基于深度交叉特征的推荐系统


特征在许多预测系统中扮演着重要的角色。但是,由于原始低维的特征很难产生较好的结果,于是人们采用一种称为交叉特征的高维特征来提高预测系统的性能。交叉特征即合并低维特征形成更高维的特征。可是要挑选高质量的低维特征需要依据不同的任务采取不同的策略,而且一般低维特征有成千上万个,所以导致特征工程会花费大量的精力和时间。如何自动学习交叉特征成为预测系统中一个很有意义的任务。
本篇文章带大家来阅读一篇来自KDD 2018的文章:
xDeepFM:
Combining Explicit and Implicit Feature Interactions for Recommender Systems
(https://arxiv.org/pdf/1803.05170.pdf)
该论文主要提出了一种自动化交叉低维显示特征和高维隐式特征的模型(Compressed Interaction Network)。另外文中还将CIN模型和Wide&Deep【1】进行了结合,提出了xDeepFM的模型结构。这篇文章提出的方法在Criteo, Dianping, Bing News上都超过了现有最好的分数。
>>>CIN模型介绍
首先我们来看一下CIN模型:

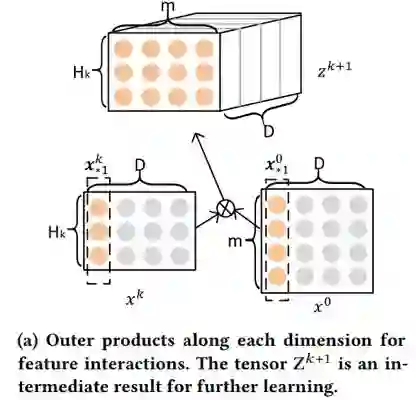
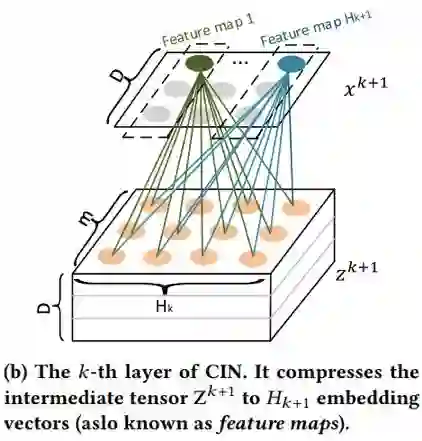
模型如上图所示。首先获得各个离散特征的embedding向量,并将它们合并成一个矩阵。
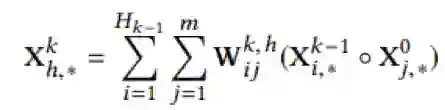
其中k是层数,i和j是特征的序号。这个公式的物理意义就是说将每个高维特征和低维特征进行交叉,生成更高维的特征。整个CIN的结构如图c所示,它是类似一个RNN的结构,每多一层相当于获得更高维的特征,例如,第二层,相当于二阶交叉特征。最后我们将每层的输出向量进行合并,产生最终的交叉特征表示。
>>>xDeepFM介绍
为了充分利用低维和高维特征,作者将CIN与当今最流行的推荐框架Wide&Deep进行了结合,创造了eXtreme Deep Factorization Machine(xDeepFM).
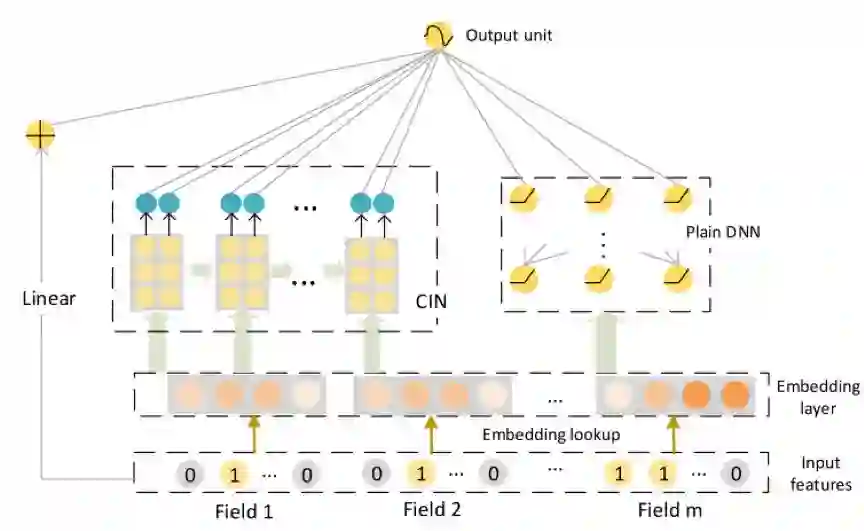
如上图所示,最后的输出层结合了linear,CIN,DNN的结果。

对于二分类的问题,损失函数是:

实验数据采用了三个数据集合Criteo, 大众点评数据,Bing新闻搜索数据。
评价指标采用的是AUC

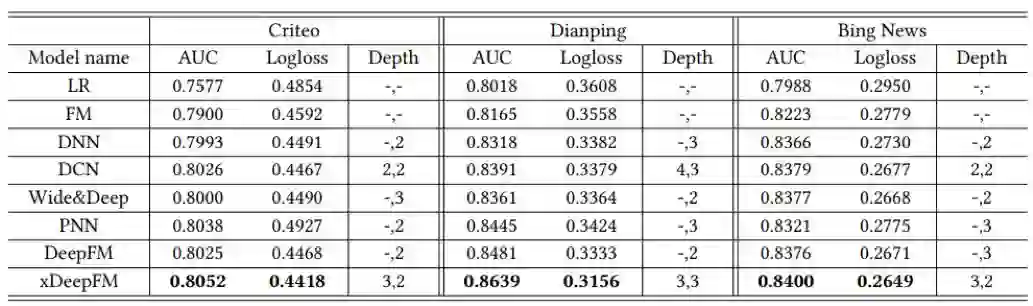
从上表中可以看出CIN模型的AUC超过了当前所有的方法。最后一列是模型的层数。实验的参数设置如下,学习率统一设置成0.001,mini-batch大小是4096。对于criteo数据,使用200维度的CIN layers;对于Dianping和Bing新闻,使用100维度的CIN layers。CIN如果层数超过3层,就会有过拟合的问题
上图是xdeepFM的实验结果。CIN和Wide&Deep结合后依然能够取得一定的性能提升。
下面我们来看一下,不同参数对于AUC的影响。主要参数是CIN的层数,每一层的神经元节点个数,激化函数
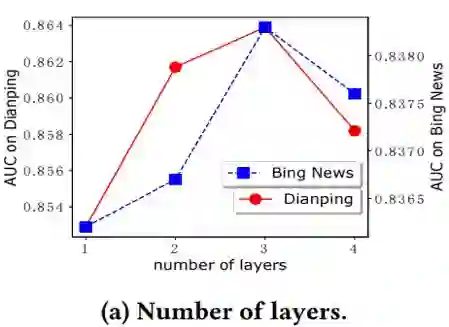

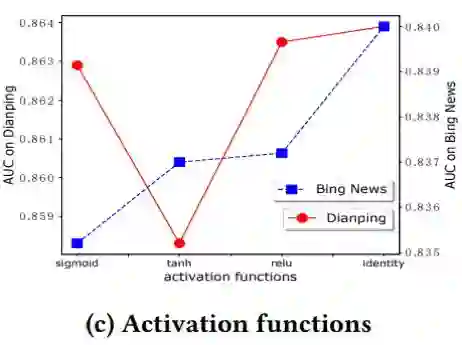
论文提出的模型在CrossNet【2】的基础上进行了一些改进,克服了bit特征(特征中某一维)交叉的缺点,使用了基于field(特征粒度)交叉,并结合了Wide&Deep的框架优势,取得了超过现有模型的分数。作者在论文中也公布了相应的源码,感兴趣的同学可以去查阅:https://github.com/ Leavingseason/ xDeepFM.
参考文献
【1】Heng-Tze Cheng, Levent Koc,Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson,Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning forrecommender systems. In Proceedings of the 1st Workshop on Deep Learning forRecommender Systems. ACM, 7–10.
【2】Ruoxi Wang, Bin Fu, Gang Fu,and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions.arXiv preprint arXiv:1708.05123 (2017).

 微信ID:WeChatAI
微信ID:WeChatAI

登录查看更多
相关内容
专知会员服务
159+阅读 · 2020年4月2日
专知会员服务
71+阅读 · 2020年2月5日
Arxiv
9+阅读 · 2018年5月30日




相关VIP内容
专知会员服务
159+阅读 · 2020年4月2日
专知会员服务
71+阅读 · 2020年2月5日
相关资讯