商汤及联合实验室入选论文重点解读 | ECCV 2018
允中 发自 凹非寺
量子位 报道 | 公众号 QbitAI

9月8日-14日,备受瞩目的2018欧洲计算机视觉大会(ECCV 2018)在德国慕尼黑召开, ECCV两年举办一次,与CVPR、ICCV共称为计算机视觉领域三大顶级学术会议,每年录用论文约300篇。
今年商汤科技及联合实验室共有37篇论文入选,超过微软、谷歌、Facebook等科技巨头。而录取论文在以下领域实现突破:大规模人脸与人体识别、物体检测与跟踪、自动驾驶场景理解与分析、视频分析、3D视觉、底层视觉算法、视觉与自然语言的综合理解等。
对于这些论文,商汤及联合实验室精选了其中重点论文解读:
大规模人脸与人体识别
代表性论文:人脸识别的瓶颈在于数据集噪声(The Devil of Face Recognition is in the Noise)
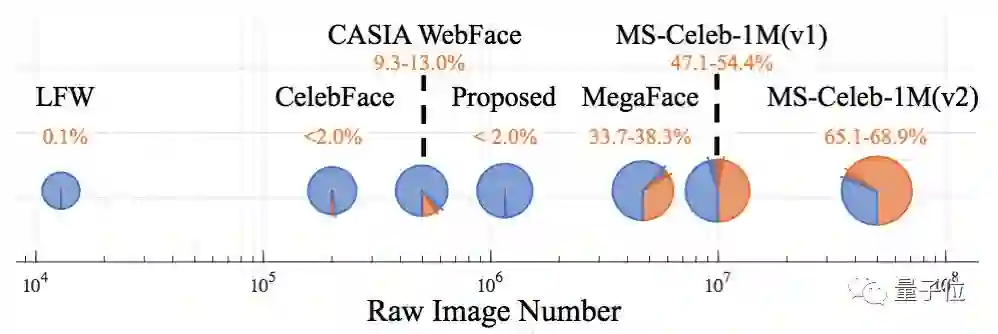
随着人脸数据集规模的逐渐扩大,研究者们设计出了各种更快更强的人脸识别网络。但是对于现有人脸数据集中的标签噪声问题,学界的理解依然有限。
为了解决这个问题,本文对于人脸识别领域作出以下贡献:
(1)清理出了现有大规模人脸数据集(包括MegaFace和MS-Celeb-1M)的干净子集,并提出了一个新的无噪声人脸数据集IMDb_Face;
(2)利用原始数据集以及清理后的干净子集,对MegaFace和MS-Celeb-1M数据集中的噪声特性和来源做了全面的分析,发现干净子集对于提高人脸识别精度效果显著;
(3)本文提出了一种用于数据清理的标注流程,大量的用户调研显示该流程是高效且可控的。
IMDb-Face数据集已开源在:https://github.com/fwang91/IMDb-Face。
传送门:https://arxiv.org/abs/1807.11649
代表性论文:基于模型共识的大规模无标注数据标签传播方法(Consensus-Driven Propagation in Massive Unlabeled D ata for Face Recognition)

人脸识别中,随着深度学习模型参数量的增大,所需要训练数据的人工标注量也越来越多。然而人工标注的错误难以避免,当人工标注的可靠性不如模型本身的时候,数据标注所带来的增益会远远低于标注本身耗费的劳动量。
此时,需要使用一种合理的方式来利用无标注数据。该问题与“半监督学习”任务相似,但在人脸识别这类数据量和类别数量都很大的任务中,则存在显著的不同之处:首先,真实情况下,无标注数据的来源通常没有限制,因此光照、姿态、遮挡等会有很大的差异,这种情况下基于单模型的半监督方法会产生较大偏差。
其次,传统的半监督学习通常假设无标注数据的标签集合和已标注数据的标签集合是完全重合的,从而标签可以在无标注数据上进行传播。然而,在人脸识别任务中,由于无标注数据来源无限制,因此无法保证获取的无标注数据的标签在已标注数据中出现过。
这些差异使得传统的半监督学习无法直接运用在这个问题上。本文工作不仅突破了这些限制,还证明了无标注数据可以达到和有标注数据相接近的效果。
作者用9%的有标注数据和91%的无标注数据,在MegaFace上达到了78.18%的准确性,接近使用了100%的有标注数据的结果78.52%。
传送门:https://arxiv.org/abs/1809.01407
物体检测与跟踪
代表性论文:量化模仿-训练面向物体检测的极小CNN模型(Quantization Mimic: Towards Very Tiny CNN for Object Detection)
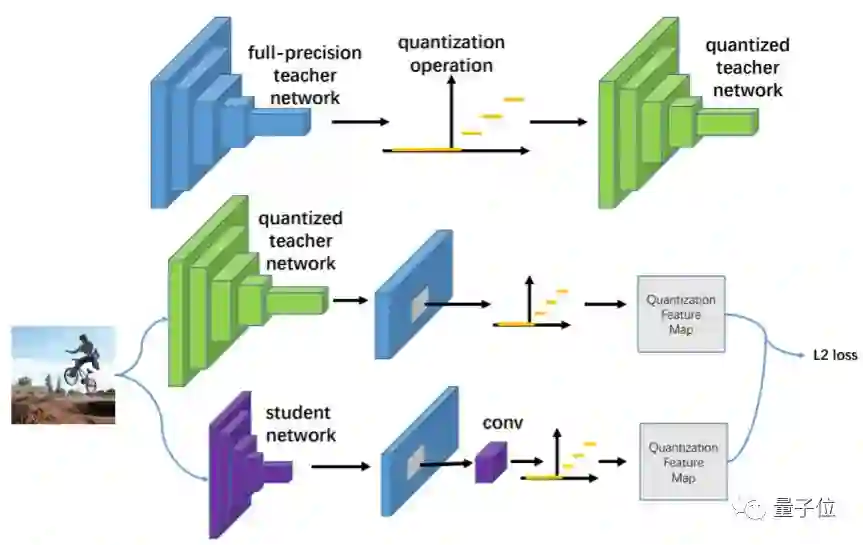
由于极小CNN模型有限的模型表达能力,训练针对复杂视觉任务(如物体检测)的极小CNN通常充满挑战。
本文致力于提出一种简单而通用的框架—量化模仿,来训练面向物体检测任务的极小CNN模型。在本文框架中,作者提出联合模仿与量化的方法来减小物体检测CNN模型的参数量实现加速。
模仿方法通过转移教师网络(teacher network)所学习到的物体检测知识,来增强学生网络(student network)的物体检测性能;量化方法在不降低模型检测性能的条件下,将全精度网络的参数进行量化,实现网络加速。如果大型教师网络通过量化实现加速,那么小型学生网络的搜索空间会大大降低。
本文基于该性质,提出了先量化大型教师网络,然后使用学生网络模仿量化后大型教师网络的方法,实现面向物体检测的极小型CNN模型的训练。
本文使用了不同的主干网络(VGG和ResNet)和不同的检测框架(Faster R-CNN和R-FCN)充分检验了该训练框架的性能和泛化能力。在有限计算量的限制下,该框架在Pascal VOC和WIDER Face数据集的物体检测性能超越了当前物体检测的先进水平。
传送门: https://arxiv.org/abs/1805.02152
代表性论文:可分解网络—基于子图表示的高效场景图生成算法(Factorizable Net: An Efficient Subgraph-based Framework for Scene Graph Generation)

随着计算机视觉的发展,场景图生成得到越来越多业内研究人员的关注。场景图生成不仅需要检测出来图像中的物体,还需要识别物体之间的关系。
与一般的物体检测任务相比,场景图因为引入了物体之间的两两关系,极大的扩充了输出结果的语义空间,因而可以蕴含更多图像的语义信息。但是,由于物体之间可能存在的关系数目和图像中物体数目的平方成正比,而目前已有的场景图生成算法往往对每一个可能存在的关系都用一个特征向量表示,因此大量的关系特征向量使模型过于庞大且缓慢,极大限制了物体候选框的数目。
本文针对已有场景图生成算法的缺点,通过共享语义相近的关系特征(称为子图特征),极大简化了网络在中间阶段的特征表示,并且提高了模型的检测速度。
此外,本文还提出了“空间加权信息传递”模块和“空间感知关系检测”模块,使模型在信息传递和最终的物体关系检测时,能够更加充分的利用物体之间的空间联系,得到更好的物体检测和关系识别结果。
在目前主流的VRD和Visual Genome上的实验结果表明,本文提出的基于子图特征的高效场景图生成算法在识别精度和测试速度上均超过目前业内最好结果。
目前该算法的PyTorch版本已经开源:https://github.com/yikang-li/FactorizableNet
传送门: https://arxiv.org/abs/1806.11538
代表论文:基于干扰对象感知的长时单目标跟踪算法(Distractor-aware Siamese Networks for Visual Object Tracking)
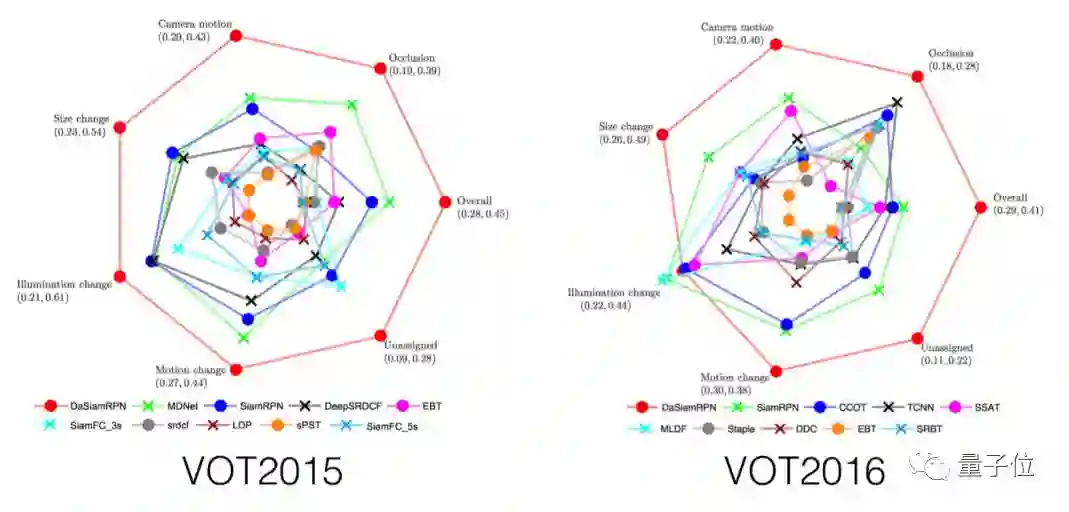
近年来,孪生网络结构因为性能和速度的平衡性在跟踪领域受到了极大的关注。但是大多数的孪生网络跟踪器使用的特征都只能区分前景和非语义背景。而跟踪过程中,也有语义的背景带来的干扰,其通常是限制跟踪性能的重要因素。
在本文中,作者首先分析了训练过程中样本对跟踪过程的影响,发现正负样本不均衡是导致跟踪性能瓶颈的主要原因。
本文从两个角度解决这个问题,训练过程中,通过控制采样方式来控制正负训练样本的分布,并且引入含有语义的负样本;测试过程中提出干扰物感知模块来调整跟踪器,使其适应当前的视频。
除此之外,作者还设计了一种局部到全局的搜索区域增长方法,将算法扩展到长期跟踪。在UAV20L、UAV123、VOT2016、VOT2017数据集上,本文提出的方法均可取得目前最好的结果,同时速度可达到160FPS。
本文提出的方法在ECCV2018召开的VOT Challenge Workshop上获得了实时目标跟踪比赛的冠军。
传送门: https://arxiv.org/abs/1808.06048
视频分析
代表性论文:基于视觉特征链接和时序链接的视频人物检索
(Person Search in Videos with One Portrait Through Visual and Temporal Links)
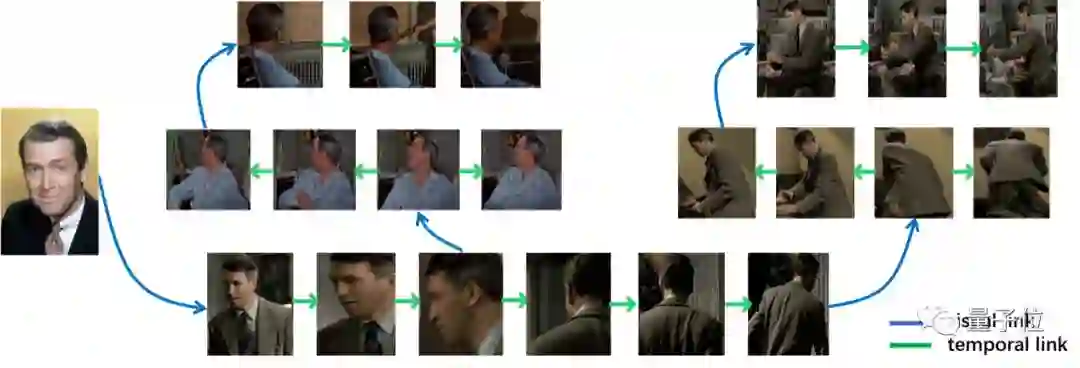
虽然人脸识别和行人再识别已经在学术界取得了非常多的研究成果,但是在复杂庞大的视频数据库中(如监控视频或电影数据库),很多时候并不能看到人物清晰的正脸, 这时人脸识别就无法发挥作用。
而行人再识别关注的通常是一小段时间内一个比较小的区域的行人匹配,也就是说在行人再识别的问题中,人物的服饰装扮以及周围的环境都不会有太大的变化。
该假设大大限制了行人再识别技术在实际场景中的应用。针对这些缺陷,本文提出了一个更加贴近实际应用的研究问题—人物检索, 即给定一张人物正面照,在一个非常大的图像(视频)库中检索出该人物的所有实例。例如,给定一个犯人的画像,在一个城市的监控视频中找出所有他/她出现过的视频片段,或者给定一个演员的自拍,找出他/她在所有电影和电视剧中的镜头。
为了研究这个问题,本文首先建立了一个大规模的数据集—Cast Search in Movies (CSM),包含了 1218位演员以及他们来自的192 部电影的超过 12 万个短视频。
人物检索问题的主要难点在于,给定的图像和该人物在数据库中的实例在视觉观感上有时有较大差别。为了应对这个难点,本文提出了一种基于基于特征和时序链接的标签传播算法。
并且提出了一种竞争共识机制,来解决标签传播中容易受噪声影响的问题。同时通过渐进式迭代的方式,大大提高标签传播的效率。实验证明,这种传播算法在人物检索中大大优于单纯应用人脸识别和行人再识别技术。
传送门: https://arxiv.org/abs/1807.10510
自动驾驶场景理解与分析
代表性论文:基于逐点空间注意力机制的场景解析网络(PSANet: Point-wise Spatial Attention Network for Scene Parsing)
场景解析(scene parsing)是基于自动驾驶任务中的一个重要问题,能够广泛应用于机器人导航、自动驾驶等领域。
场景图像中的上下文信息(contextual information),尤其是大范围的上下文信息,对于场景解析有着非常重要的作用。传统的卷积神经网络因为其结构,信息流动局限在当前像素周围的局部区域中,对于大范围的上下文信息获取和表达能力有限。
在本篇论文中,作者提出了一种逐点的空间注意力机制神经网络模块(point-wise spatial attention network),来有效获取图片中大范围的上下文信息,显著改善神经网络的场景解析性能。
针对视觉特征图(feature map)中的每一点对,该模块会预测两个点之间的上下文依赖,且该预测会同时考虑到两个点原本的语义信息以及两个点之间的位置关系。
最终预测出的点与点之间的上下文依赖关系,可以用逐点的注意力机制进行表示。为了充分实现特征图中大范围的信息流通,作者设计了一种双向信息流动机制,来实现上下文信息的充分融合,提升模型的场景解析性能。
实验表明,本文提出的逐点空间注意力模型能够显著改善基准模型的场景解析性能,在多个场景解析与语义分割数据集上,本文算法都达到了当前的最优性能。
传送门:https://hszhao.github.io/projects/psanet/
代表性论文:基于局部相似性的半监督单目深度估计(Monocular Depth Estimation with Affinity, Vertical Pooling, and Label Enhancement)

单目深度估计在基于视觉传感器的自动驾驶和辅助驾驶任务中有着重要的作用。虽然边缘、纹理等绝对特征可以被卷积神经网络(CNNs)有效地提取出来,但基于卷积神经网络的方法大多忽略了图像中相邻像素之间存在的约束关系,即相对特征。
为了克服这个缺陷,本文提出了一种结合相对特征和绝对特征的端到端网络,对不同图像位置的关系进行了显式的建模。
另外,作者利用了深度图中一个显著的先验知识,即深度图中距离变化主要处于竖直方向上,认为对竖直方向上的特征进行建模将有利于深度图的精细化估计。
本文的算法中使用了竖直方向的池化操作来对图像在竖直方向上的特征进行了显式建模。
此外,由于从激光雷达获得的真实深度图中的有效数值非常稀疏,作者采用了已有的立体匹配的算法生成高质量的深度图,并用生成的密集深度图作为辅助数据用于训练。
本文实验证明了提出的算法在KITTI数据集上取得了优异的效果。
传送门: http://openaccess.thecvf.com/content_ECCV_2018/papers/YuKang_Gan_Monocular_Depth_Estimation_ECCV_2018_paper.pdf
3D视觉
代表性论文:基于参数化卷积的点云深度学习
(SpiderCNN: Deep Learning on Point Sets with Parameterized Convolutional Filters)
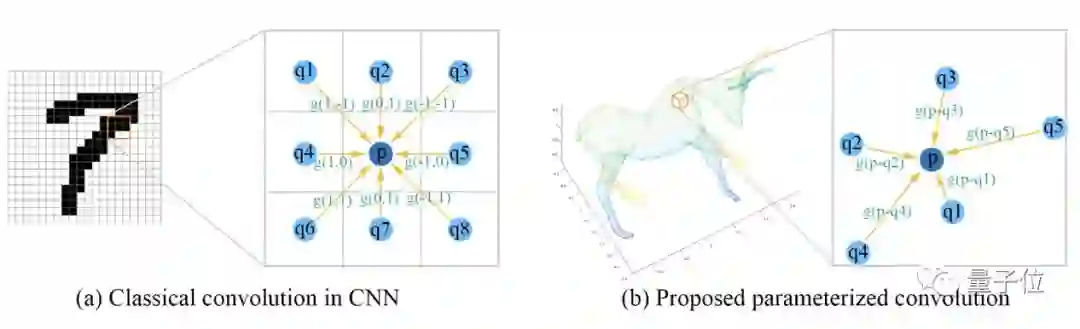
尽管深度学习在大量计算机视觉问题上取得了成功,如何将深度学习应用于非规则数据上依然是一个极富挑战性的问题。
在这篇文章中,作者提出一种新型的卷积结构SpiderCNN,来有效提取点云中的几何特征。
具体来说,SpiderCNN利用参数化卷积技术,将传统的卷积操作从规则网格拓展到非规则网格。我们利用阶跃函数之积来表征点云的局部几何特征,然后利用泰勒多项式来保证该结构的表达能力。
SpiderCNN同时继承了传统CNN的多尺度特性,从而能够有效地提取层级化的深度语义信息。SpiderCNN在ModelNet40这个标准测试集上取得92.4%的优异结果。
传送门: https://arxiv.org/abs/1803.11527
底层视觉算法
代表性论文:基于生成对抗网络的增强超分辨率方法
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)

基于生成对抗网络的图像超分辨率模型SRGAN能够生成更多的纹理细节。然而,它恢复出来的纹理往往不够自然,也常伴随着一些噪声。
为了进一步增强图像超分辨率的视觉效果,本文深入研究并改进了SRGAN的三个关键部分——网络结构、对抗损失函数和感知损失函数,提出了一个增强的ESRGAN模型。
具体地,本文引入了一个新网络结构单元RRDB (Residual-in-Resudal Dense Block);借鉴了相对生成对抗网络(relativistic GAN)让判别器预测相对的真实度而不是绝对的值;还使用了激活前的具有更强监督信息的特征表达来约束感知损失函数。
得益于以上的改进,本文提出的ESRGAN模型能够恢复更加真实自然的纹理,取得比之前的SRGAN模型更好的视觉效果。
ESRGAN模型同时在ECCV2018的PIRM-SR比赛中获得了最好的感知评分,取得了第一名。
传送门: https://arxiv.org/abs/1809.00219
视觉与自然语言的综合理解
代表性论文:重新研究图像语言描述中隐变量的表达(Rethinking the Form of Latent States in Image Captioning)

本文重新审视了图像描述模型中隐变量的表示方式。循环神经网络如LSTM作为解码器在图像语言描述中有大量的应用,现有的图像描述模型通常固定得将解码器的隐变量表示成一维向量。
这样带来两个问题:(1)为了和隐变量保持一致,图像也被压缩成了一维向量,丢失了重要的空间信息,导致描述生成时的条件减弱,模型更多得依赖于多元词组的统计信息,更容易产生出现频率更高的词组;(2)一维向量的表示,使得对隐变量在解码过程中的变化,即解码过程的内部动态,难以进行可视化和分析。
基于以上几点考虑,本文提出将隐变量表示为多通道二维特征是更好的选择。其利用二维特征的空间性提出一种简单有效的方式成功的可视化和分析了解码过程中神经网络的内部动态,以及中间介质的隐变量、作为输入的图片、作为输出的单词三者之间的联系。同时,由于二维特征保留了更多的图片信息,对应的描述模型能产生与图片更匹配的描述。
在拥有同样的参数数量的情况下,采用二维特征来表示隐变量的描述模型仅使用最简单的cell,即RNN,也超过了采用一维向量来表示隐变量的描述模型使用LSTM的效果。
传送门: https://arxiv.org/abs/1807.09958
代表性论文:面向视觉问答的问题引导混合卷积(Question-Guided Hybrid Convolution for Visual Question Answering)
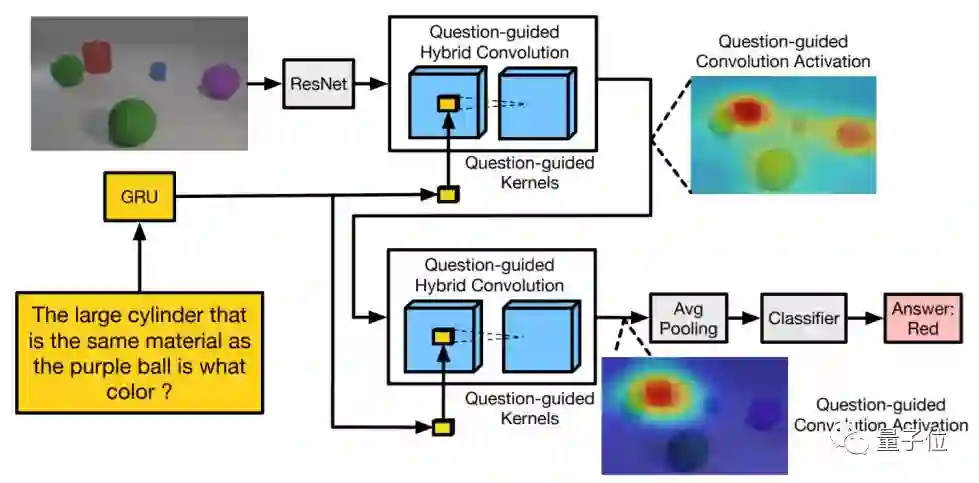
本文提出了一种面向视觉问答任务的问题引导混合卷积操作,能够有效的融合输入问题和输入图像的高层语义信息,实现高准确率的视觉问答。
现有的视觉问答系统在融合输入问题和图像时,抛弃了图像中的空间信息。为了解决该问题,本文提出由输入问题预测卷积核,对图像特征图进行问题引导的卷积操作,得到语言和图像的融合特征图。
虽然这种由问题引导卷积生成的融合特征图能够充分的融合语言和视觉的多模态信息,但是往往也会带来更多的学习参数。为了降低参数量,作者提出在视觉特征卷积时使用组卷积(group convolution),仅用问题来引导生成一部分卷积核,而另一部分卷积核与问题解耦,该方案能够有效的降低模型参数量并且防止模型过拟合。
本文提出的问题引导卷积方法,能够作为现有多模态特征整合方法的有效补充,实现高准确率的视觉问答,在多个视觉问答的数据集中的实验结果证明了该方法的有效性。
传送门: https://arxiv.org/abs/1808.02632
— 完 —
加入社群
量子位AI社群28群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


