即插即涨2-3%!AC-FPN:用于目标检测的注意力引导上下文的特征金字塔网络
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI深度视线 | 论文已上传,文末附下载方式
AC-FPN——用于目标检测的注意力引导上下文的特征金字塔网络 ,即插即用的新FPN模 块,替换Cascade R-CNN、Mask R-CNN等网络中的FPN,可直接涨点2%-3%!
论文:https://arxiv.org/abs/2005.11475
代码:https://github.com/Caojunxu/AC-FPN
Authors:腾讯&华南理工大学
1
摘要

对于目标检测,如何解决高分辨率输入上的特征图分辨率与感受野之间的矛盾要求仍然是一个悬而未决的问题。
在本文中,为了解决此问题,我们建立了一种新颖的体系结构,称为注意力引导的上下文特征金字塔网络(AC-FPN),该体系结构通过集成注意力导向的多路径特征来利用来自各个大型感受野的判别信息。该模型包含两个模块
第一个是上下文提取模块(CEM),它从多个感受野中探索大量上下文信息。
第二个模块是注意力引导模块(AM),为了处理冗余的上下文关系可能导致的误定位和误识别。该模块可以通过使用注意力机制来自适应捕获对象的显著依赖性。AM由两个子模块组成,即上下文注意模块(CxAM)和内容注意模块(CnAM),它们分别专注于捕获区分性语义和定位精确位置。
最重要的是,我们的AC-FPN可以轻松插入现有的基于FPN的模型中。关于目标检测和实例分割的大量实验表明,带有我们提出的CEM和AM的现有模型大大超过了没有它们的同类模型,并且我们的模型成功获得了最新的结果。
2
本文方法
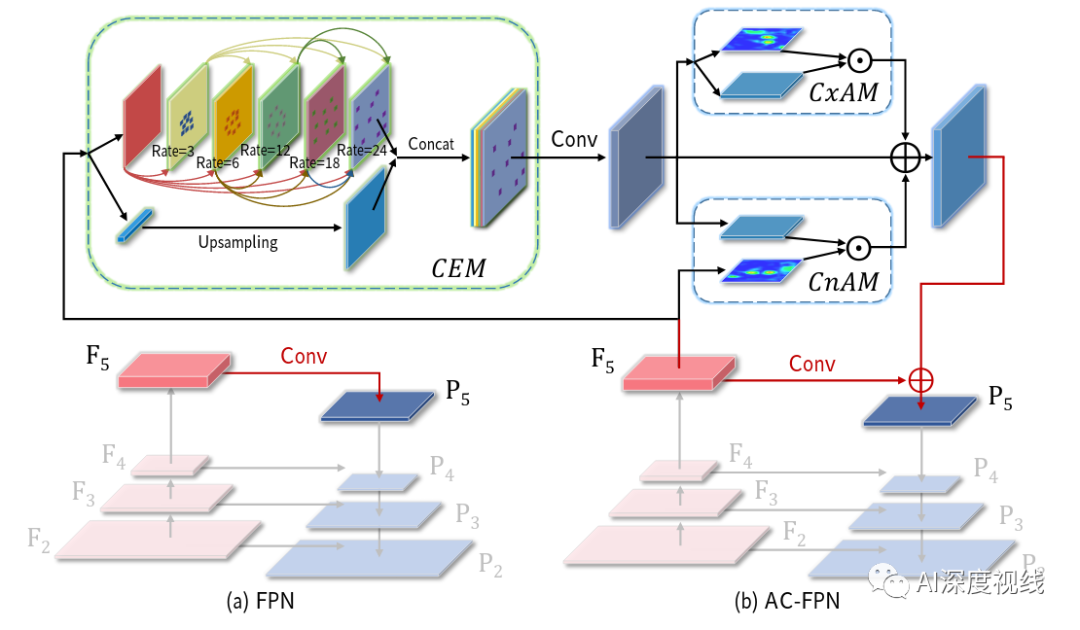
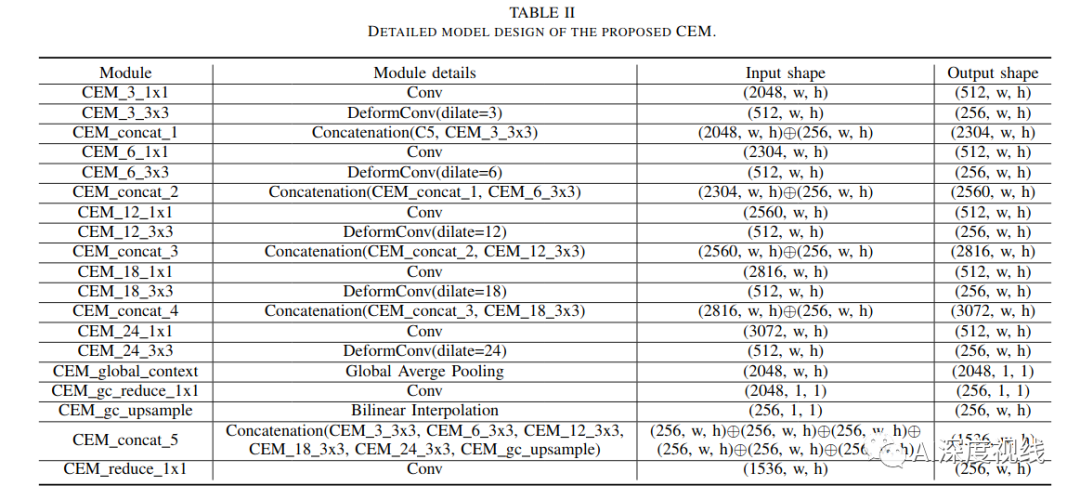
2.1 上下文抽取模块(CEM)
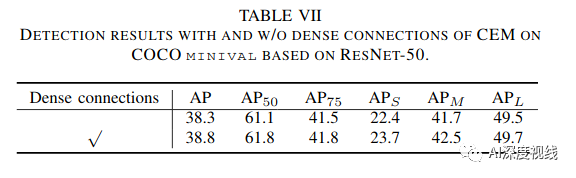
并且,为了精细地合并多尺度的信息,我们在CEM中使用了密集连接,每个扩展层的输出与输入特征图连接,然后输入到下一个扩展层。DenseNet使用密集连接来解决梯度消失的问题,在CNN模型越来越深的情况下加强特征传播。相比之下,我们采用密集的方式来实现具有不同感受野的特征在尺度上的多样性。
最后,为了保持初始输入的粗粒度信息,我们将扩展层的输出与上采样的输入连接起来,并将最小值输入到1×1卷积层,以融合粗粒度和细粒度的特征。
具体细节参考下表:
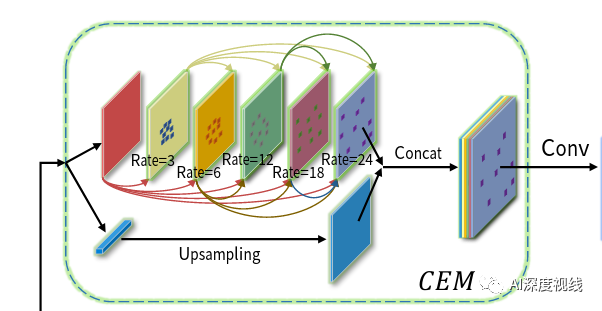
2.2 注意力引导模块(AM)
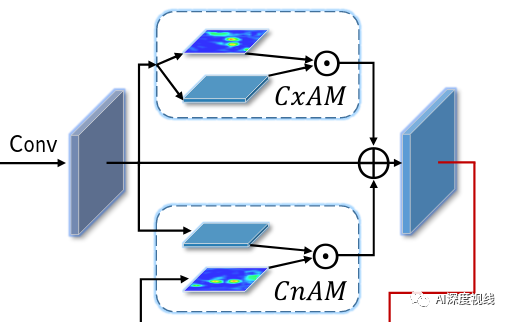
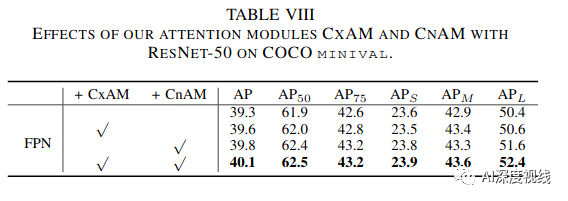
虽然CEM可以接入较丰富的感受野信息,但不是所有的信息都会对目标检测精度有效果,反而冗余的信息可能错误的引导bbox proposals而降低精度。为了去除这种负面影响并进一步提升特征图的表达能力,提出注意力引导模块,能够捕获具有强语义和精确位置的强依赖关系。AM包括两个部分:
-
上下文注意力模型CxAM
为了主动捕获子区域之间的语义依赖,这里引入了一个基于自我注意机制的上下文注意模块CxAM。我们将上述由CEM产生并包含多尺度感受野信息的特征传给CxAM模块。在这些信息特征的基础上,CxAM适应地更加关注子区域之间的相关关系。因此,CxAM的输出特性将具有清晰的语义,并在周围的目标中包含上下文依赖关系。
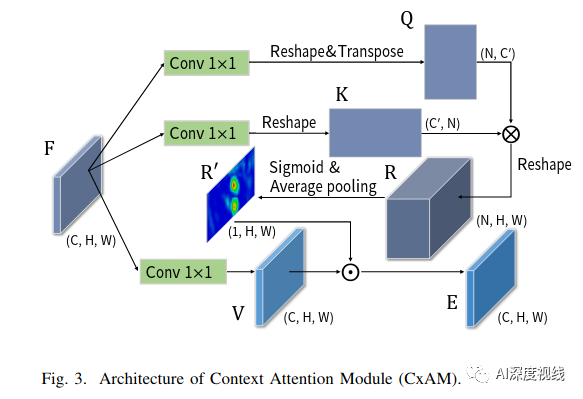
-
内容注意力模型CnAM
由于CEM中可变形卷积的影响,给定图像的几何特性被破坏,导致位置偏移。为了解决这个问题,我们设计了一个新的注意模块,称为内容注意模块(CnAM),以保持每个目标的精确位置信息。如下图所示,与CxAM类似,我们使用卷积层来转换给定的特征映射。但是,我们没有使用特征图F来产生注意矩阵,而是使用特征图F5∈R(C”xHxW),这样可以捕捉到每个物体更精确的位置。
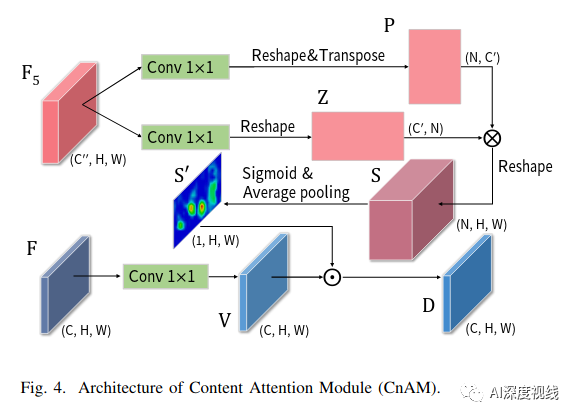
3
实验效果
3.1 CEM
CEM效果:
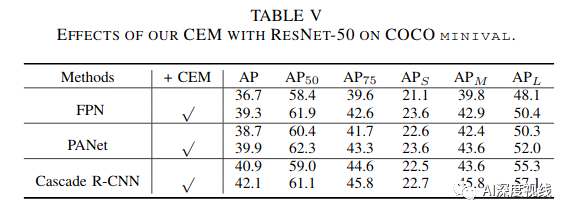
可变卷积的影响:
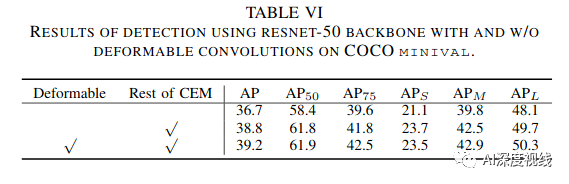
稠密连接:
3.2 AM
CxAM和CnAM效果:
注意力可视化:

3.3 其他实验
计算复杂度和效率的比较:
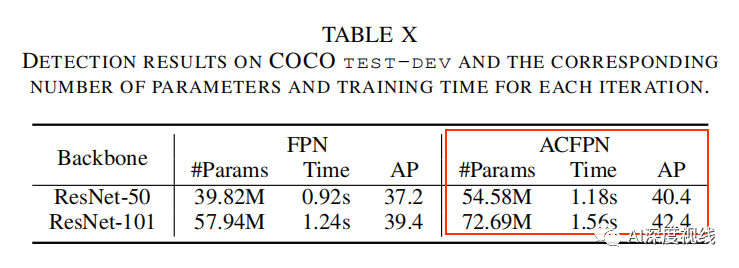
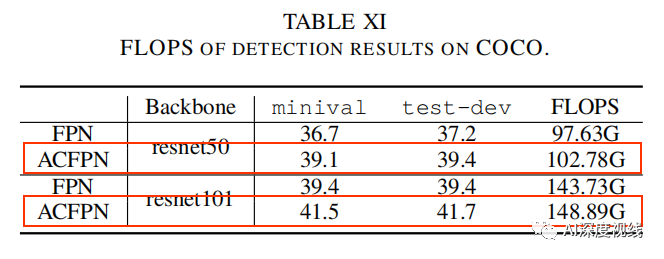
由下表X和XI可以看出,ACFPN较FPN增加的有限的计算复杂度,但精度确提升明显: 骨干网络为ResNet50 时,ACFPN完成一次迭代所需的时间为1.18s,虽然较FPN的0.92s多了0.26s的时延,但精度可以提升3.2个百分点。如果对精度要求较高的场景,可以采用本文的改进策略,并且ACFPN在ResNet-50骨干网络情况下,可以超过FPN在ResNet101骨干网络下的AP精度,且参数量要更低,时间也更快。
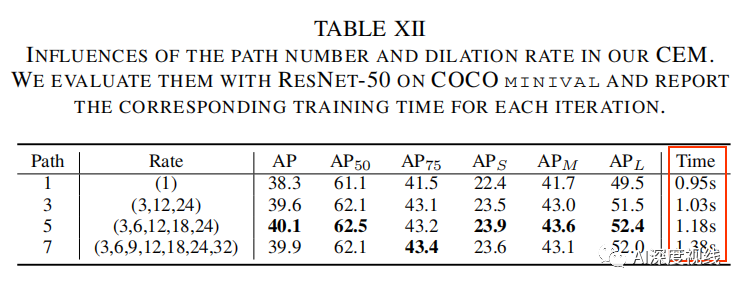
CEM的path数量:
下表为CEM采用不同Rate对结果的影响和相应的时间对比,可以看出,并不是CEM的path数量越多越好,但是却可以看出对于大分辨率的输入图像,有必要提升一定Path数量,可以有效提升精度。
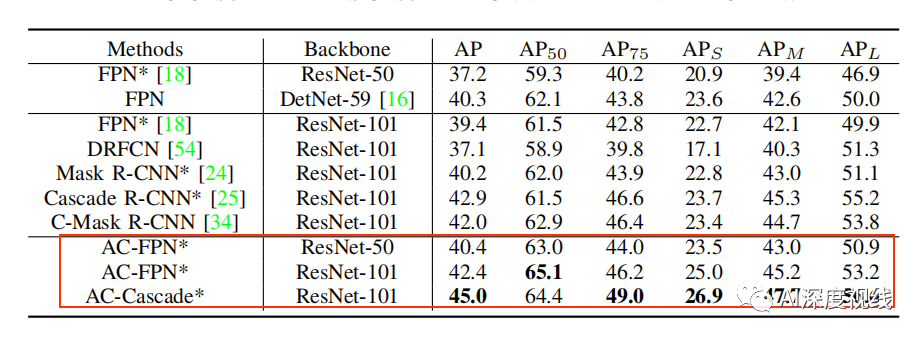
3.4 和其他方法比较
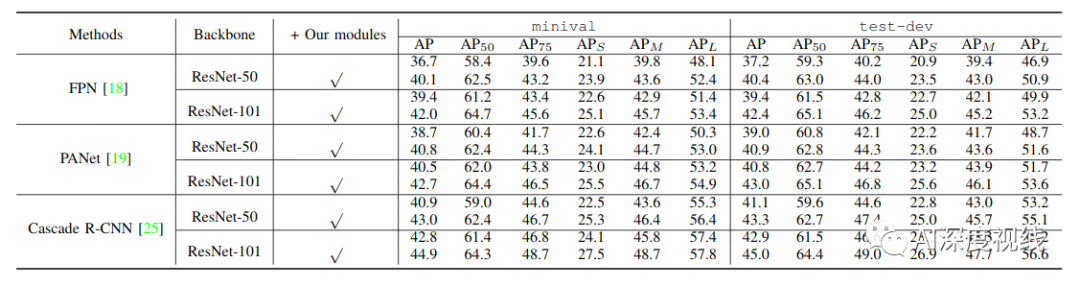
在现有骨干上换上我们的模块结果对比:轻轻松松涨2-3%个点!
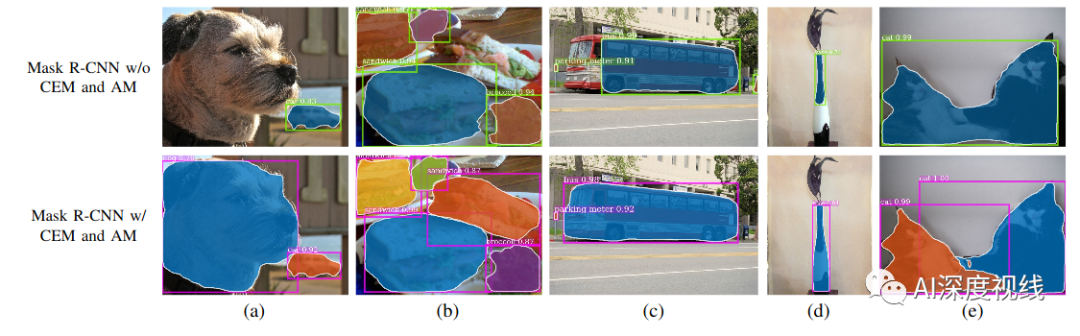
上面一行是原始FPN,下面一行是加上本文改进的FPN:有效减少漏检情况,和提升分割效果。

4
代码实操
模型训练:
在Maxwell的GPU(例如M40)上,训练大概需要4.2小时
推断时间应该在80ms左右/图像(也是在M40上)
python tools/train_net.py \configs/getting_started/tutorial_1gpu_e2e_faster_rcnn_R-50-FPN.yaml \OUTPUT_DIR /tmp/detectron-output
COCO数据测试:
在NVIDIA Tesla P100 GPU上,每幅图像的推理时间应该在130-140毫秒之间。
python tools/test_net.py \configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml \TEST.WEIGHTS https://s3-us-west-2.amazonaws.com/detectron/35861858/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml.02_32_51.SgT4y1cO/output/train/coco_2014_train:coco_2014_valminusminival/generalized_rcnn/model_final.pkl \NUM_GPUS 1
mask-rcnn批量图像测试举例:
python tools/infer_simple.py \configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml \--output-dir /tmp/detectron-visualizations \--image-ext jpg \--wts https://s3-us-west-2.amazonaws.com/detectron/35861858/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml.02_32_51.SgT4y1cO/output/train/coco_2014_train:coco_2014_valminusminival/generalized_rcnn/model_final.pkl \demo

论文下载
在CVer公众号后台回复:AC-FCN,即可下载本论文
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4000人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看




