专栏 | 用神经推理来帮助命名实体识别
机器之心专栏
作者:深度好奇研究组(DC-SQUAD)
命名实体识别(Named Entity Recognition)被认为是文本理解的基础和底层任务,因为它的职能就是发现和标识文本中的人名、地名等。传统的 NER 方法依赖局部和底层的语言特征,近年来神经网络结构对局部语言特征的掌握取得令人瞩目的效果,以至于 NER 很多时候被当成「已解决」的任务。但现有的方法与研究往往局限于底层的分析和计算,忽视实体本身对文本理解过程的影响,引入 CRF 进行解码的成功也正是因为如此。
论文题目:Neural Entity Reasoner for Global Consistency in NER
论文地址:https://arxiv.org/abs/1810.00347
当出现有歧义的说法或者少见的人名时,现有方法往往会遇到困难。而人在这种情况下,往往可以通过纵览全文,打通和融合局部的知识,来摆脱这种困境。所以,NER 任务本质是模型对抽取实体进行理解的任务。本文正是受到人的思维模型的启发,为 NER 这个看似低级的任务引入了高级的「推理」机制,将符号化的命名实体信息「取之于网络,用之于网络」,从而可以在深度学习的框架内融合同一文本中的命名实体的决策。
命名实体神经推理机(NE-Reasoner)从实体对象这一更高层次的角度出发,分析实体识别的运算过程,引入可人工设计的推理框架,通过以下三点完成实体的理解和推理:1)在现有方法的基础上,得到对于实体的完整表示;2)引入符号化缓存记忆,对实体信息进行存储;3)通过符号化的操作和推理模型,避免复杂化的处理,以端到端的形式轻松完成训练。
概述
NE-Reasoner 整体上是一个多层的架构,每一层都由三部分组成,编码器对输入文本进行编码以捕捉语义等信息,推理单元通过编码信息和缓存记忆,得到实体间的推理信息,解码器综合这两部分信息得出最后的结果。在编码器与解码器保持不变的情况下,缓存记忆在层之间根据识别出的实体动态的变化,通过推理单元达到逐步推理的效果。
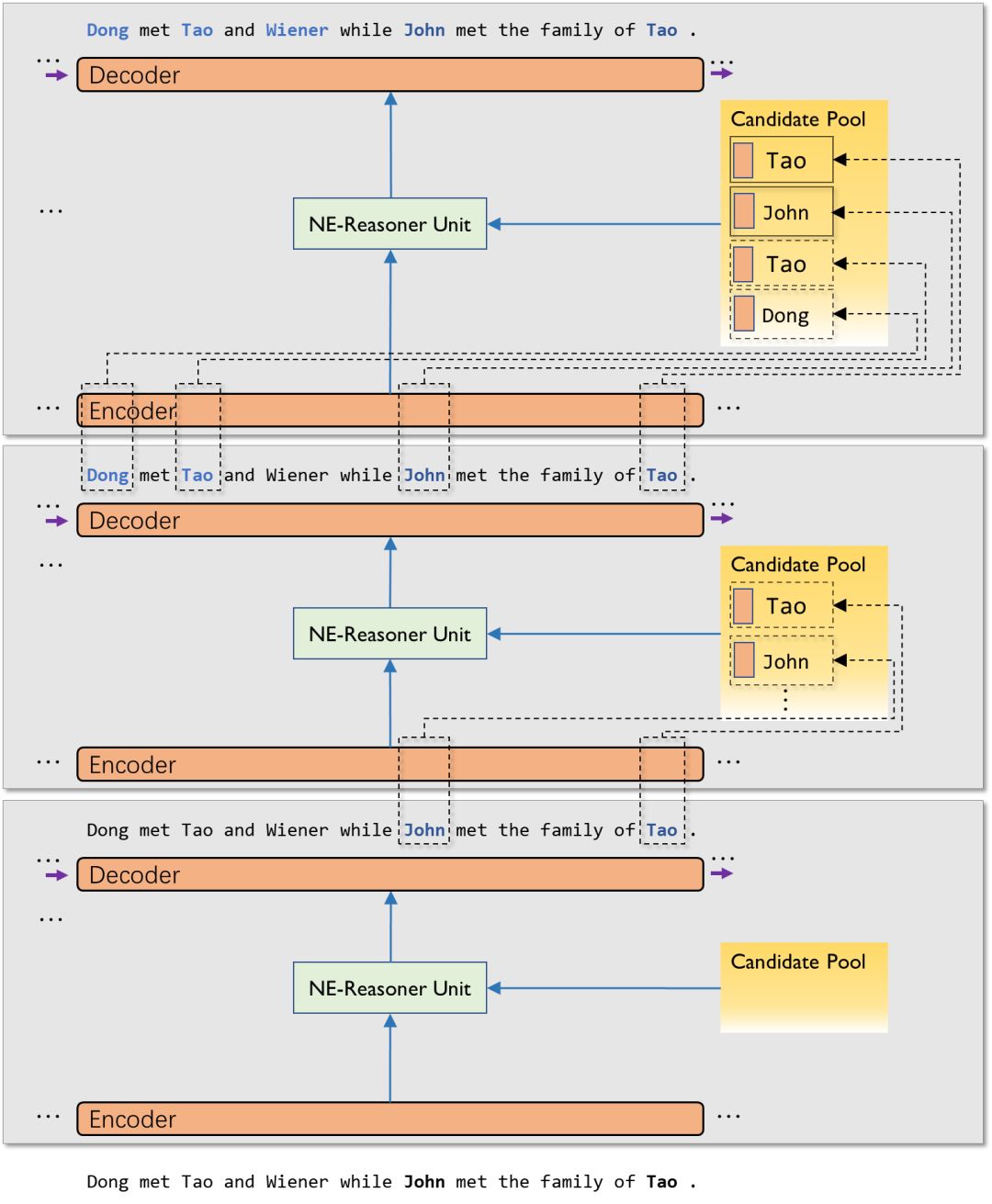
图1 NE-Reasoner整体多层架构
具体来讲,每一层都独立完成一次 NER;每层的 NER 结果,会通过一个符号化的「缓存」存储起来,作为下一层 NER 的参考;这种参考是通过一个交互式的池化神经网络来实现,它其实是一个基于多个事实的推理模型。通过这样的设计,在做每个局部的决策时,模型都可以「看见」目前识别出的所有实体信息并参考别处相关决策,从而做出更加明智的决定。
实体的表示
探究实体的预测过程,首先要清楚实体出现的语言模式。每一个实体的确定,都存在决定性的标识,这种标识来自两方面,一个是字词本身的信息,比如「张某某」这种词汇,没有任何上下文的情况下,会优先将它作为人名处理;另外一方面是前后文的模式,比如「我和 XX 是好朋友」,我们可以推断 XX 处为人名。从这两方面信息,我们可以对实体模式进行如下的解构:
前文信息-实体-后文信息
这样一种结构可以完整地描述一个实体。在神经网络中,现有的方法也是通过这些局部的语言特征进行识别,所以可以轻易地从编码信息中找到实体的表示。
对于本文使用的 Bi-LSTM 编码器,分别从前后两个方向对一个字进行上下文的编码,而解码器通过这些信息得到对于实体的决定性信息。所以,在实体的第一个字,前向的 LSTM 的编码信息一定包含实体的前文信息,最后一个字的后向 LSTM 编码信息一定包含实体的后向信息,而另外两部分都包含完整的实体字符信息。对于每一个实体,我们都可以将它的编码信息做这样的分解,以得到这样四个不同维度对实体的表示:
前文信息-前向实体信息-后向实体信息-后文信息
这也刚好符合前面对实体模式的分析。通过每一层最终的预测结果,可以利用这样的符号化信息定位到实体位置,将每一个实体都从这四个方面进行完整的表示,然后存入缓存记忆中。
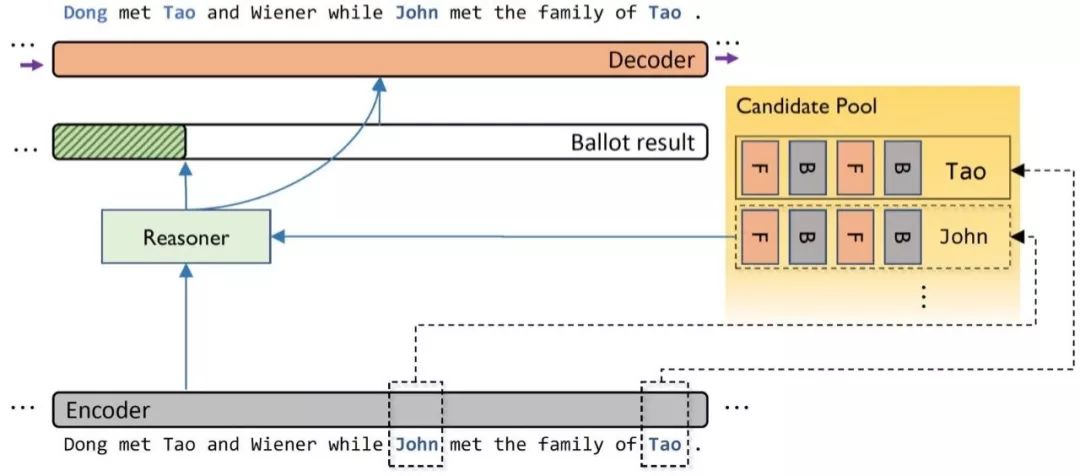
图 2 利用上下文和前后向信息表示实体
推理单元
通过上面的操作,每一层都可以得到上一层识别出的实体的表示,除此之外,层与层之间没有其他必然的联系。将每一层单独来看,我们相当于得到了该文本中都有哪些是实体以及它们为什么是实体这类非常重要的先验知识。
不同于以往方法对记忆模块的使用,这里的缓存记忆实际上是由符号化信息指导产生的堆放实体信息的列表,作为外部信息,不需要进行梯度的传导。由于每个实体也都是独立的,所以缓存记忆在这里可以看作由多个事实组成,而推理单元的作用就是从这些事实中得到全局的推理信息。
解码时,字符的编码信息与每一个实体的表示进行运算以获得与每一个实体的关系,再通过池化操作从中挑选出最具有代表性的关系作为最终的参考。具体到本文的任务来讲,我们通过语义之间的相似性来进行推断,如果存在实体模式与当前所读到的字段相似,那么相似字段在文本中所扮演的角色也应该是相似的,所以可以使用向量距离(如余弦距离)等运算来代表字符编码信息与实体之间的关系,本文使用的是向量内积。
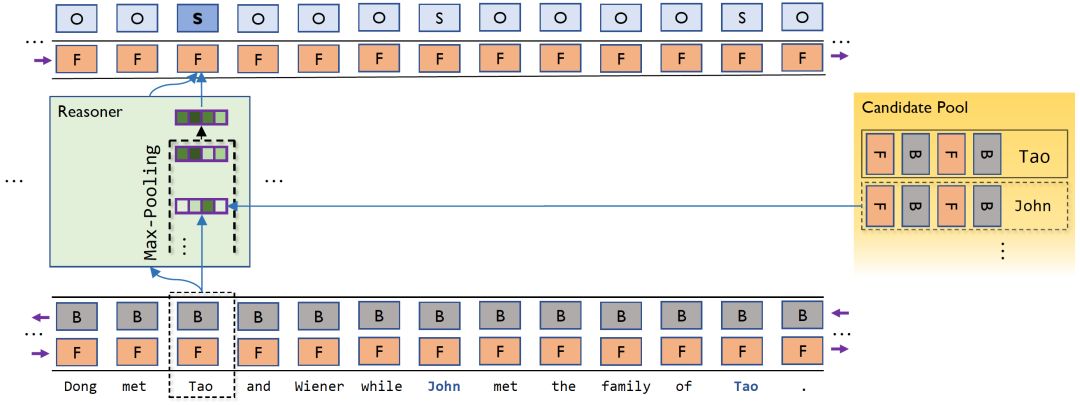
图 3 利用记忆模块进行实体推理
之后,每一个实体的四个维度都可以得到一个运算结果,表示在这四个方面的相似度。在实体的推理中,最重要的是是否存在一个实体信息与当前字段信息很相似,而具体哪一个或者有几个这样的信息是不重要的;所以,在四个维度上进行 max-pooling 可以得到四个值,作为最终的参考信息。将这部分信息与编码信息一起输入到解码器,从而得到这一层的输出。
训练
由于每一层都相对独立且具有单独的输出结果,层与层之间不需要梯度的传导但却通过预测结果进行影响,所以可以有多种训练方式,比如预训练第一层、每一层联合训练或仅利用最后一层输出结果进行训练。本文中所使用的模型的每一层都共享参数,实际上层间的区别只有缓存记忆的实体信息的不同,因此直接对最后一层进行训练就可以在整体上得到好的结果。
实验
本文在英文和中文两个数据集上进行了实验,均取得了明显的提升。由于本方法是一个通用的框架,理论上可以叠加到任意编码-解码形式的网络模型中;并且由于是逐层的输出,可以从不同层之间输出结果的变化看到真实的推理效果,不仅提升了效果,而且符合对推理的预期,有极强的可解释性。
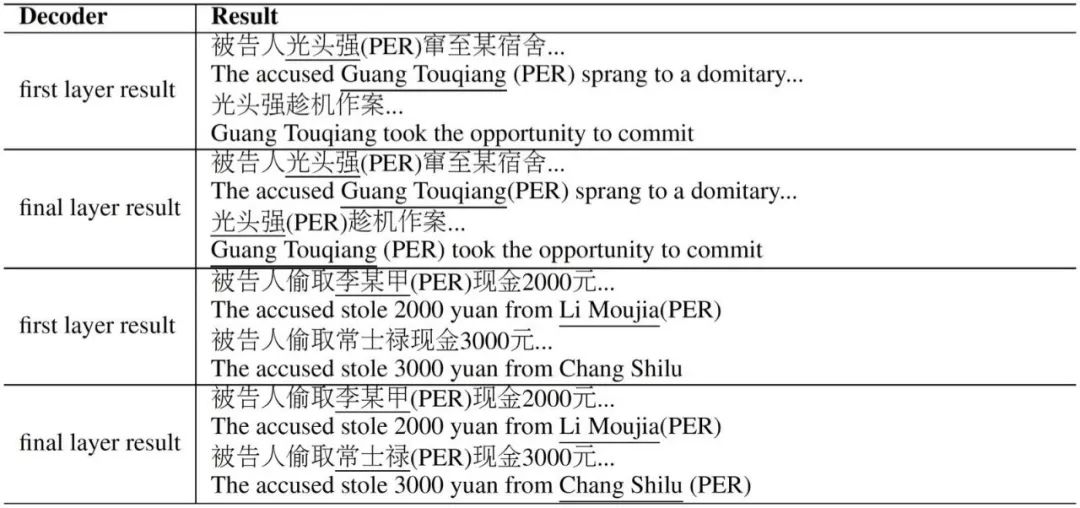
图 4 NE-Reasoner 修正前后典型结果对比
总结
通过在神经网络的推理过程中引入符号化的缓存记忆,以及在缓存基础上的多事实全局推理,可以显著提高命名实体识别的准确率,尤其是在传统方法容易犯错的歧义和少见人名上有更好的表现。命名实体神经推理机作为神经符号推理机在 NER 任务上应用的一个实例,不仅打开了之前神经网络推理决策的黑箱,使得推理过程中的关键步骤对人类可见和可理解,还给予了人工进一步干预推理过程的可能性以及可用的接口。

本文为机器之心专栏,转载请联系原作者获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



