一会儿「梦露」,一会儿「门罗」,如何帮机器翻译改掉这类低级错误?
大家都听过大名鼎鼎的图灵测试。近年来取得巨大进步的机器翻译在众多场景下都取得了媲美人类的成绩[1],许多人惊呼,机器翻译能成功「骗」过人类了。但如果深入研究,就能发现机器翻译在一些特殊的场景下,仍然有些肉眼可见的瑕疵。篇章级翻译就是一个典型的场景。
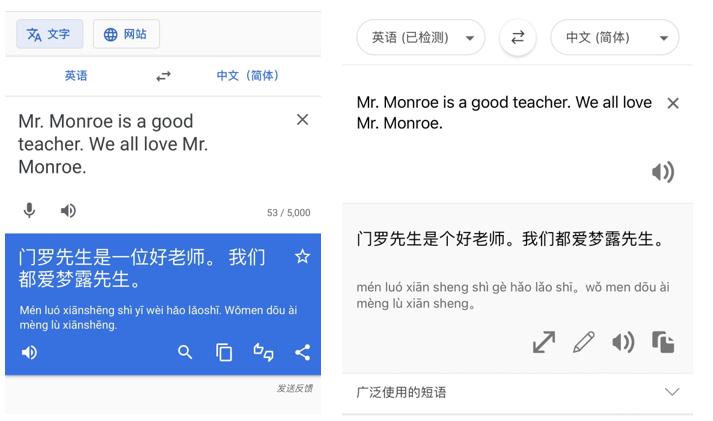
人类在翻译的过程中会保持上下文一致,比如翻译英文名「Monroe」,不会一会儿翻译成「梦露」,一会儿翻译成「门罗」,但许多商用机器翻译仍然会犯这种「低级错误」。
![]()
如何在篇章翻译的过程中保持上下文的一致性,让机器表现得更像人类,是机器翻译的一个重要课题。今天就为大家介绍一篇由字节跳动 AI-Lab 火山翻译团队、南京大学与加州圣塔芭芭拉分校共同发表在 ACL 2022 的长文 —— Rethinking Document-level Neural Machine Translation。
这篇论文重新审视了篇章机器翻译领域的过往工作,针对当下流行的研究趋势进行了反思,并提出回归到经典简洁的 Transformer 模型解决篇章翻译问题,通过多分解度的训练方案取得了 SOTA 的效果。最后,这篇文章也贡献了一份新的数据集,旨在推动整个领域的发展。
![]()
论文地址:https://arxiv.org/abs/2010.08961
代码地址:https://github.com/sunzewei2715/Doc2Doc_NMT
在机器翻译的任务中,段落、文档等连续片段的翻译是非常重要的场景,诸如新闻翻译、小说翻译、电影字幕翻译等等。我们将其统称为篇章级别的机器翻译(Document-level Machine Translation)。其最重要的特征是翻译的结果需要考虑到上下文的信息,保持行文的一致性与前后呼应。
而当前的机器翻译模型主要以句子作为翻译的基本单位,逐句逐句地进行翻译。这类方法的问题显而易见:无法有效捕捉到上下文的信息,在翻译的过程中容易出现与上下文不一致、引用错误等问题,如下面这个例子:
![]()
可见,将神经机器翻译针对篇章级别的翻译 (Document-level Neural Machine Translation, 下称 DNMT) 进行针对性的改进是一项重要任务。
以往有许多工作对 DNMT 做出了改进,但也遭受了部分质疑[2,3,4]。研究者也发现,以往工作取得的提升在某种程度上仅仅归功于在小数据集上的过拟合。
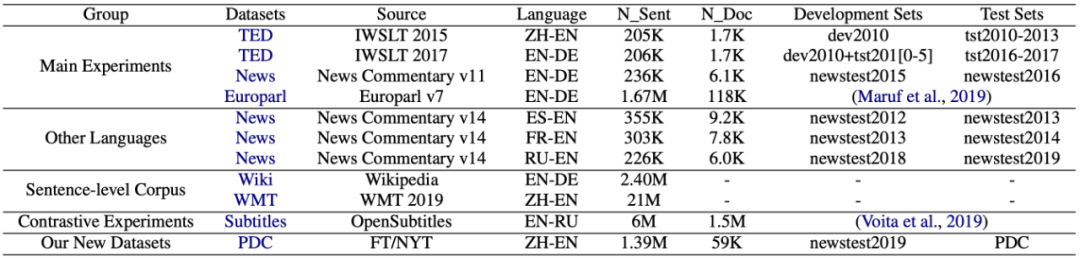
篇章翻译最常用的数据集是 News Commentary 与 TED Talks。这两份数据集仅包含大概 20 万句对,不到 1 万篇文档,而且测试集与训练集分布高度类似,有很高的过拟合的嫌疑。甚至有些工作 [5,6,7] 对句级别模型设定 dropout=0.1,篇章级别模型设定 dropout=0.2,并在此基础上宣称取得了提升。而其中可能潜在的正则化与过拟合的问题未被真正探讨过。
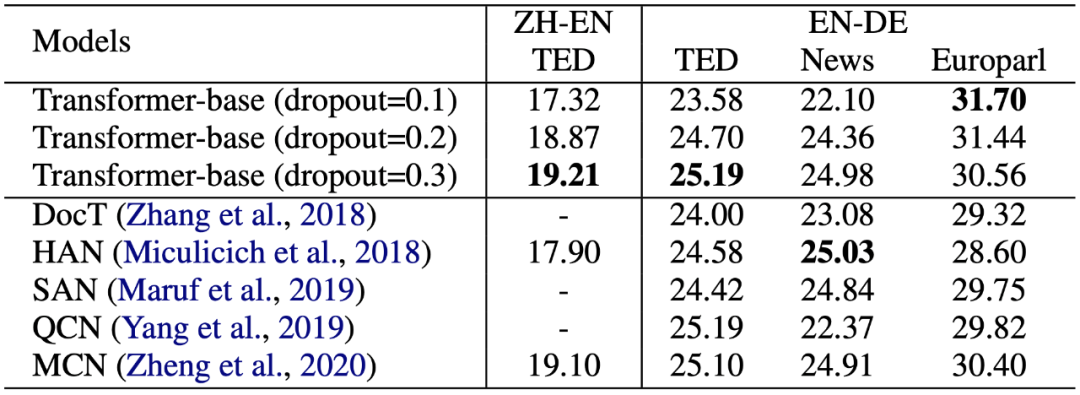
为了验证猜想,研究者仅调整超参数(dropout),在句级别模型上做了若干组实验,如表 1 所示:
![]()
令人震惊的是,研究者发现,简单地增大 dropout 就能几乎填平所有以往工作带来的提升。如在 TED 数据集上,仅是 dropout=0.2 就能让以往工作的提升失去显著性,dropout=0.3 更是超过了所有以往的工作。
这个初步的实验证实,以往的工作缺乏跟坚实 baseline 的对比,单纯增加模型参数(如额外的 encoder)带来的提升很有可能来自小数据集上的过拟合。其他工作也提出了类似的质疑[2,3,4]。
因此,研究者认为,当前以增加额外模型参数或单元的 DNMT 研究趋势需要被重新审视。与之对应的,他们重新回到最原始而简洁的 Transformer 框架,用端到端的训练方式研究篇章翻译。
本节将介绍一种新的篇章级别神经机器翻译的方法:「篇章到篇章」(Doc2Doc)的翻译。
首先,我们需要定义这个任务:令
![]() 表示一个包含M句话的源端篇章,篇章翻译的目标是将
表示一个包含M句话的源端篇章,篇章翻译的目标是将
![]() 从语言
从语言
![]() 翻译到语言
翻译到语言
![]() ,
其中
,
其中
![]() 表示第
表示第
![]() 句话的长度。
句话的长度。
![]()
![]() 是
源端的上下文信息,一般包含两到三句历史的句子,也是大多数工作的重点。
是
源端的上下文信息,一般包含两到三句历史的句子,也是大多数工作的重点。
![]() 是目标端的上下文信息,有部分工作进行了有限的利用,诸如 100 个单词等。
是目标端的上下文信息,有部分工作进行了有限的利用,诸如 100 个单词等。
区别于「篇章到句子」的翻译,字节 AI Lab 的研究者提出了一项新的训练方式——「篇章到篇章」的翻译。将整篇文档作为一个完整的序列送入模型中:
![]()
其中
![]() 是源端的完整序列信息,
是源端的完整序列信息,
![]() 是目标端的历史信息。
第一,「篇章到句子」的翻译并未利用完整的源端信息。严格来说,所谓「篇章到句子」的翻译仅仅是「几句话到句子」。因为大部分工作仅仅利用了前两三句的句子。然而,更多的上下文信息应该能提升翻译质量。
第二,「篇章到句子」的翻译并未利用完整的目标端信息。大部分以往的工作基本没有利用到目标端的历史信息。然而,如果跨句子级别的语言模型没有被利用起来,就会产生诸如时态错位等不一致问题。
第三,「篇章到句子」的翻译限制了训练的场景。过往的工作聚焦于改进模型结构来引入连续的上下文信息。因此,模型的入口只能供连续的句子进入,导致大量碎片化的句子级别的平行语料无法被利用。
第四,「篇章到句子」的翻译不可避免地引入了额外的参数,并使得模型结构变得复杂和难以推广。
与上述对应的,「篇章到篇章」的翻译利用了完整的源端与目标端信息,可以使用任意的平行语料,且不引入任何的额外参数,具有较明显的优势。
虽然篇章到篇章的翻译具有多项优点,这项方式并未得到广泛的使用。有工作甚至报告了负面的实验结果[8,9]。在本文中,研究者将直接的篇章到篇章翻译记为单分解度篇章到篇章翻译(Single-Resolutional Doc2Doc, SR Doc2Doc)。
他们发现,只要借用多分解度篇章到篇章(Multi-resolutional Doc2Doc, MR Doc2Doc)的训练方式,即把篇章同较短的段落、句子一起混合训练,篇章到篇章的翻译能被很好地激活。具体地,他们将篇章多次平均分成k
份,
是目标端的历史信息。
第一,「篇章到句子」的翻译并未利用完整的源端信息。严格来说,所谓「篇章到句子」的翻译仅仅是「几句话到句子」。因为大部分工作仅仅利用了前两三句的句子。然而,更多的上下文信息应该能提升翻译质量。
第二,「篇章到句子」的翻译并未利用完整的目标端信息。大部分以往的工作基本没有利用到目标端的历史信息。然而,如果跨句子级别的语言模型没有被利用起来,就会产生诸如时态错位等不一致问题。
第三,「篇章到句子」的翻译限制了训练的场景。过往的工作聚焦于改进模型结构来引入连续的上下文信息。因此,模型的入口只能供连续的句子进入,导致大量碎片化的句子级别的平行语料无法被利用。
第四,「篇章到句子」的翻译不可避免地引入了额外的参数,并使得模型结构变得复杂和难以推广。
与上述对应的,「篇章到篇章」的翻译利用了完整的源端与目标端信息,可以使用任意的平行语料,且不引入任何的额外参数,具有较明显的优势。
虽然篇章到篇章的翻译具有多项优点,这项方式并未得到广泛的使用。有工作甚至报告了负面的实验结果[8,9]。在本文中,研究者将直接的篇章到篇章翻译记为单分解度篇章到篇章翻译(Single-Resolutional Doc2Doc, SR Doc2Doc)。
他们发现,只要借用多分解度篇章到篇章(Multi-resolutional Doc2Doc, MR Doc2Doc)的训练方式,即把篇章同较短的段落、句子一起混合训练,篇章到篇章的翻译能被很好地激活。具体地,他们将篇章多次平均分成k
份,
![]() 。
举例来说,一篇含有 8 个句子的篇章,我们将其
分解为 2 份 4 句的序列、4 份 2 句的序列、8 份 1 句的序列,并将这 15 个序列
。
举例来说,一篇含有 8 个句子的篇章,我们将其
分解为 2 份 4 句的序列、4 份 2 句的序列、8 份 1 句的序列,并将这 15 个序列
![]() 统一送入模型进行训练。
用这种训练方式,模型能翻译超过 2000 词的长序列(即篇章),而且依旧能对几十个词的短序列(即句子)进行翻译。
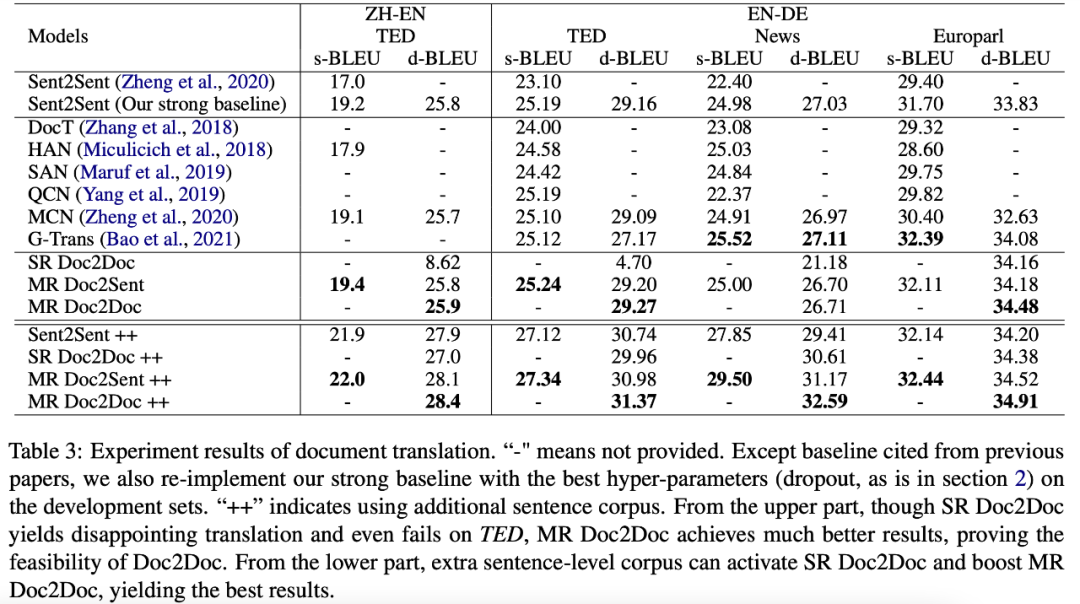
研究者采用与以往工作相同的设置(具体配置可参见原始论文),利用 Transformer Base 模型进行实验,使用数据如表 2 所示:
统一送入模型进行训练。
用这种训练方式,模型能翻译超过 2000 词的长序列(即篇章),而且依旧能对几十个词的短序列(即句子)进行翻译。
研究者采用与以往工作相同的设置(具体配置可参见原始论文),利用 Transformer Base 模型进行实验,使用数据如表 2 所示:
![]()
![]()
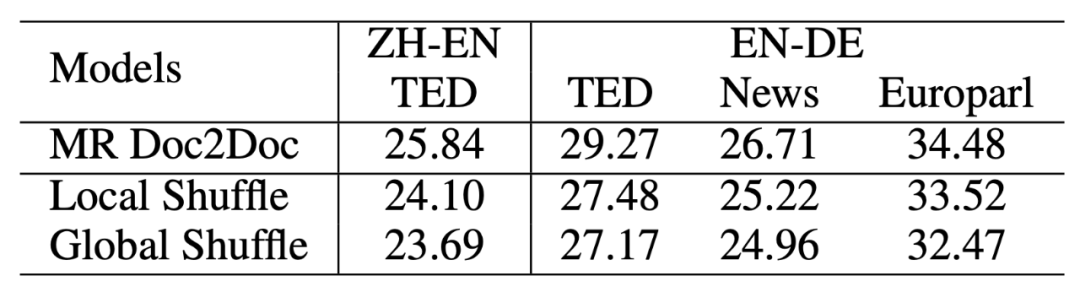
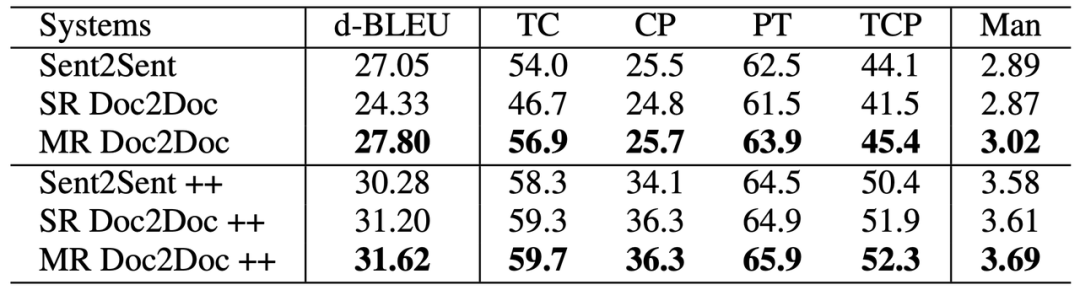
从表 3 的上半部分可以看到,单分解度篇章到篇章 (SR Doc2Doc) 的训练的确降低了翻译质量。但利用多分解度篇章到篇章 (MR Doc2Doc) 的训练,可以得到最好的结果。值得注意的是,这一提升无需增加任何额外的参数。
更进一步,研究者引入了额外的句子级别的平行语料,如表 3 的下半部分所示,一方面,单分解度篇章到篇章的训练被激活并达到了与句子到句子训练相接近的水平。另一方面,多分解度篇章到篇章的训练取得了最好的结果并拉大了与基线的差距。
如上文所分析,句子级别的语料难以被以往的篇章到句子的模型所利用。然而篇章到篇章的训练能非常自然地使用。考虑到句子级别的语料数量远大于篇章级别的语料,多分解度篇章到篇章的训练具有很大的潜力。
除 BLEU 外,研究者也证实了多分解度篇章到篇章的训练也能提升篇章翻译在具体语言学指标中的上下文一致性,如表 4 所示。
![]()
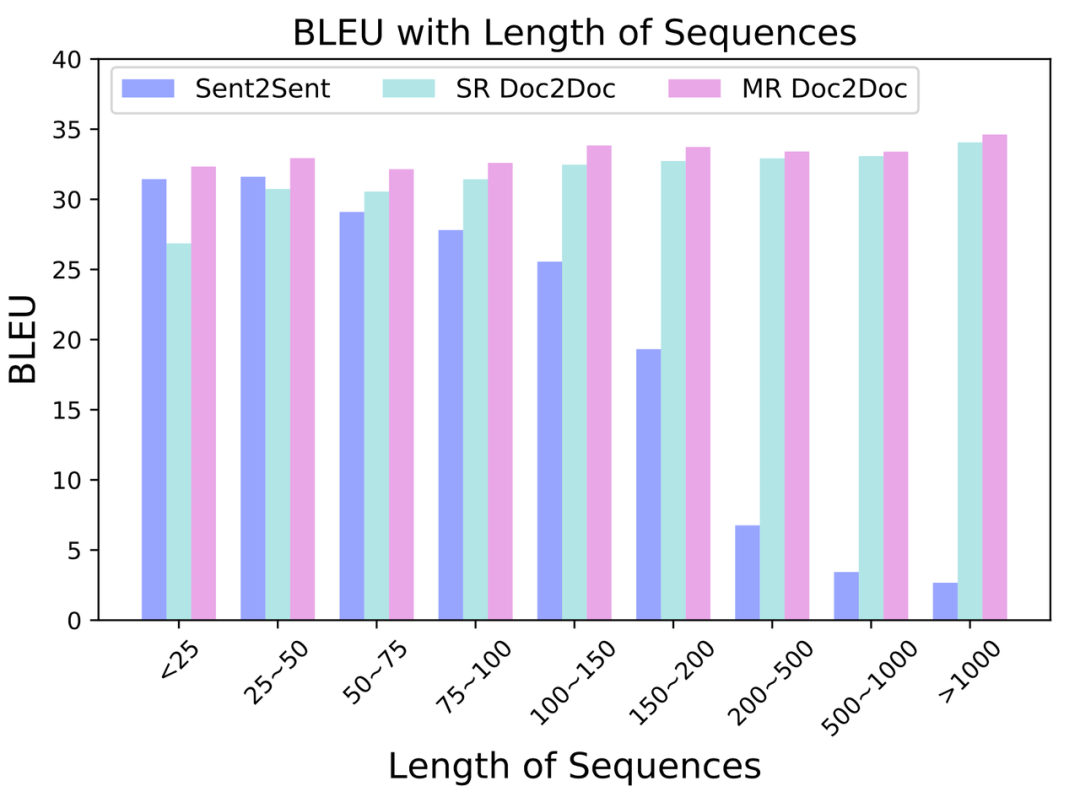
为了测试模型是否有效利用上下文而非忽略上下文,他们还设置了错误的上下文的实验组,发现翻译质量的确下降,如表 5 所示。这项实验证实了上下文信息的重要性。
![]()
表 5:错误的上下文带来翻译质量的下降,说明了上下文的重要性
如图 1 所示,句子到句子的模型擅长短序列的翻译却无法处理长序列的翻译,单分解度篇章到篇章的模型擅长长序列的翻译却做不好短序列的翻译。而多分解度篇章到篇章的翻译能很好地处理任意长度的序列。通过这种训练方式,我们得以用一个模型处理任意长的序列。
![]()
为了更进一步地证实自己的结论,并推动该领域的发展,研究者还贡献了一份新的篇章级别数据集和三项专门设计的篇章翻译评测指标。
他们从互联网上爬取了接近 6 万篇,139 万句的中文 - 英文平行语料,并将之命名为 PDC (Parallel Document Corpus)。
他们制定了三项评测指标:时态一致(Tense Consistency, TC)、连词译出(Conjunction Presence, CP)、代词翻译(Pronoun Translation, PT),具体可参见原始论文。
他们额外从不同于平行语料的出处爬取、利用上述的三项指标筛选了 148 篇文档,并进行了人工翻译。
实验结果如下(++ 表示额外的平行句子级别语料):
![]()
表 6:篇章级翻译在我们新的大规模数据集上提升显著
多分解度篇章到篇章的翻译不仅在 BLEU 上有所提升,在三项细粒度指标上也有明显的提升,也与人工评估有很强的相关性。
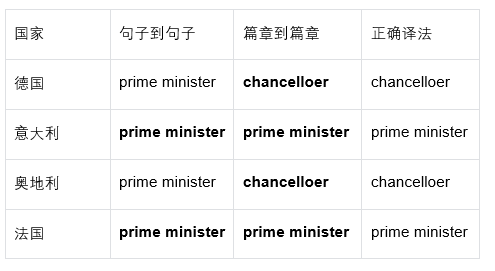
![]()
即便我们更换不同国家的总理,也得到类似的结果:
![]()
在这项工作中,研究者试图回答这样一个问题:用经典而简洁的 Transformer 模型来端到端地处理篇章级机器翻译是否可行?结果表明,虽然单纯的篇章到篇章翻译会失败,但多分解度的端到端训练能将其激活,并且不引入额外的参数。一系列包含多项评测指标的实验充分论证了多分解度篇章到篇章翻译的优势,为这个问题给出了肯定的回答。此外,他们也为这个领域贡献了一份值得参考的数据集。
[1] Hassan, Hany, Anthony Aue, Chang Chen, Vishal Chowdhary, Jonathan Clark, Christian Federmann, Xuedong Huang et al. "Achieving human parity on automatic chinese to english news translation." arXiv preprint arXiv:1803.05567 (2018).
[2] Kim, Yunsu, Duc Thanh Tran, and Hermann Ney. "When and Why is Document-level Context Useful in Neural Machine Translation?." In DiscoMT. 2019.
[3] Jwalapuram, Prathyusha, Barbara Rychalska, Shafiq Joty, and Dominika Basaj. "Can Your Context-Aware MT System Pass the DiP Benchmark Tests?: Evaluation Benchmarks for Discourse Phenomena in Machine Translation." arXiv preprint arXiv:2004.14607 (2020).
[4] Li, Bei, Hui Liu, Ziyang Wang, Yufan Jiang, Tong Xiao, Jingbo Zhu, Tongran Liu, and Changliang Li. "Does Multi-Encoder Help? A Case Study on Context-Aware Neural Machine Translation." In ACL. 2020.
[5] Maruf, Sameen, André FT Martins, and Gholamreza Haffari. "Selective Attention for Context-aware Neural Machine Translation." In NAACL. 2019.
[6] Yang, Zhengxin, Jinchao Zhang, Fandong Meng, Shuhao Gu, Yang Feng, and Jie Zhou. "Enhancing Context Modeling with a Query-Guided Capsule Network for Document-level Translation." In EMNLP-IJCNLP. 2019.
[7] Zheng, Zaixiang, Xiang Yue, Shujian Huang, Jiajun Chen, and Alexandra Birch. "Towards making the most of context in neural machine translation." In IJCAI. 2021.
[8] Zhang, Jiacheng, Huanbo Luan, Maosong Sun, Feifei Zhai, Jingfang Xu, Min Zhang, and Yang Liu. Improving the Transformer Translation Model with Document-Level Context. In EMNLP. 2018.
[9] Liu, Yinhan, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. "Multilingual Denoising Pre-training for Neural Machine Translation." In TACL. 2020.
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


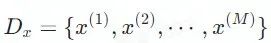 表示一个包含M句话的源端篇章,篇章翻译的目标是将
表示一个包含M句话的源端篇章,篇章翻译的目标是将
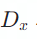 从语言
从语言
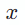 翻译到语言
翻译到语言
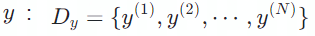 ,
其中
,
其中
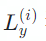 表示第
表示第
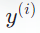 句话的长度。
句话的长度。
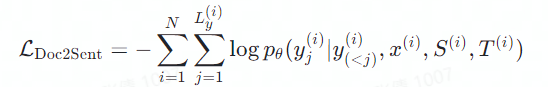
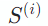 是
源端的上下文信息,一般包含两到三句历史的句子,也是大多数工作的重点。
是
源端的上下文信息,一般包含两到三句历史的句子,也是大多数工作的重点。
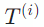 是目标端的上下文信息,有部分工作进行了有限的利用,诸如 100 个单词等。
是目标端的上下文信息,有部分工作进行了有限的利用,诸如 100 个单词等。
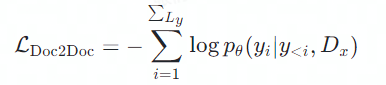
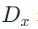 是源端的完整序列信息,
是源端的完整序列信息,
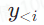 是目标端的历史信息。
是目标端的历史信息。
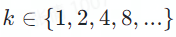 。
举例来说,一篇含有 8 个句子的篇章,我们将其
分解为 2 份 4 句的序列、4 份 2 句的序列、8 份 1 句的序列,并将这 15 个序列
。
举例来说,一篇含有 8 个句子的篇章,我们将其
分解为 2 份 4 句的序列、4 份 2 句的序列、8 份 1 句的序列,并将这 15 个序列
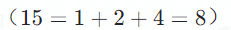 统一送入模型进行训练。
统一送入模型进行训练。