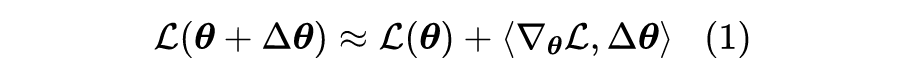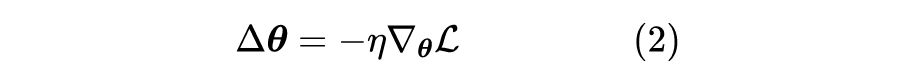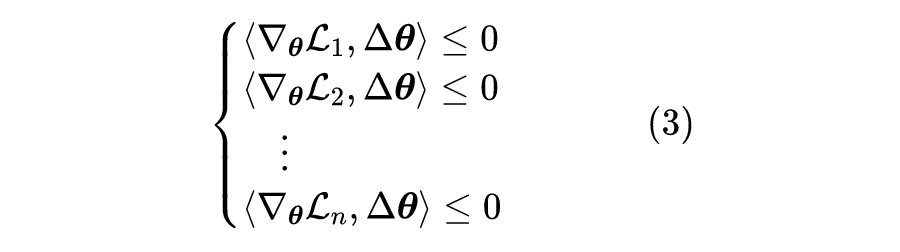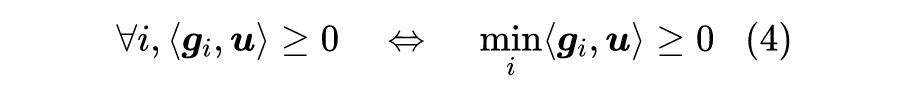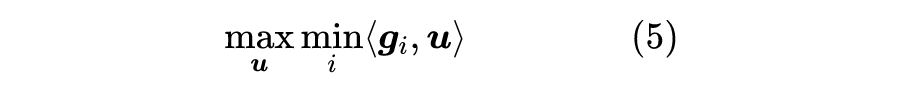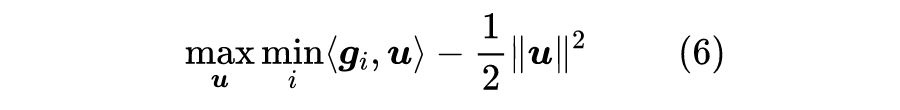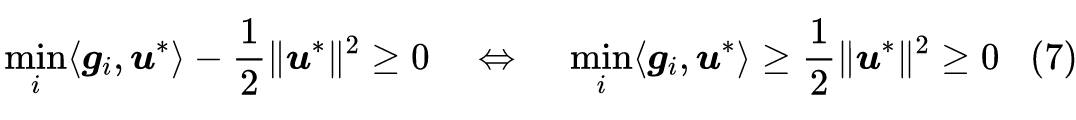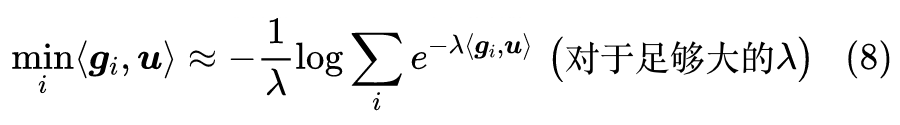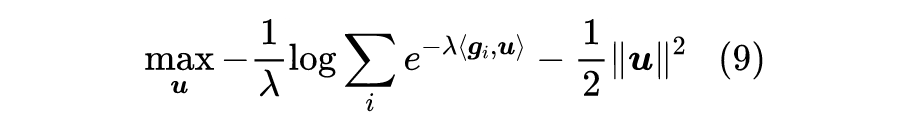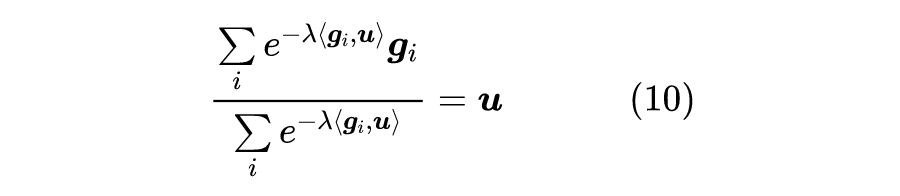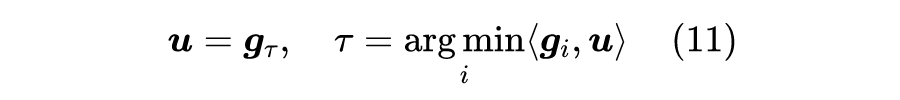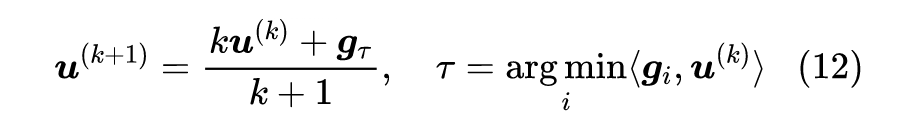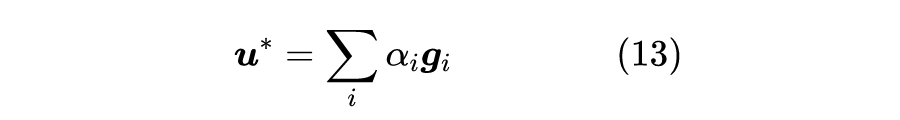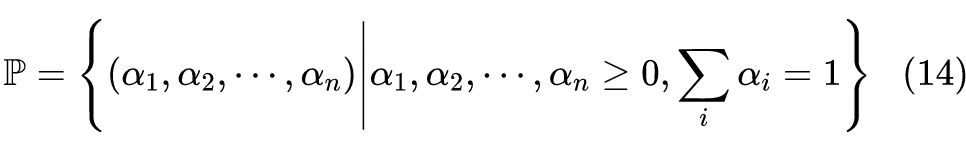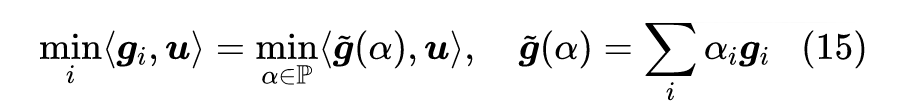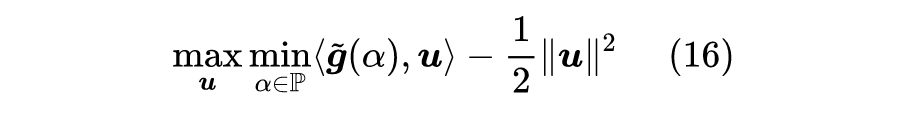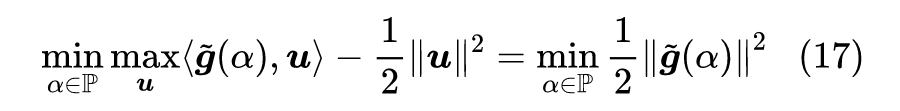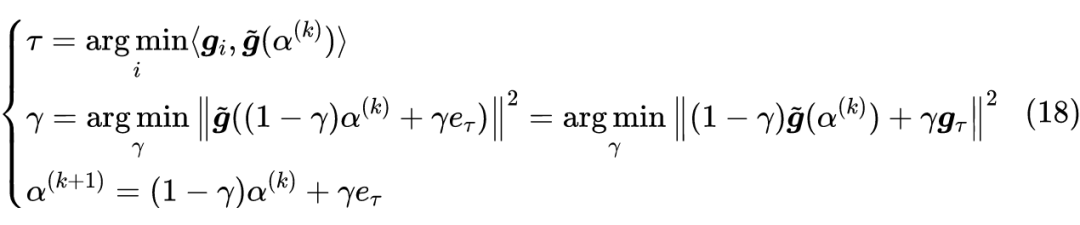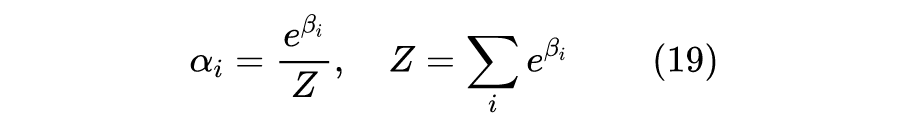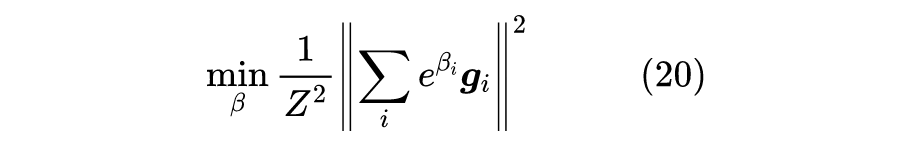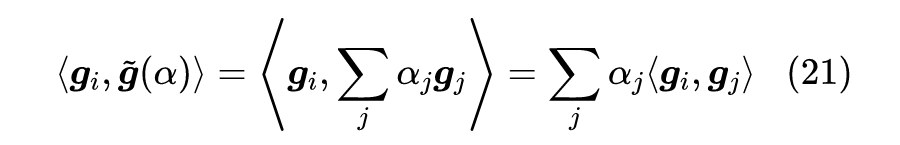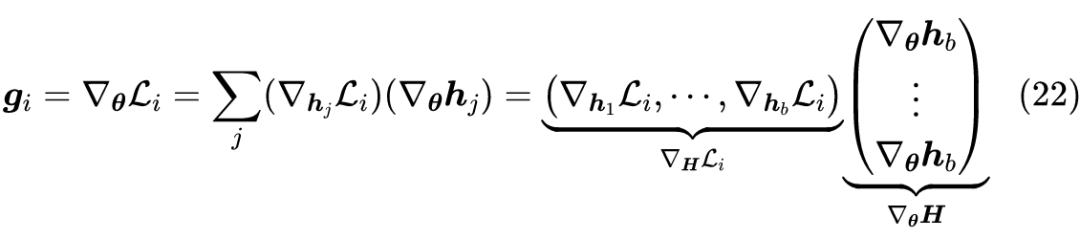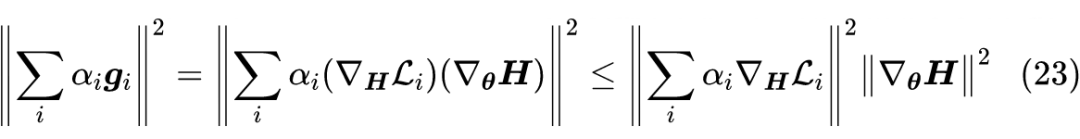![]()
©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
在《多任务学习漫谈:以损失之名》中,我们从损失函数的角度初步探讨了多任务学习问题,最终发现如果想要结果同时具有缩放不变性和平移不变性,那么用梯度的模长倒数作为任务的权重是一个比较简单的选择。我们继而分析了,该设计等价于将每个任务的梯度单独进行归一化后再相加,这意味着多任务的“战场”从损失函数转移到了梯度之上:看似在设计损失函数,实则在设计更好的梯度,所谓“以损失之名,行梯度之事”。
那么,更好的梯度有什么标准呢?如何设计出更好的梯度呢?本文我们就从梯度的视角来理解多任务学习,试图直接从设计梯度的思路出发构建多任务学习算法。
整体思路
我们知道,对于单任务学习,常用的优化方法就是梯度下降,那么它是怎么推导的呢?同样的思路能不能直接用于多任务学习呢?这便是这一节要回答的问题。
![]()
假设这个近似的精度已经足够,那么
意味着
,即更新量与梯度的夹角至少大于 90 度,而其中最自然的选择就是
这便是梯度下降,即更新量取梯度的反方向,其中
即为学习率。
![]()
回到多任务学习上,如果假设每个任务都同等重要,那么我们可以将这个假设理解为每一步更新的时候
都下降或保持不变。如果参数到达
后,不管再怎么变化,都会导致某个
上升,那么就说
是帕累托最优解(Pareto Optimality)。说白了,帕累托最优意味着我们不能通过牺牲某个任务来换取另一个任务的提升,意味着任务之间没有相互“内卷”。
假设近似(1)依然成立,那么寻找帕累托最优意味着我们要寻找
满足
![]()
注意到它存在平凡解
,所以上述不等式组的可行域肯定非空,我们主要关心可行域中是否存在非零解:如果有,则找出来作为更新方向;如果没有,则有可能已经达到了帕累托最优(必要不充分),我们称此时的状态为帕累托稳定点(Pareto Stationary)。
![]()
方便起见,我们记
,我们寻求一个向量
,使得对所有的
都满足
,那么我们就可以像单任务梯度下降那样取
作为更新量。如果任务数只有两个,可以验证
自动满足
和
,也就是说,双任务学习时,前面说的梯度归一化可以达到帕累托稳定点。
当任务数大于 2 时,问题开始变得有点复杂了,这里介绍两种求解方法,其中第一种思路是笔者自己给出的推导结果,第二种思路则是《Multi-Task Learning as Multi-Objective Optimization》
[1]
给出的“标准答案”。
![]()
![]()
所以我们只需要尽量最大化最小的那个
,就能找出理想的
,即问题变成了
![]()
不过这有点危险,因为一旦真的存在非零的
使得
,那么让
的模长趋于正无穷,那么最大值便会趋于正无穷。所以为了结果的稳定性,我们需要加个正则项,考虑
![]()
这样无穷大模长的
就不可能是最优解了。注意到代入
后有
,所以假设对
取
的最优解为
,那么必然有
![]()
所以问题(6)的解必然是满足条件(4)的解,并且如果是非零解,那么其反方向必然是使得所有任务损失都下降的方向。
![]()
现在介绍问题(6)的第一种求解方案,它假设读者像笔者一样不熟悉 min-max 问题的求解,那么我们可以将第一步的
用光滑近似代替(参考《寻求一个光滑的最大值函数》
[2]
),即
![]()
![]()
然后再让
。这样我们就将问题转化为了单个函数的无约束最大化问题,直接求梯度然后让梯度为零得到
![]()
假设各个
的差距大于
量级,那么当
时,上式实际上是
![]()
然而,如果直接按照 的格式迭代,那么大概率是会振荡的,因为它要我们找到让
最小的
作为
,假设为
,那么下一步让
最小的
就很可能不再是
了,反而
可能是最大的那个。
直观来想,上述算法虽然振荡,但应该也是围绕着最优点
振荡的,所以如果我们把振荡过程中的所有结果都平均起来,就应该能得到最优点了,这意味着收敛到最优点的迭代格式是
![]()
留意到每次叠加上去的都是某个
,所以最终的
必然是各个
的加权平均,即存在
且
,使得
![]()
我们也可以将
理解为各个
的当前最优权重分配方案。
![]()
光滑近似技巧的好处是比较简单直观,不需要太多的优化算法基础,不过它终究只是“非主流”思路,有颇多不严谨之处(但结果倒是对的)。下面我们来介绍基于对偶思想的“标准答案”。
![]()
![]()
上述函数关于
是凹的,关于
是凸的,并且
的可行域都是凸集(集合中任意两点的加权平均仍然在集合中),所以根据冯·诺依曼的 Minimax 定理
[3]
,式 (16)的
和
是可以交换的,即等价于
等号右边是因为
部分只是一个无约束的二次函数最大值问题,可以直接算出
,因此最后只剩下
,问题变成了求
的一个加权平均,使得其模长最小。
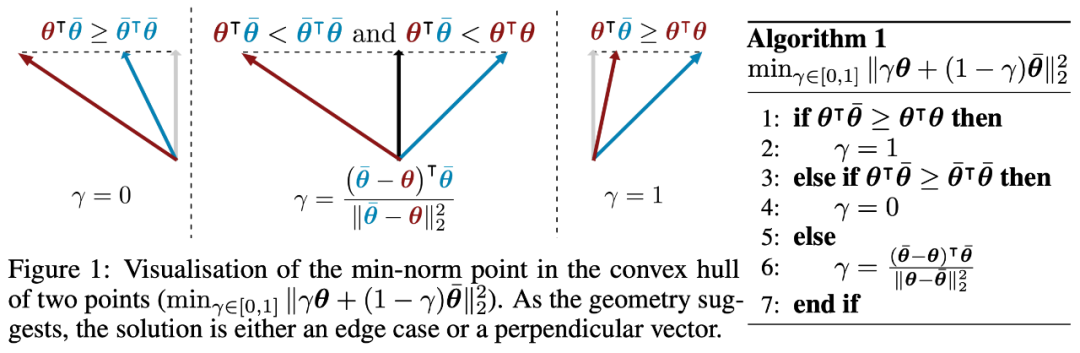
当
时,问题的求解比较简单,相当于作三角形的高,如下图所示:
当
时,我们可以用 Frank-Wolfe 算法
[4]
将它转化为多个
的情形进行迭代。对于 Frank-Wolfe 算法,我们可以将它理解为带约束的梯度下降算法,适合于参数的可行域为凸集的情形,但展开来介绍篇幅太大,这里就不详说了,请读者自行找资料学习。简单来说,Frank-Wolfe 算法先通过线性化目标,找到下一步更新的方向为
,其中
而
为
位置为 1 的 one hot 向量,然后求解在
与
之间进行插值搜索,找出最优者作为迭代结果。所以,它的迭代过程为
![]()
其中
的求解,正是
的特例,用上述截图中的算法即可。如果
不通过搜索而得,而是固定为
,那么结果则等价于(12),这也是 Frank-Wolfe 算法的一个简化版本。也就是说,我们通过光滑近似得到的结果,跟简化版 Frank-Wolfe 算法的结果是等价的。
![]()
其实对于问题(17)的求解,理论上我们也可以通过去约束的方式直接用梯度下降求解。比如直接设参数
以及
![]()
![]()
这是个无约束的优化问题,常规的梯度下降算法就可以求解。然而不知道为什么,笔者似乎没看到这样处理的(难道是不想调学习率?)。
![]()
在前一节中,我们给出了寻找帕累托稳定点的更新方向的两种方案,它们都要求我们在每一步的训练中,都要先通过另外的多步迭代来确定每个任务的权重,然后才能更新模型参数。由此不难想象,实际计算的时候计算量还是颇大的,所以我们需要想些技巧降低计算量。
![]()
梯度内积
可以看到,不管哪种方案,其关键步骤都有
,这意味着我们要遍历梯度算内积。然而在深度学习场景下,模型参数量往往很大,所以梯度是一个非常大维度的向量,如果每一步迭代都要算一次内积,计算量很大。这时候我们可以利用展开式
![]()
每次迭代其实只有
不同,所以其实在每一步训练中
只需要计算一次存下来就行了,不用重复这种大维度向量内积的计算。
![]()
然而,当模型大到一定程度的时候,要把每个任务的梯度都分别算出来然后进行迭代计算是难以做到的。如果我们假设多任务的各个模型共用同一个编码器,那么我们还可以进一步近似地简化算法。
具体来说,假设 batch_size 为
,第
个样本的编码输出为
,那么由链式法则我们知道:
![]()
![]()
不难想到,如果我们最小化
,那么计算量就会明显减少,因为这只需要我们对最后输出的编码向量的梯度,而不需要对全部参数的梯度。而上式告诉我们,最小化
实际上就是在最小化式(17)的上界,像很多难以直接优化的问题一样,我们期望最小化上界也能获得类似的结果。
不过,这个上界虽然效率更高,但也有其局限性,它一般只适用于每一个样本都有多种标注信息的多任务学习,不适用于不同任务的训练数据无交集的场景(即每个任务是对不同的样本进行标注的,单个样本只有一种标注信息),因为对于后者来说,各个
是相互正交的,此时任务之间没有交互,上界没有体现出任务之间的相关性,也就是过于宽松而失去意义了。
![]()
前面所提到的“标准答案”以及关于共享编码器时优化上界的结果,都来自论文《Multi-Task Learning as Multi-Objective Optimization》
[1]
。接下来原论文试图证明当
满秩时,优化上界也能找到帕累托稳定点。但是很遗憾,原论文的证明是错误的。
证明位于原论文的附录 A,里边用到了一个错误的结论:
经过思考,笔者认为原论文中的证明是难以修复的,即原论文的推测是不成立的,换言之,即便
满秩,优化上界得出的更新方向未必是能使得所有任务损失都不上升的方向,从而未必能找到帕累托稳定点。至于原论文中优化上界的实验效果也不错,只能说深度学习模型参数空间太大,可供“挪腾”的空间也很大,从而上界近似也能获得不错的结果了。
![]()
在这篇文章中,我们从梯度的视角来理解多任务学习。在梯度视角下,多任务学习的主要工作是寻找一个尽可能与每个任务的梯度都反向的方向作为更新方向,从而使得每个任务的损失都能尽量下降,而不能通过牺牲某个任务来换取另一个任务的提升。这是任务之间无“内卷”的理想状态。
[1] https://arxiv.org/abs/1810.04650
[2] https://kexue.fm/archives/3290
[3] https://en.wikipedia.org/wiki/Minimax_theorem
[4] https://en.wikipedia.org/wiki/Frank–Wolfe_algorithm
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()