SIGIR 2021 | PCF-GNN:基于预训练图神经网络的显式交叉语义建模方案
Explicit Semantic Cross Feature Learning via Pre-trained Graph Neural Networks for CTR Prediction. SIGIR 2021
论文下载:请戳文章底部「阅读原文」
▐ 1. 背景
在CTR预估场景中,建模特征之间的交互关系是提升模型预估能力的关键之一。比如,在淘宝场景中,一个职业为篮球运动员的用户可能经常点击“Nike-Air Jordan”相关的商品;而一位职业为程序员的用户可能更喜欢点击数码产品。这些例子表明,职业和商品这两个特征之间的交互,即<职业,商品>,可以作为一个比较强的信号来帮助CTR的预估。
目前针对交叉特征的建模,主要分为两大类方法:隐式语义建模和显式语义建模。
-
隐式语义建模:其核心思想是设计一种交叉网络结构,希望通过网络结构自身的表达能力来学习特征之间的交互信息(比如Wide&Deep[1],DeepFM[2],DCN[3]等等)。尽管,这类方法在工业界以及学术界都被证明能够取得不错的效果。然而其学习得到的交叉语义往往是隐式的,我们很难保证学习到的语义信息是我们想要的。
-
显式语义建模:常用的一种建模方式是利用交叉统计特征来进行显式语义的刻画。具体而言,交叉统计特征可以被看作是特征间历史交互次数的统计。比如,我们可以统计历史中所有职业是篮球运动员的用户点击商品“Nike-Air Jordan”的点击率,将这个统计的点击率作为对应样本在<职业,商品>上的交叉统计特征。显然,这样一种交叉统计值能够显式的反应出特征之间的交互关系,即值越大对应特征之间的相关性越高。
现有的大多数方法主要聚焦在隐式语义建模,而极少关注于显式语义建模。其往往简单的采用交叉统计特征来补充交叉特征的显式语义部分。然而直接利用交叉统计特征存在着两大挑战:
-
泛化性能差:交叉统计特征主要是依赖于历史的统计,因此是无法推断历史中从未出现过的交叉特征pair对的统计值。
-
存储开销大:在线服务的时候,针对交叉统计特征,我们往往需要维护一张<交叉特征,统计值>的映射表,比如<<篮球运动员,“Nike-Air Jordan”>,0.6>可以被看成这张表中的一条数据。在大规模场景中,维护这样一张映射表的存储成本是巨大的,存储开销是特征笛卡尔积的量级,即 ,其中 和 是对应特征的vocabulary size。尤其是当涉及的特征词表量巨大的时候(比如User ID,可能是亿级别的),这张映射表将极大影响在线存储效率。
少有工作站在显式语义建模的角度来解决这两大挑战。针对这些挑战,我们提出了一种基于预训练图神经网络的交叉语义特征学习模型(PCF-GNN),通过该模型能够刻画显式交叉语义信息同时减少存储开销。具体来讲,鉴于特征交互可以自然的以图的形式表达以及通过挖掘图结构有利于我们充分理解特征交互,我们首先将特征间的历史交互信息以图的形式来表示。其中,图中的节点表示特征,边表示特征间的历史交互,边上的属性信息表示交叉统计值。然后,我们设计了基于边属性预测的预训练任务,来预训练图神经网络,赋予其对应的领域知识。通过这样一种任务,使得模型有能力来推断边属性(即交叉统计值),即使是在训练集中未曾出现的边(解决挑战一);同时,推断的方式避免了直接去存储映射表(解决挑战二)。下面,我们具体介绍PCF-GNN。
▐ 2. 模型:PCF-GNN
在这一章,我们将介绍所提的模型。整体来看,PCF-GNN分为两个阶段:预训练阶段和下游任务应用阶段。
2.1 预训练阶段
2.1.1 图构建
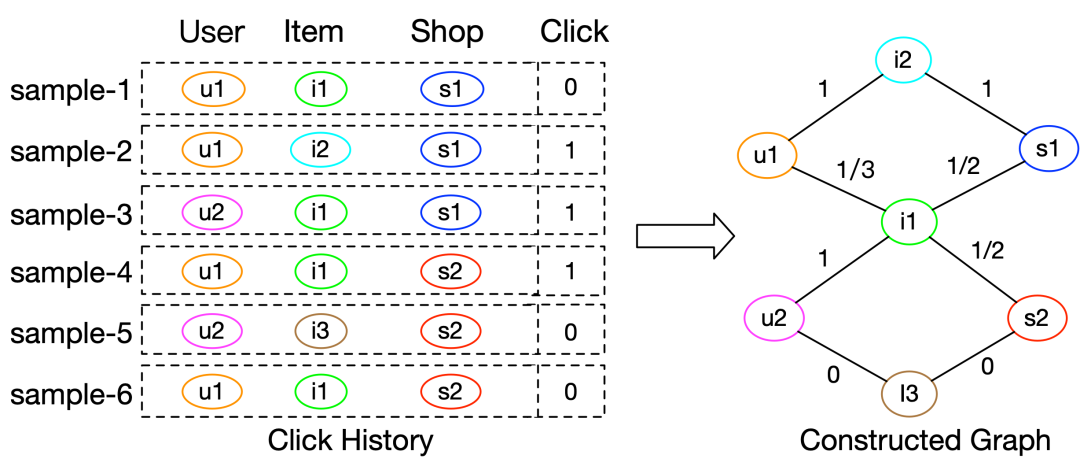
如图1所示,给定用户的历史点击信息,我们以交叉特征<User,Item>和<Item,Shop>为例来构建图网络。图网络中,节点表示特征,边表示历史交互,边属性表示交叉统计值。具体而言,边 的边属性 可以通过一下公式来计算:
其中 表示特征 和 在历史中共现的次数。 刻画了特征 和 的显式语义信息。
2.1.2 预训练任务设计
预训练的核心目标是为了赋予图神经网络关于显式交叉语义的领域知识。因此,我们设计了边属性预测的预训练任务,即:
其中 是PCF-GNN的输出。
这样以来,通过 的指导,可以使得学习到的 能够表达显式的交叉语义。
2.1.3 网络结构设计
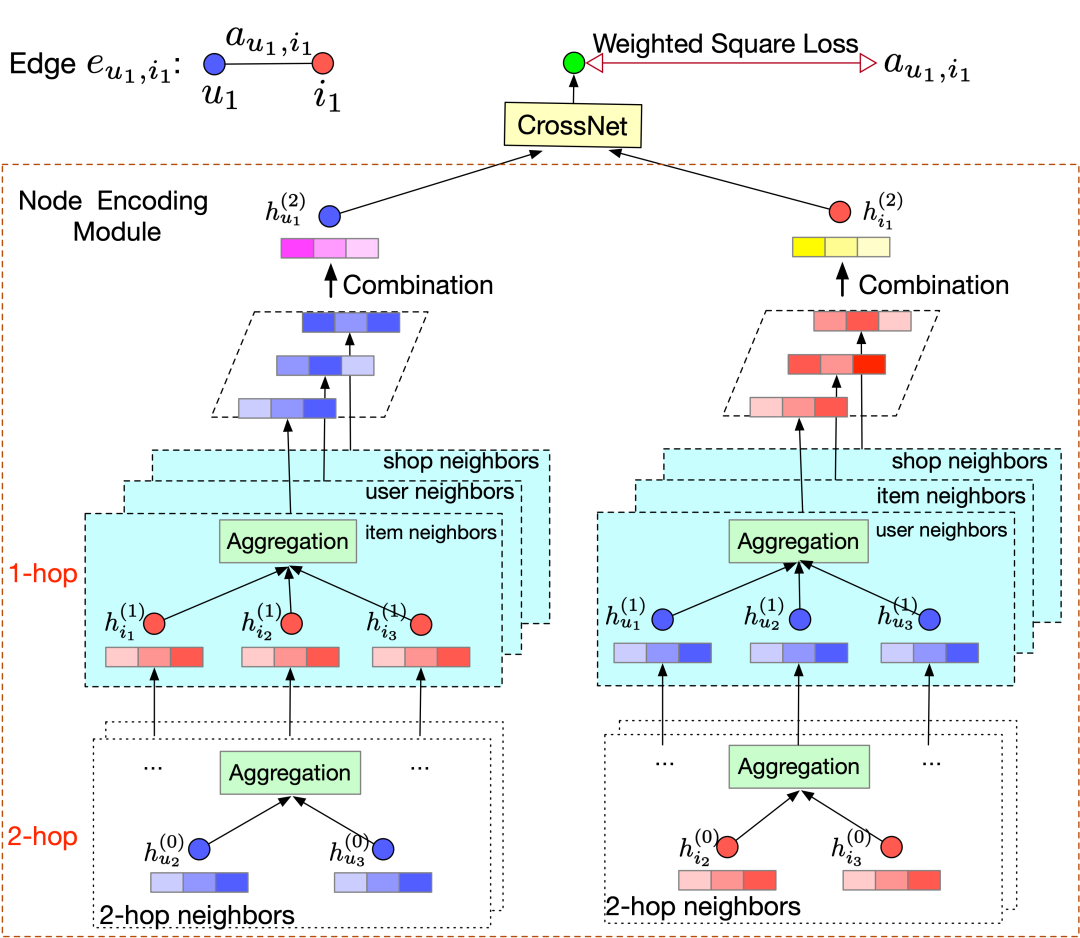
如图2所示,PCF-GNN整体可以分为两部分,即Node Encoding Module和CrossNet。
2.1.3.1 Node Encoding Module
该模块简单来看是一个图神经网络,用来刻画节点的邻域信息并学习节点的特征表达。考虑到构造的图是一个异质图,有多种类型的节点和边,因此我们设计了一种基于multi-relation的图神经网络,每一层网络可以被形式化定义为:
其中, 为 节点 在第 层的输出向量。 为和节点 的关系为 的邻居集合。 为 的特征表达。 为节点的属性特征,实际应用中,其为随即初始化向量。 为最后一层的输出,作为节点 的预训练embedding。 和 的具体实现,我们采用了经典的GraphSAGE[4]方法。
2.1.3.2 CrossNet
CrossNet的作用是将node-level的embedding 映射到edge space并且预估对应边的属性特征。形式化来讲,对于边 ,对应的属性可以被预估为:
其中 是边 的属性预估值。在CrossNet的具体实现上,可以是一个简单的点击操作也可以是一层神经网络。
2.1.4 加权平方损失函数
通过CrossNet,我们可以得到边的属性预估值 ,我们可以简单的设计平方损失函数来训练PCF-GNN,即
但是,直接应用平方损失会导致所有的边都会被同等重要的对待。这显然是不太合理的,在CTR预估中,不同边的重要程度是不同的。比如,<篮球运动员,“Nike-Air Jordan”>显然比<篮球运动员,鼠标>在历史中出现的频次更高。如果,我们对于这两条边给予相同的损失权重,那么模型就很难去分辨到底那一条边更加重要,导致CTR模型可能会推荐鼠标给篮球运动员。为了解决这样一个问题,我们提出了一种简单又有效的加权平方损失函数。核心思想就是,通过特征的共现次数对每一条边的损失进行加权,即:
其中, 是一种平滑操作来防止过大的 , 是一个正常数(默认为1)被用来防止 的结果为0。
2.2 下游任务应用阶段
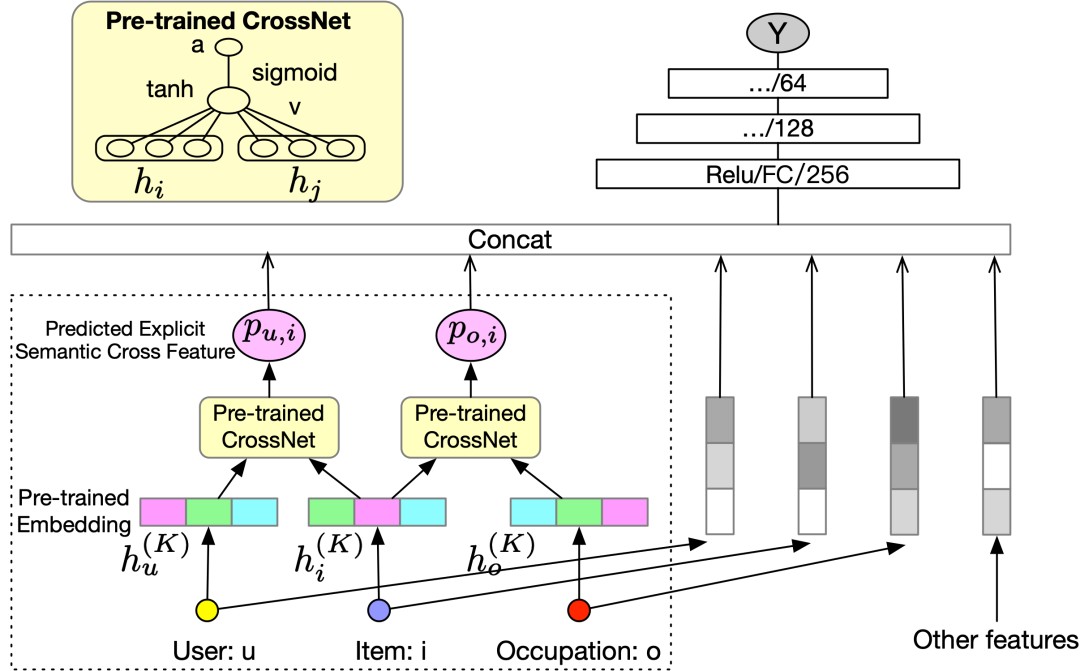
这里我们主要将预训练得到的PCF-GNN应用于CTR任务(其他相关任务也可以应用)。如图3所示,右边部分是一个标准的Embedding&MLP结构的CTR模型。我们可以将PCF-GNN预估值 和CTR模型的Embedding结果拼接起来一起送到MLP中去。这样以来,通过 ,可以让CTR模型感知显式的交叉语义信息。
在这一个阶段,可以采用fix参数或者fine-tuning参数的两种策略。当fix参数的时候,从效率角度考虑,我们可以直接将node encoding module舍弃,直接将其输出 保留下来,以此避免这一部分的前向计算(如图3虚线框中所示)。当fine-tuning的时候,则需要保留完整的PCF-GNN。
2.3 讨论
这里简单讨论一下,所提模型是如何解决传统交叉统计特征存在的两大挑战的。
-
泛化性:在PCF-GNN中,显式交叉语义可以通过节点的预训练embedding来推断出边的属性(即交叉语义)。因此,对于历史中从来没有出现过的交叉pair对,只需要拿其对应的节点embedding进行推断即可。
-
存储:如上面介绍,交叉统计特征的存储开销是 量级的,而对于PCF-GNN而言,主要的存储开销在于存储每个节点预训练的embedding,即 其中d是embedding的维度。考虑到在大规模应用场景中, 和 通常是远大于 的,因此,存储可以从 降到 。
▐ 3. 实验
3.1 Setting
-
数据集
-
公开数据集:MovieLens[5] -
内部数据:Alibaba -
baseline
-
常规隐式交叉语义模型:Wide&Deep[1],DeepFM[2],AutoInt[6],FiBiNet[7]. -
基于图神经网络的隐式交叉语义模型:Fi-GNN[8]. -
图预训练模型:GraphSAGE[4], PGCN[9].
3.2 CTR 预估任务
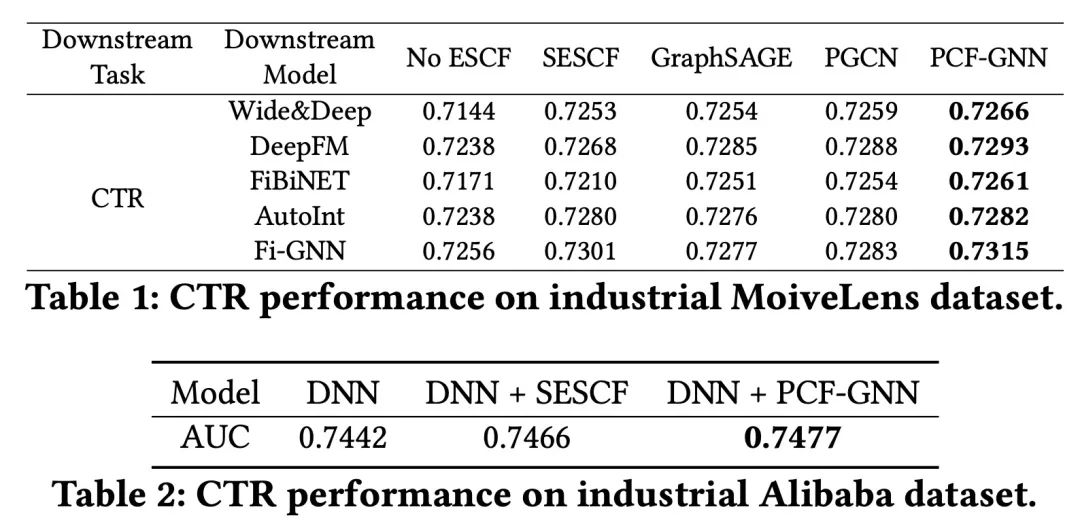
我们分别在公开数据集和内部数据上进行了评测,以AUC为评估指标,结果如表1和表2所示。其中ESCF指代交叉语义特征,SESCF指带交叉统计特征,DNN指代Wide&Deep。
可以看到,无论是相比于没有显式语义的模型(表1第3列),还是加上交叉统计特征的模型(表1第4列),还是其他图预训练模型(表1第5和第6列),PCF-GNN都能取得明显的提升。
3.3 泛化性能评估
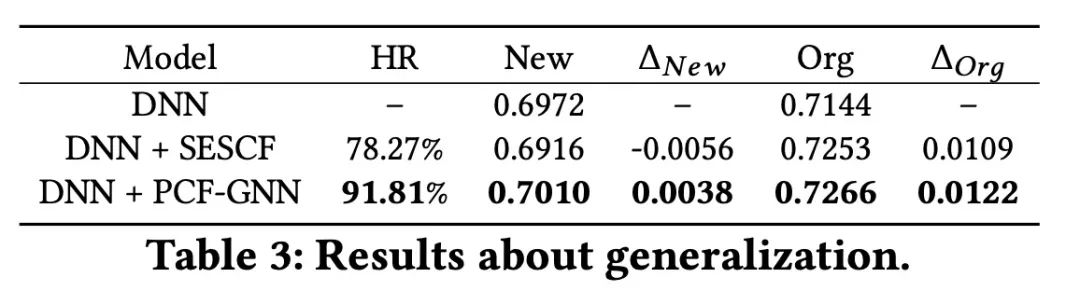
我们将那些特征中包含新交叉pair对的样本挑选出来,组成一个 的测试集,原始的测试集记为 。通过评估在 集合上AUC表现,来评估模型的泛化性。
如表3所示,其中HR表示,对应模型在 集合上交叉特征能覆盖样本的比例。 表示与原始DNN模型的gap。
可以看到,PCF-GNN无论是在覆盖率还是在 表现上,都是更好的。
3.4 存储开销评估
我们对比了采用交叉统计特征和PCF-GNN在模型存储上的开销,见表4. 可以看到,通过PCF-GNN可以节省一半多的存储开销。此外,在实际应用中,我们还可以采用hash embedding的技术来对PCF-GNN的embedding开销进行进一步的缩减。

3.5 Online效果
我们在线上模型中通过PCF-GNN来引入显式交叉语义信息,取得AB实验效果如表5所示。

▐ 4. 结语
通过构建预训练图神经网络模型,在降低存储的同时,成功的刻画出了显式的交叉语义信息。FCN-GNN是我们团队继GIN[10]后在图神经网络和CTR模型建模上的又一次尝试。希望可以为从事相关工作的同学带来一些启发和帮助。


