CMU 对现有开源和未开源的 AI 代码生成模型进行了全面深入的系统性评估,并分析了它们在 C、C++、Python 等 12 中不同编程语言中的代码自动完成表现。
最近,语言模型(Language Model, LM)在建模编程语言源代码方面展现出了令人印象深刻的性能。这些模型擅长代码自动生成以及从自然语言描述中生成代码等下游任务。当前 SOTA 大规模语言代码模型(如 Austin et al. (2021))在基于 AI 的编程辅助领域已经取得了重大进展。此外,OpenAI 推出的 Codex 已经部署在了现实世界生产工具 GitHub Copilot 中,用作一个基于用户上下文自动生成代码的 in-IDE 开发者助手。
尽管大规模语言代码模型取得了巨大成功,但最强大的模型并不是公开可用的。这阻止了这些模型在资源充足公司之外的应用,并限制了资源匮乏机构在该领域的研究。以 Codex 为例,它通过黑盒 API 调用提供了该模型输出的收费访问,但模型的权重和训练数据不可用。这阻止了研究人员微调模型,无法适应代码完成之外的领域和任务。无法访问模型的内部也阻止了研究社区研究它们的其他关键方面,例如可解释性、用于实现更高效部署的模型蒸馏以及融合检索等额外组件。
同时,GPTNeo、GPT-J 和 GPT-NeoX 等中等和大规模预训练语言模型是公开可用的。尽管这些模型是在包括新闻文章在内的多样化文本、在线论坛以及少量 GitHub 软件存储库的混合资源上训练的,但它们可以用于生成具有合理性能的源代码。此外,还有一些仅在源代码上进行训练的全新开源语言模型,比如 CodeParrot 是在 180GB 的 Python 代码上训练的。
遗憾的是,这些模型的大小和训练方案的多样性以及彼此之间都缺乏比较,许多建模和训练设计决策的影响仍不清楚。
在近日一篇论文中,来自 CMU 计算机科学学院的几位研究者对跨不同编程语言的现有代码模型——Codex、GPT-J、GPT-Neo、GPT-NeoX 和 CodeParrot 进行了系统评估。他们希望通过比较这些模型来进一步了解代码建模设计决策的前景,并指出关键的缺失一环,即迄今为止,没有大规模开源语言模型专门针对多编程语言的代码进行训练。研究者推出了三个此类模型,参数量从 160M 到 2.7B,并命名为「PolyCoder」。
研究者首先对 PolyCoder、开源模型和 Codex 的训练语评估设置进行了广泛的比较;其次,在 HumanEval 基准上评估这些模型,并比较了不同大小和训练步的模型如何扩展以及不同的温度如何影响生成质量;最后,由于 HumanEval 只评估自然语言和 Python 生成,他们针对 12 种语言中的每一种都创建了相应未见过的评估数据集,以评估不同模型的困惑度。
结果表明,尽管 Codex 声称最擅长 Python 语言,但在其他编程语言中也表现出奇得好,甚至优于在 Pile(专为训练语言模型设计的 825G 数据集)上训练的 GPT-J 和 GPT-NeoX。不过,在 C 语言中,PolyCoder 模型取得的困惑度低于包括 Codex 在内的所有其他模型。
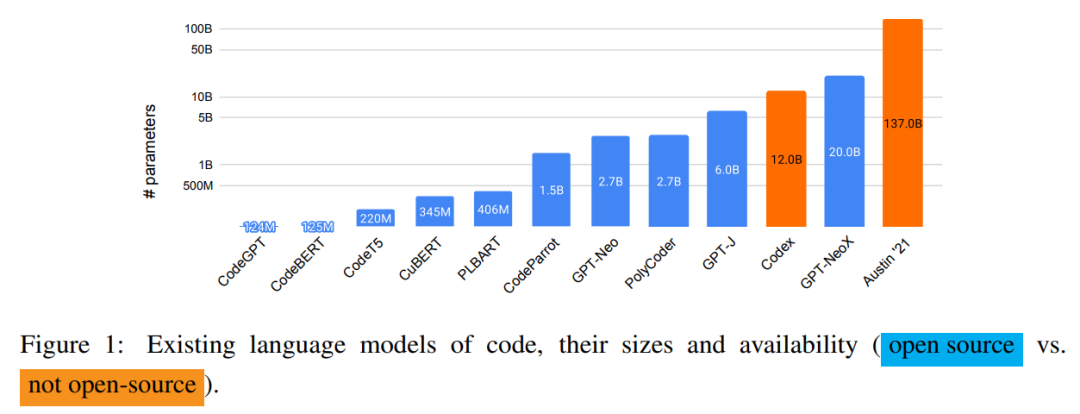
下图 1 展示了现有语言代码模型及它们的大小和可用性,除 Codex 和 Austin'21 之外全部开源。
研究者还讨论了代码语言建模中使用的三种流行的预训练方法,具体如下图 2 所示。
外在评估。代码建模的最流行下游任务之一是给定自然语言描述的代码生成。遵循 Chen et al. (2021),他们在 HumanEval 数据集上评估了所有模型。该数据集上包含 164 个以代码注释和函数定义形式描述的提示,它们包括参数名称和函数名称以及用于判断生成代码是否正确的测试用例。
内在评估。为了评估不同模型的内在性能,他们在一组未见过的 GitHub 存储库上计算了每种语言的困惑度。并且,为了防止 GPT-Neo 和 GPT-J 等模型在训练到测试的过程中出现数据泄露,他们在评估数据集上移除了在 Pile 训练数据集的 GitHub 部分出现的存储库。
研究者主要选取了自回归预训练语言模型,这类模型最适合代码完成任务。具体地,他们评估了 Codex,OpenAI 开发的这一模型目前部署在了现实世界,并在代码完成任务中展现出了卓越的性能。Codex 在 179GB(重复数据删除后)的数据集上进行训练,该数据集包含了 2020 年 5 月从 GitHub 中获得的 5400 万个公开 Python 存储库。
至于开源模型,研究者比较了 GPT 的三种变体模型 ——GPT-Neo(27 亿参数)、GPT-J(60 亿参数)和 GPT-NeoX(200 亿参数)。其中,GPT-NeoX 是目前可用的最大规模的开源预训练语言模型。这些模型都在 Pile 数据集上进行训练。
目前,社区并没有专门针对多编程语言代码进行训练的大规模开源语言模型。为了弥补这一缺陷,研究者在 GitHub 中涵盖 12 种不同编程语言的存储库集合上训练了一个 27 亿参数的模型——PolyCoder。
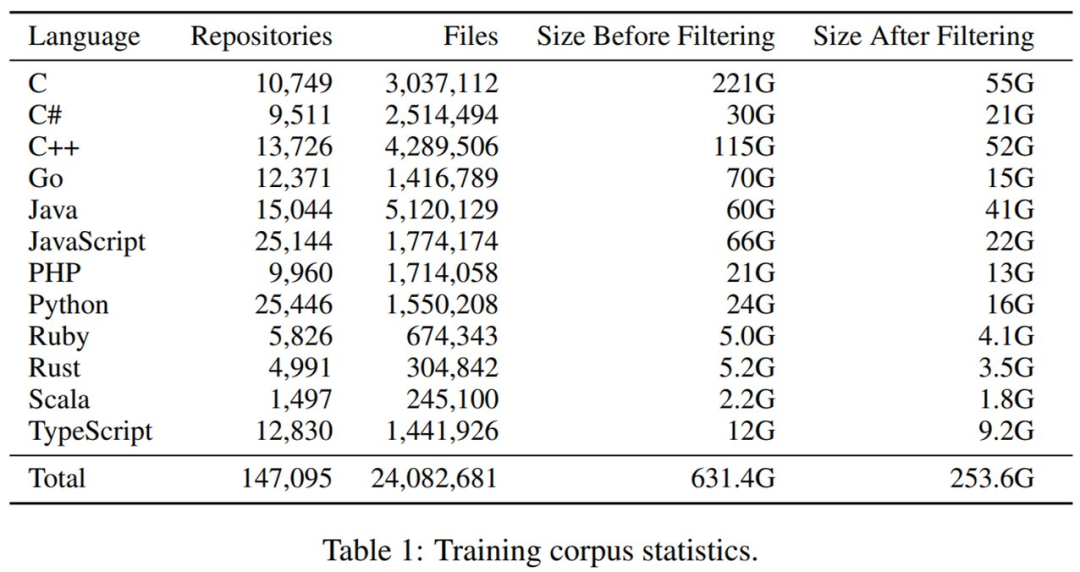
原始代码库集合。研究者针对 12 种流行编程语言克隆了 2021 年 10 月 GitHub 上 Star 量超 50 的的最流行存储库。最开始未过滤的数据集为 631GB 和 3890 万个文件。
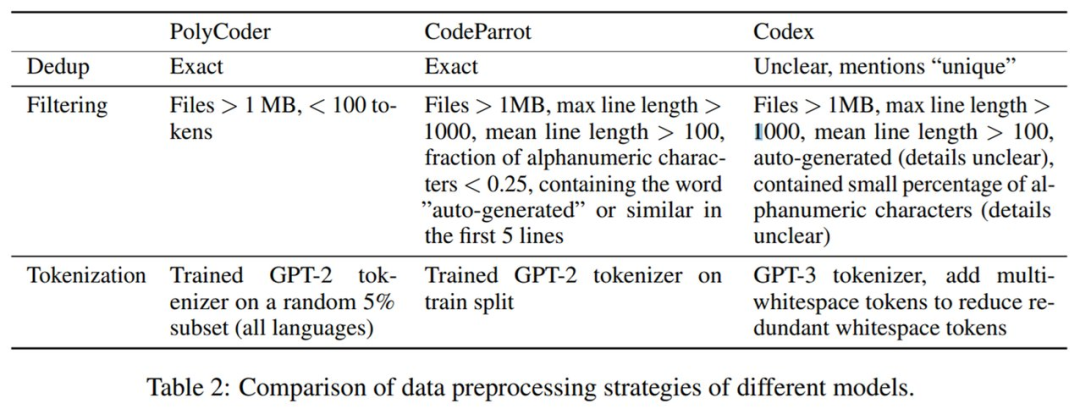
接着进行数据预处理。PolyCoder 与 CodeParrot、Codex 的数据预处理策略的详细对比如下表 2 所示。
最后是重复数据删除和过滤。整体来看,过滤掉非常大和非常小的文件以及删除重复数据,将文件总量减少了 38%,数据集大小减少了 61%。下表 1 展示了过滤前后数据集大小的变化。
考虑到预算,研究者选择将 GPT-2 作为模型架构。为了探究模型大小缩放的影响,他们分别训练了参数量为 1.6 亿、4 亿和 27 亿的 PolyCoder 模型,并使用 27 亿参数的模型与 GPT-Neo 进行公平比较。
研究者使用 GPT-NeoX 工具包在单台机器上与 8 块英伟达 RTX 8000 GPU 并行高效地训练模型。训练 27 亿参数 PolyCode 模型的时间约为 6 周。在默认设置下,PolyCode 模型应该训练 32 万步。但受限于手头资源,他们将学习率衰减调整至原来的一半,训练了 15 万步。
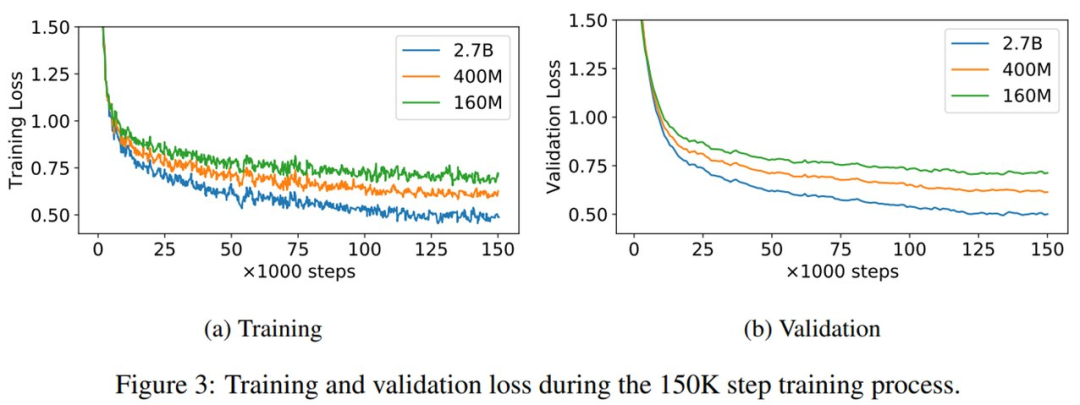
1.6 亿、4 亿和 27 亿参数量 PolyCode 模型的训练和验证损失曲线如下图 3 所示。可以看到,即使训练 15 万步之后,验证损失依然降低。
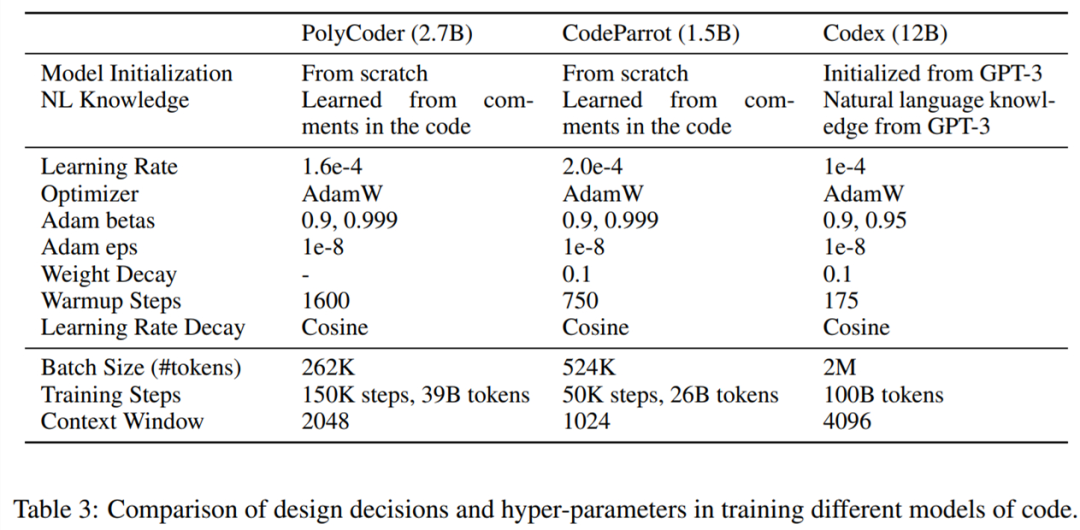
下表 3 展示了训练不同代码模型中的设计决策和超参数比较情况。
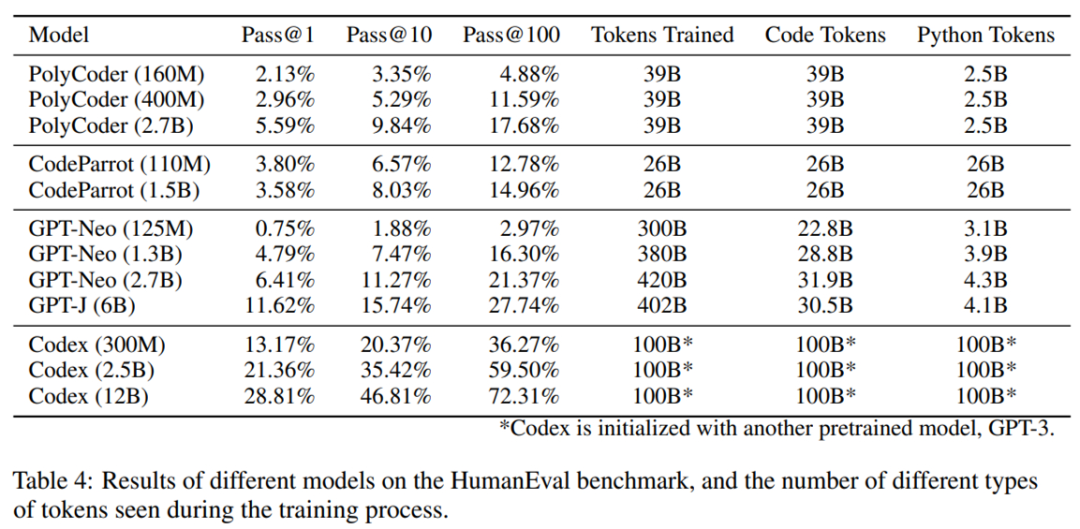
整体结果如下表 4 所示。在现有模型中,PolyCoder 弱于类似规模的 GPT-Neo 和规模更小的 Codex 300M。总的来说,该模型不如 Codex 和 GPT-Neo/J,但强于 CodeParrot。
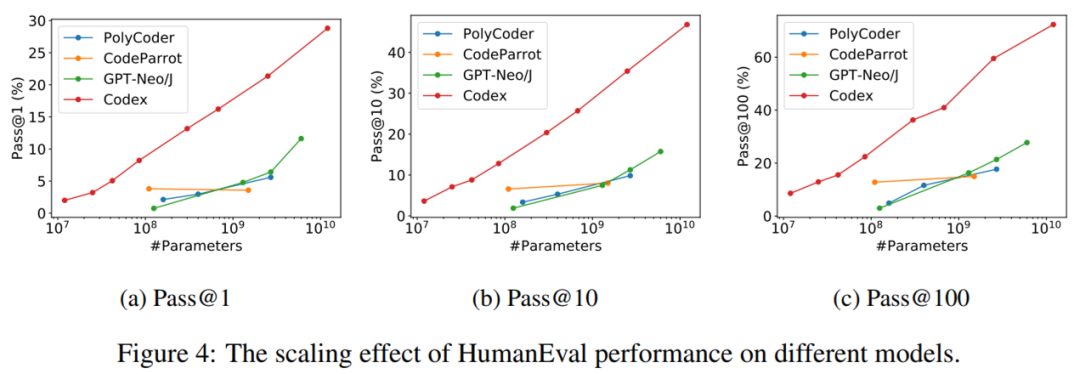
缩放影响。为了进一步了解模型参数量对 HumanEval 代码完成性能的影响,研究者在下图 4 中展示了 Pass@1、Pass@10 和 Pass@100 的性能变化。
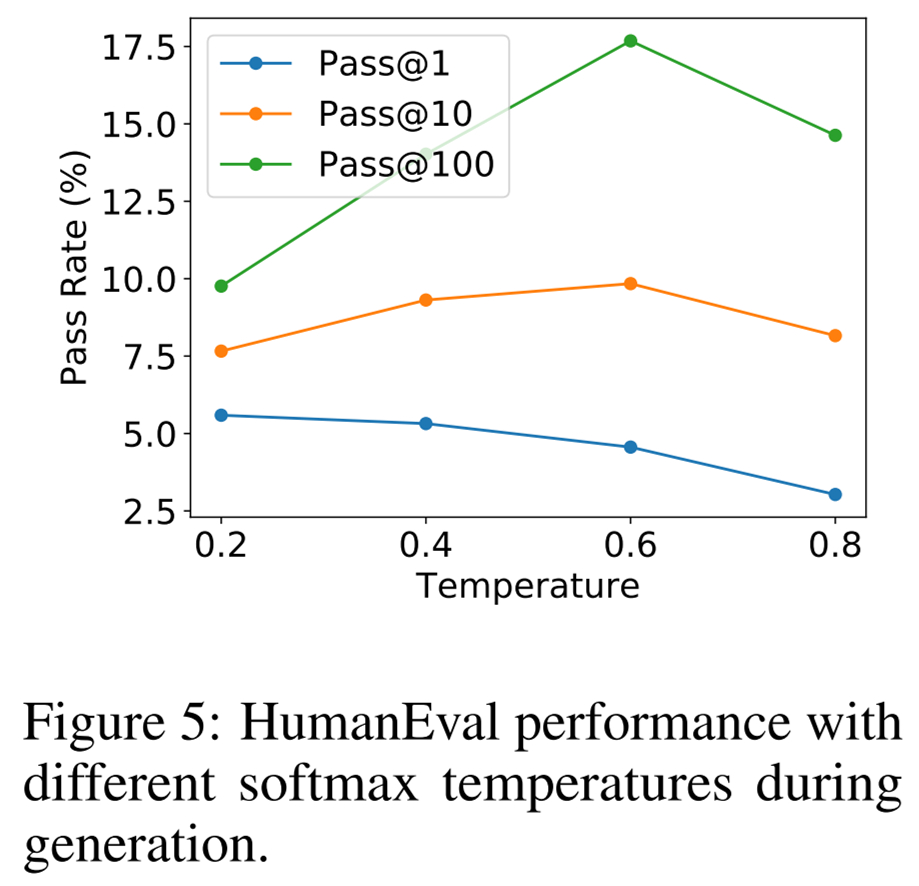
温度影响。上述所有结果都是通过采样不同温度的语言模型并为每个指标选择最佳值获得的。研究者同样感兴趣的是不同的温度如何影响最终生成质量,结果如下图 5 所示。
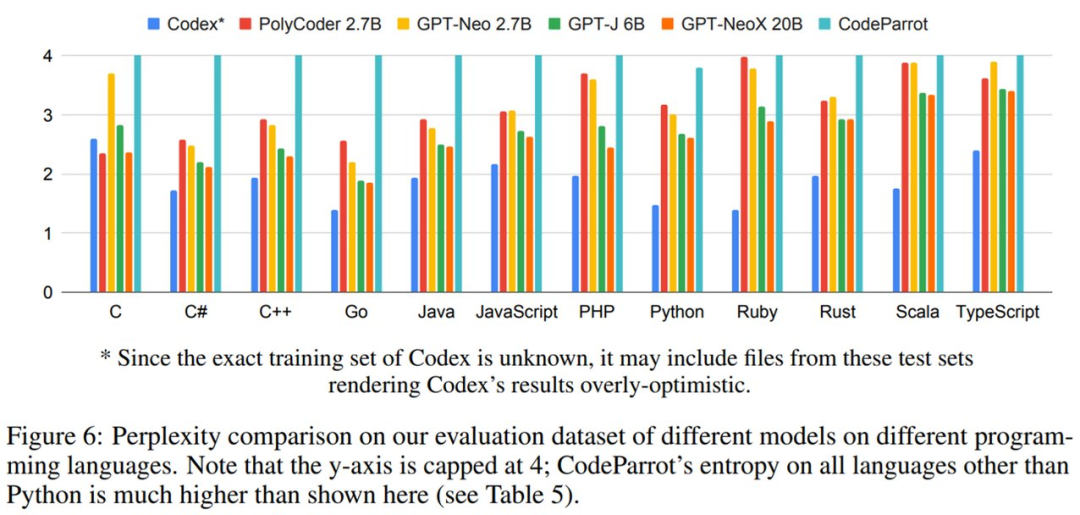
不同模型在评估数据集上的困惑度结果如下图 6 所示。困惑度得分最高为 4。可以看到,PolyCoder 在 C 语言中优于 Codex 和其他所有模型。并且,仅与开源模型相比,PolyCoder 在 C、JavaScript、Rust、Scala 和 TypeScript 中的表现优于类似规模的 GPT-Neo 2.7B。
此外,除 C 语言之外的其他 11 种语言,包括 PolyCoder 在内的所有开源模型的表现都弱于 Codex。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com