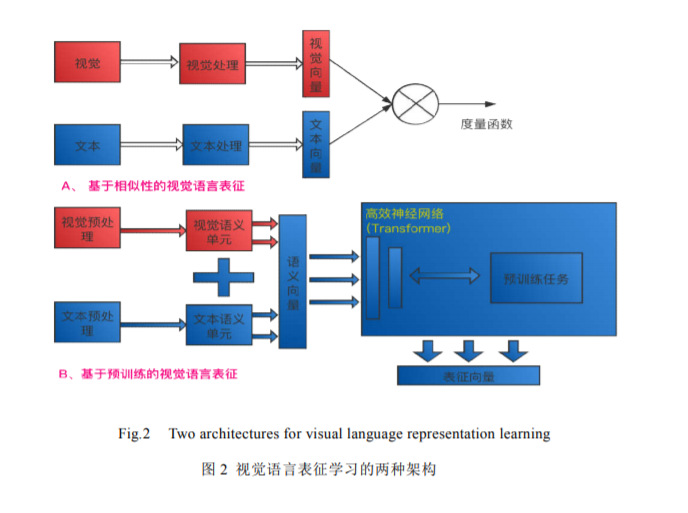
我们生活在一个由大量不同模态内容构建而成的多媒体世界中,不同模态信息之间具有高度的相关性和互补性,多模态表征学习的主要目的就是挖掘出不同模态之间的共性和特性,产生出可以表示多模态信息的隐含向量.该文章主要介绍了目前应用较广的视觉语言表征的相应研究工作,包括传统的基于相似性模型的研究方法和目前主流的基于语言模型的预训练的方法.目前比较好的思路和解决方案是将视觉特征语义化然后与文本特征通过一个强大的特征抽取器产生出表征,其中Transformer[1]作为主要的特征抽取器被应用表征学习的各类任务中.文章分别从研究背景、不同研究方法的划分、测评方法、未来发展趋势等几个不同角度进行阐述.
http://www.jos.org.cn/jos/ch/reader/view_abstract.aspx?file_no=6125&flag=1
成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2017年8月17日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2017年8月17日