论文浅尝 | 基于多模态关联数据嵌入的知识库补全

链接:https://arxiv.org/pdf/1809.01341.pdf
动机(摘要)
当前的知识库补全的方法主要是将实体和关系嵌入到一个低维的向量空间,但是却只利用了知识库中的三元组结构 (<s,r,o>) 数据,而忽略了知识库中大量存在的文本,图片和数值信息。本文将三元组以及多模态数据一起嵌入到向量空间,不仅能够使链接预测更加准确,而且还能产生知识库中实体缺失的多模态数据。
亮点
通过不同的 encoders,将多模态数据嵌入成低维向量做链接预测
通过不同的 decoders,能够产生实体缺失的多模态数据
模型
1 多模态数据的嵌入:
(1) 结构化数据:对于知识库中的实体,将他们的one-hot编码通过一个denselayer得到它们的embedding
(2) 文本:对于那些很短的文本,比如名字和标题,利用双向的GRUs编码字符;对于那些相对长的文本,通过CNN在词向量上卷积和池化得到最终编码。
(3) 图片:利用在ImageNet上预训练好的VGG网络,得到图片的embedding
(4) 数值信息:全连接网络,即通过一个从的映射,获得数值的embedding
(5) 训练:目标函数(cross-entropy):
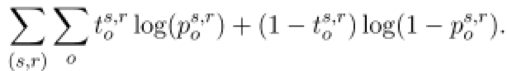
其中:t^(s,r) 是一个one-hot向量。如果知识库中存在 <s, r, o> 这个三元组,t_o^(s,r) 值为1,否则 t_o^(s,r) 值为0。
p_o^(s,r)是 <s, r, o> 模型预测出来的这个三元组成立的概率,它的值介于0到1之间。
2 解码多模态数据:
(1) 数值和类别信息:利用一个全连接网络,输入是已经训练好的向量,输出是数值和类别,损失函数是RMSE(数值)或者cross-entropy(类别)
(2) 文本:利用ARAE模型,输入是训练好的连续向量,输出是文本
(3) 图片:利用GAN模型来产生图片
实验
本文作者在 MovieLens-100k 和 YAGO-10 两个数据集上面引入了多模态数据,其中 MovieLens-100k 引入了用户信息文本,电影信息文本,电影海报;YAGO-10 也为实体引进了图片,文本,数值等信息。
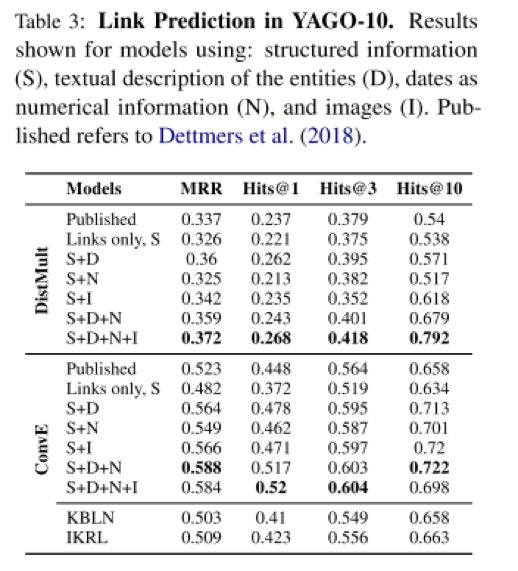
1 链接预测:可以看到在引入了实体文本描述,图片和数值之后,利用之前的嵌入模型,达到了SOTA的效果
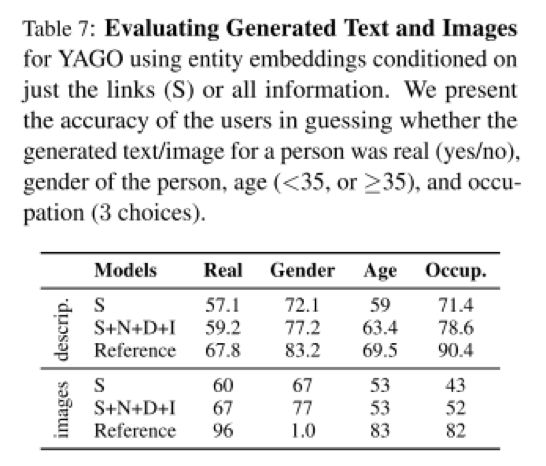
2 生成多模态数据:可以看到,引入了多模态数据之后,产生出来的文本和图片的质量比起仅仅依靠知识库原本就存在的三元组信息产生的文本和图片的质量要高。
总结
本文的创新点是引入了多模态数据来做知识库中的链接预测和生成实体缺失的多模态数据。但是不足之处在于不知道到底引入的哪一部分多模态数据对最终的链接预测产生提升,以及产生的多模态数据质量不是很理想。这有待于后续工作的改进。
论文笔记整理:康矫健,浙江大学硕士,研究方向为知识图谱、自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。




