大会 | CVPR 2018论文解读:真实监控场景中的异常事件检测

AI 科技评论按:本文为上海交通大学林天威为 AI 科技评论撰写的独家稿件,未经许可不得转载。
安防作为近年最热门的计算机视觉研究落地方向,与视频分析研究有着很紧密的关系。在真实的监控视频中,一个常见的需求就是要自动识别视频流中的异常事件,也就是异常事件检测任务(Anomaly detection)。
这个任务有许多的难点,比如:
1.异常事件发生的频率很低,导致数据的收集和标注比较困难;
2.异常事件的稀少导致训练中的正样本远少于负样本;
3.在监控场景中,不管是通常(normaly)还是异常(anomaly)事件都是很多样且复杂的,即类别内的多样性很高,variance 很严重。
最近 UCF 的 CV 研究中心就在 CVPR18 上发表了一篇关于监控视频异常事件检测的论文,提出了一种基于深度多实例排序的弱监督算法框架,同时提出了一个新的大规模异常事件检测数据集。这篇笔记主要对这篇文章进行介绍,也算是帮助自己理解,若有错误烦请指正。
很多先前的方法都先学习一个通常的模式,并假定任何违背这个通常模式的 模式应该是异常的。但事实上,一个方法很难也几乎不可能去定义一个所谓的通常模式,因为通常模式里面可能包含太多不同的事件和行为了。同样,也很难去定义异常事件,因为异常事件同样也可能包含太多类型的情况了。所以,这篇文章主要提出了两点 motivations。
1.异常事件检测任务应该要在弱监督框架下进行学习。此处弱监督指在训练时,只知道一段视频中有或没有异常事件,而异常事件的种类以及具体的发生时间是未知的。
2.异常事件检测任务应该采取两阶段的框架,即不管异常事件的种类,生成异常事件的 proposal,之后再对 proposal 中包含的异常事件进行分类。这样有助于提高异常事件检测的召回率(应该是因为这样可以找到一些不在现有类别中的异常)。这样的框架和目标检测中的 RCNN 类方法十分相似。这篇文章则主要针对异常 proposal 阶段进行研究。
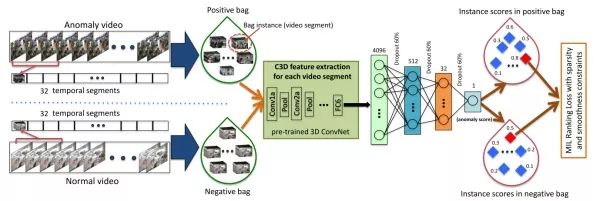
基于这样的想法,该文采用了多示例学习(Multiple instance learning, MIL)方法来构建算法框架,并提出了包含 稀疏和平滑约束的 MIL 排序损失来训练模型。算法框架如下图所示,主要使用 MIL 的思路构建训练集合,使用 C3D+FC 的网络来获取异常评分,最后采用提出的 MIL 排序损失来训练模型。
多示例学习(Multiple Instance Learning)
首先简单的介绍一下多示例学习,这是在 20 世纪 90 年代在机器学习领域中提出的方法。在 MIL 中,「包」被定义为多个示例的集合,其中「正包」中至少包含一个正示例,而「负包」中则只有负示例(此处示例的概念与样本相同,以下不区分)。MIL 的目的是得到一个分类器,使得对于待测试的示例,可以得到其正负标签。可以看出,在异常检测任务中,弱监督实际上就是 MIL 的另外一种表达形式,所以 MIL 的求解算法很适合用于该弱监督任务中。多示例学习的更多介绍可以参考这篇博客:
多示例学习(Multiple Instance Learning)
http://blog.csdn.net/loadstar_kun/article/details/22849247
深度MIL排序模型
接下来介绍该文提出的算法。文中将异常检测定义为一个回归任务,即异常样本(anormal)的异常值要高于通常样本(normal)。直观的考虑可以将排序损失定义为:
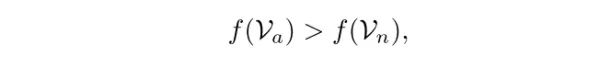
此处 Va 和 Vn 分别为异常和通常样本,f则为模型预测函数。由于在 MIL 中,并不知道正包中每个样本的真实标签,所以采用以下的形式:
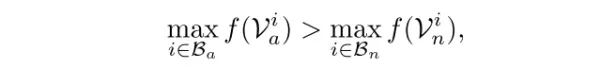
此处即指,在训练中对于正包和负包都只使用分数最大的样本来训练。具体而言,正包中分数最大的样本最可能是正样本,而负包中分数最大的样本则被认为是 hard negative,即难例。基于此式,为了让正负样本之间的距离尽可能远,作者采用了 hinge-loss 的形式。
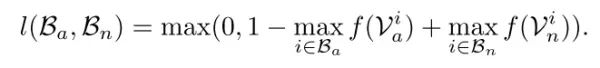
但这样的 loss 并没有考虑视频的时序结构,所以作者提出了两点改进的 motivation:
1.由于视频片段是连续的,所以异常的分数也应该是相对平滑的。
2.由于正包中的正样本(异常事件)比例是很低的,所以正包里面的分数应该是稀疏的。
基于这两点 motivation,作者在 loss function 中添加了两个约束项,分别为时序平滑约束以及稀疏约束。如下所示。
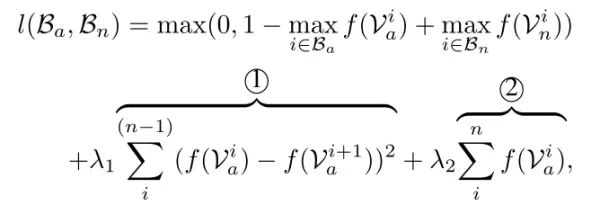
最后,再添加上模型参数的 l2 正则,就得到了最后的损失函数。
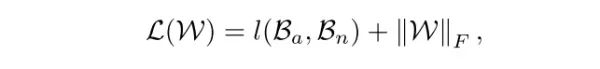
实现细节
在具体实现中,本文采用了在其他数据集上预训练好的 C3D 模型来提取视频片段的特征,此处不对 C3D 模型进行训练。对提取好的特征,再使用 3 层全连接层来获得最后的预测异常值。以上提出的 MIL 排序损失也是用来对这几层 FC 层训练的。
在训练数据处理方面,该文将每个视频均匀分为 32 个片段,作为一个包。训练时,随机选取 30 个正包和 30 个负包作为 mini-batch 进行训练。
本文的另外一个贡献是提出了一个新的较大规模的异常事件检测数据集 UCF-Crime,参考下表,该数据集比起之前的数据集的优点主要是两方面:一是视频的数量和视频的总时长要远远多于之前的数据集,二是其中包含的异常事件类型比较丰富。
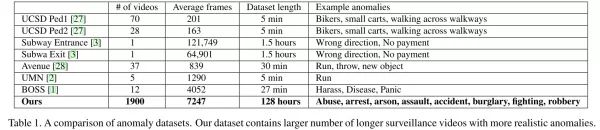
在数据集构成方面,该数据集共包含 13 种异常事件。共有 1900 个视频,其中异常和通常视频各占 950 个。数据集划分方面,训练集包含 1610 个视频(800 个通常视频,810 个异常视频),测试集包含 290 个视频(150 个通常,140 个异常视频)。
数据集网址及该论文项目页见:
Real-world Anomaly Detection in Surveillance Videos
http://crcv.ucf.edu/cchen/
方法比较
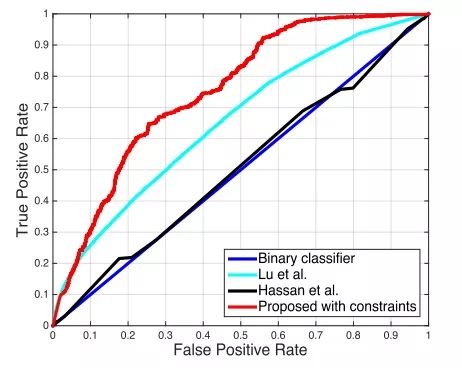
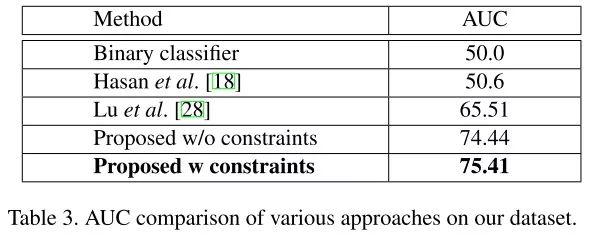
本文主要以 ROC 曲线下的 AUC 来衡量异常检测算法的效果,其实验结果如下图和下表所示。可以看出,其算法比起之前的方法还是有很大的提高的。此外,添加训练中的约束项也带来了一定的效果提升,不过不是很明显。
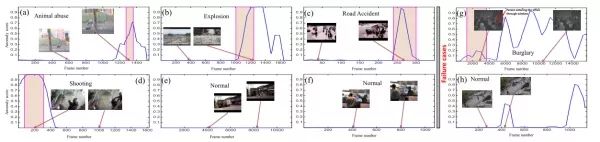
下图则是一些可视化的结果,可以看出在作者挑选的这些例子中,异常检测的效果还是很不错的,最右一列则为一些失败案例。
虚假预警率分析
在监控任务场景中,一个可靠的系统应该具备较高的召回率和较低的误报率,作者比较了0.5阈值下的误报率,也具备不错的效果。

异常事件分类
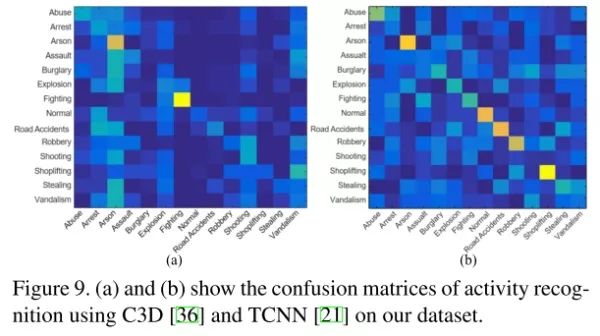
该文的方法只是做异常事件 proposal,但该文的数据集实际上还能做异常时间分类任务,所以此处作者还用 C3D 和 TCNN 两种行为识别算法跑了一个 baseline,可以看出此处 TCNN 的效果还是比 C3D 要好很多。

这篇文章主要针对异常事件检测问题提出了一种新的弱监督算法和一个新的数据集。算法方面,主要就是将这个问题套用进了 MIL 的框架。这个数据集的提出应该对这个方向的发展会有比较大的帮助,此前异常检测一直没有比较大的数据集。
缺点方面,我认为对于异常检测这种数据不平衡任务,用 PRC 曲线会比 ROC 曲线能更好得起到衡量算法效果的作用。即应该用 Average Precision 来衡量异常检测效果。另外文中还着重衡量了虚报率,而在真实场景中对于异常事件的召回率要更重要一些,毕竟漏过几个异常事件比起虚报几个异常事件带来的负面影响更大。
总的来说,异常事件检测作为真实场景中一个非常重要的任务,目前针对性的研究还不是很多。基于这篇文章提出的算法思路和数据集,后面应该也会有更多的工作跟进吧。
对了,我们招人了,了解一下?

NLP工程师入门实践班
三大模块,五大应用,知识点全覆盖;
海外博士讲师,丰富项目分享经验;
理论+实践,带你实战典型行业应用;
专业答疑社群,结交志同道合伙伴。

┏(^0^)┛欢迎分享,明天见!



