ECCV 2018 | 行人检测全新视角:从人体中轴线标注出发
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~

论文地址:https://arxiv.org/abs/1807.01438
背景介绍
弱小目标是行人检测中一个非常普遍的问题,尤其是在自动驾驶或者监控场景中,当行人目标距离摄像头较远时,对现有算法而言非常具有挑战性。作为通用目标检测中的一个特定问题,现有基于CNN的行人检测方法依然来源于通过目标检测方法(如Faster R-CNN,SSD),这些方法采用铺设目标候选框的方式完成,我们称其为anchor-based方法。然而,anchor-based方法存在三个问题:一是需要根据特定数据集人工选定特定的anchor以更好地匹配行人目标,二是需要人工设定阈值来定义正负样本,三是训练过程中存在基于数据集标注的bias,尤其对于弱小目标,行人框中的目标信息本身就十分微弱,这种bias使得检测器更加难以胜任对弱小目标的检测。
为此,针对弱小目标检测,作者提出预测人体中轴线来代替预测人体标注框,在弱小目标检测上取得了十分惊艳的效果;此外,作为本文的另外一个贡献,作者提出利用Conv-LSTM来构建连续帧的运动信息,实验表明这种运动信息对弱小目标检测也有一定效果。
主要内容
行人检测的标注问题
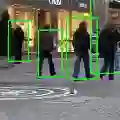
现有行人检测数据集都是采用的矩形框标注,如下图1所示,行人检测的任务就是输出包含行人目标的矩形框。对于检测网络的训练而言,只有尽可能正确的标注才会使得网络学到更具判别力的特征,进而或者更为精确的检测结果,早在CVPR2016,Zhang等人[1]就对此问题展开深入探讨,并证明采用更精细的标注会极大提升行人检测的正确率。基于矩形框标注的anchor-based方法会带来三个问题在背景内容中已经介绍过了,而采用线型标注则会克服以上问题,这也正是本文作者的motivation,如下图所示,只标注人体中轴线,其优势在于避免了矩形框标注中的背景信息。

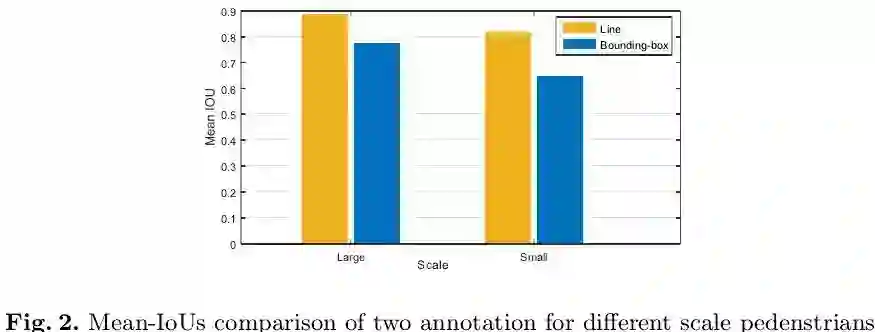
为了验证标注人体中轴线的优越性,作者采取了人工对照实验:两组实验人员分别采用框和中轴线对测试集中的行人目标进行标注,并采用官方评估协议进行评估,如下图2所示:1、中轴线标注所取得的结果明显优于框标注;2、这种优势在小目标上更为明显。因此,采用人体中轴线标注会给检测器的训练带来更少的bias。
基于中轴线定位的行人检测方法(TLL)
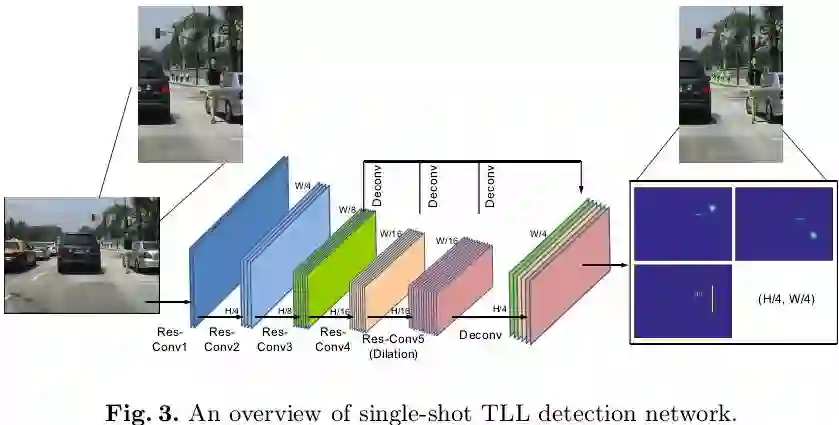
有了人体中轴线标注,如何完成行人检测任务?也即如何在有行人目标的位置预测出人体中轴线。作者将这一任务简化为3个子任务,一个网络分别输出行人目标的上顶点、下顶点和这两点之间的连接线。网络架构如下图3所示:基础网络为ResNet-50,将conv3/4/5的最后一层经过上采样后拼接起来作为多尺度特征表示,分辨率为原图的1/4,在此特征图上接3个1x1conv分别得到三个输出:上顶点置信图、下顶点置信图以及中轴线置信图。
对于训练,每一个行人目标的上下顶点构建为一个二维高斯热图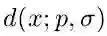
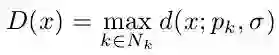
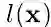
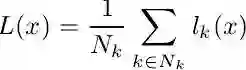
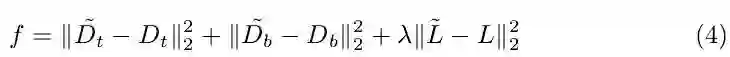
对于测试,每一张图像输入网络会输出三个置信图(上顶点,下顶点和中轴线),首先通过非极大值抑制(具体如何做论文没有公开详细细节,笔者认为可参考CornerNet[2])在上下顶点两个置信图上得到响应最大的top N个点,再将上下顶点进行配对,依据的是两个点在中轴线置信图上连线的值,如下式计算:
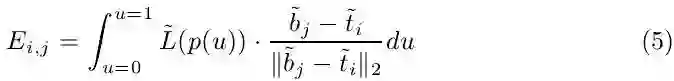
这就是一个简单的双边图匹配问题,可以通过匈牙利算法进行求解,得到的配对点连成中轴线就是一个预测的行人目标,根据数据集中固定的长宽比0.41得到行人矩形框,至此就可以用官方评估协议进行评估并和其他state-of-the-art算法进行公平对比了。
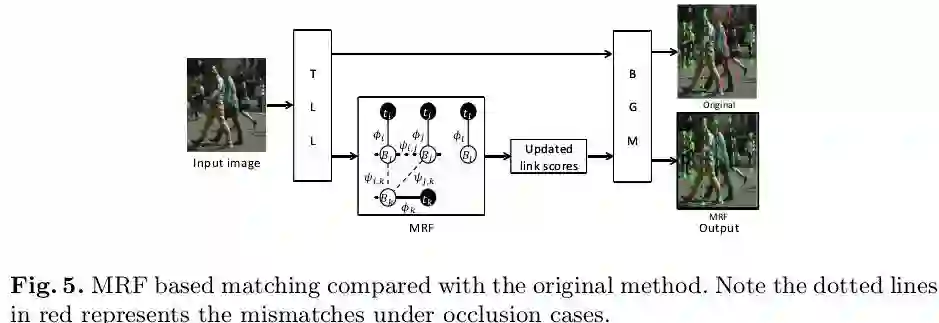
此外,作者还提出了一种基于MRF的后处理方式,重点针对的是行人自遮挡比较严重的情况,具体处理方式如下图5所示,通过这种方式对式(5)中的匹配点对的得分值进行更新得到更为准确的匹配结果(如图5中红色错误匹配对得到了修正)。
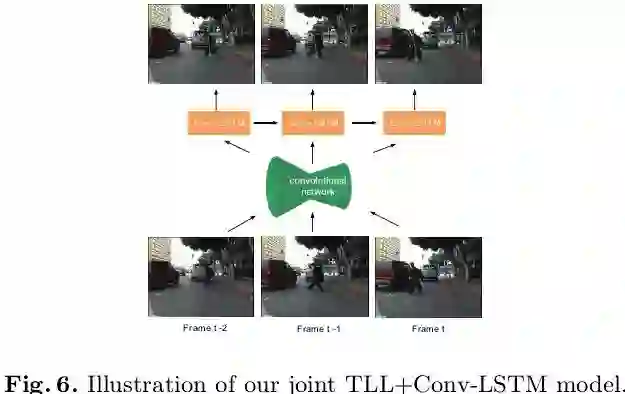
作为本文的另一个贡献,作者提出利用连续帧之间的特征融合(或者称为连续帧之间的运动信息)来进一步提高小目标检测的召回率。具体而言,在基础网络输出的特征图上接一层Conv-LSTM进行连续帧之间的特征融合,在Conv-LSTM的输出上进行三个置信图的预测,如下图6所示:
实验分析
实验细节:
验证实验在Caltech测试集上做的,训练和测试均采用的是原始标注。对比实验分别在Caltech和CityPersons验证集上和最新方法进行了全方位对比,重点验证本文算法对小目标和严重遮挡情况的检测的优越性。评估指标采用行人检测通用的Miss rate(越低越好)。
实验效果:
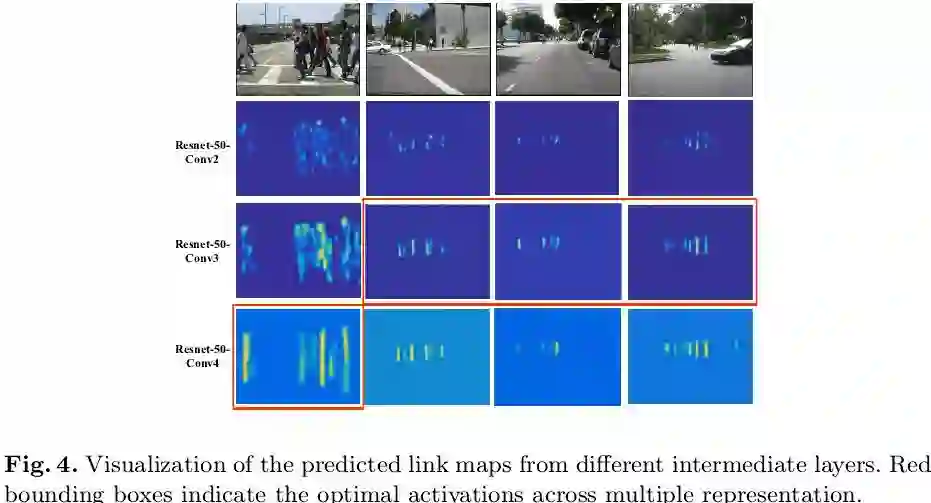
首先我们看下基础网络中对多尺度特征图的选择的直观解释,如下图4所示:最浅层conv2的响应对大小目标均不够强烈,浅层conv3对小目标的响应更为强烈而高层如conv4对大目标的响应更为强烈,因此本文的多尺度特征图选择从conv3开始,并融合conv3/4/5以胜任对不同尺度目标的检测。
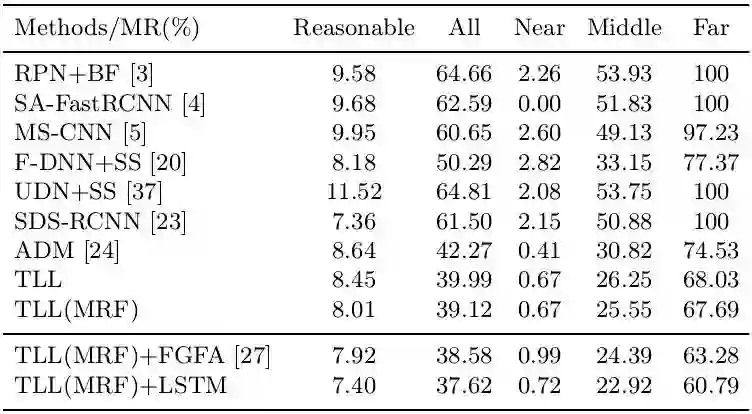
结合下表对Caltech上的结果进行分析,其中本文方法为TLL,Far代表小目标(距离摄像头较远),可以发现本文方法TLL对小目标检测的优势非常明显,不加任何后处理的miss rate达到68.03,已经远远优于其他方法,同时可以发现加上Conv-LSTM的特征融合能进一步将miss rate降到60.79。
结合下表对CityPersons上的结果进行分析,其中heavy partial bare代表不同的遮挡程度,可以发现本文算法虽然在Reasonable子集上不占优势,但在严重遮挡情况下的miss rate要远优于其他方法,尤其是加上MRF后处理能够更好地完成自遮挡严重情况下的行人检测。

总结展望
本文贡献:
(1)深入研究了行人检测中的标注问题,并分析和验证了中轴线标注的优越性。
(2)基于中轴线标注,提出了一种基于中轴线预测的行人检测方法,实验表明对小目标检测十分有效。
(3)实验分析并验证了:融合连续帧特征信息可以进一步提升小目标检测的性能。
个人见解:
(1)本文从行人检测最低层的问题(标注)出发,为行人检测贡献了一种全新的解决方案,是极具启发性的一篇工作。
(2)本文和同发表于ECCV2018的CornerNet[2]有很多共通之处,我们可以将这两种方法称为anchor-free方法,它们抛弃了anchor-based方法需要人工设定不同大小比例anchors的束缚,取得了更为出色的检测性能。其实早在CVPR2016的YOLOv1也是anchor-free的方法,为了突出real-time的亮点,检测性能较anchor-based方法还有一定差距,为此从YOLOv2开始作者就又采用了anchor-based的思路。本文和CornerNet[2]的成功再一次打开了anchor-free的视角,前者是预测中轴线,后者是预测对角点,方式不同但本质一致。有关CornerNet[2]的技术解读已发表于极市平台,详情可见[3]。
参考文献
[1] How Far are We from Solving Pedestrian Detection? CVPR (2016)
[2] CornerNet: Detecting Objects as Paired Keypoints. ECCV (2018)
[3] ECCV 2018 | CornerNet:目标检测算法新思路
END
—本文为极市原创,欢迎大家投稿,转载请后台留言—
ps.ECCV2018收录论文已开放并支持pdf下载,感谢极市cv交流群小伙伴的整理,在“极市平台”公众号后台回复“ECCV”,即可获取全部论文pdf网盘下载链接~
*推荐文章*
ICPR 图像识别与检测挑战赛冠军方案出炉,基于偏旁部首来识别 Duang 字
PS-GAN:如何合成高质量行人图像提升行人检测性能?
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~