NIPS 2018 | 作为多目标优化的多任务学习:寻找帕累托最优解
由极市、机器之心和中科创达联合举办的“2018计算机视觉最具潜力开发者榜单”评选活动,现已接受报名,杨强教授、俞扬教授等大牛嘉宾亲自评审,高通、中科创达、微众银行等大力支持,丰厚奖励,丰富资源,千万渠道,助力您的计算机视觉工程化能力认证,提升个人价值及算法变现。极市与您一起定义自己,发现未来~点击阅读原文即可报名~
多任务学习本质上是一个多目标问题,因为不同任务之间可能产生冲突,需要对其进行取舍。本文明确将多任务学习视为多目标优化问题,以寻求帕累托最优解。而经过实验证明,本文提出的方法可以在现实假设下得到帕累托最优解。
统计学中最令人震惊的结论之一是 Stein 悖论。Stein(1956)认为,若要估计高斯随机变量,最好是从所有样本中估计三个或三个以上变量的均值,而不是分别单独进行估计,即使这些高斯分布是相互独立的。Stein 悖论是探索多任务学习(MTL)(Caruana,1997)的早期动机。多任务学习是一种学习范式,其中来自多任务的数据被用来获得优于独立学习每个任务的性能。MTL 的潜在优势超出了 Stein 悖论的直接含义,因为即便是真实世界中看似无关的任务也因数据共享的过程而存在很强的依赖性。例如,尽管自动驾驶和目标操纵看似无关,但相同的光学规律、材料属性以及动力学都对基础数据产生了影响。这启发人们在学习系统中使用多任务作为归纳偏好。
典型的 MTL 系统被给定一组输入点和每点各种任务的目标集。设置跨任务的归纳偏好的常用方法是设计一个参数化假设类,它会在不同任务中共享一些参数。一般而言,可以通过为每个任务最小化经验风险的加权和这种优化问题来学习这些参数。但是,只有当一个参数组在所有任务中都有效时,这样的线性组合公式才有意义。换言之,只有当任务之间不存在竞争关系时,最小化经验风险的加权和才有效,但这种情况比较少有。目标冲突的 MTL 需要对任务之间的权衡进行模型,但这已经超出了线性组合能够实现的范围。
MTL 的另一个目标是找到不受任何其它方案主导的解决方案。据说这种方案就是帕累托最优(Pareto optimal)。本文从寻找帕累托最优解的角度出发探寻 MTL 的目标。
在给定多个标准的情况下,寻找帕累托最优解的问题也被称为多目标优化。目前已有多种多目标优化算法,其中一种叫多梯度下降算法(MGDA),使用基于梯度的优化,证明了帕累托集合上的点是收敛的(Désidéri,2012)。MGDA 非常时候具有深层网络的多任务学习。它可以用每个任务的梯度解决优化问题来更新共享参数。但有两个技术性的问题阻碍了 MGDA 的大规模应用。(i)基本的优化问题无法扩展到高维度梯度,而后者会自然出现在深度网络中。(ii)该算法要求明确计算每个任务的梯度,这就导致反向迭代的次数会被线性缩放,训练时间大致会乘以任务数量。
我们在本文中开发了基于 Frank-Wolfe 且可以扩展到高维问题的优化器。此外,我们还给 MGDA 优化目标提供了一个上界,并表明可以在没有明确特定任务梯度的情况下通过单次反向迭代来计算该优化目标,这使得该方法的计算成本小到可以忽略不计。本文证明,用我们的上界可以在现实假设情况下得到帕累托最优解。最终我们得到了一个针对深度网络多目标优化问题的精确算法,计算开销可以忽略不计。
我们在三个不同的问题上对提出的方法进行了实证评估。首先,我们在 MultiMNIST(Sabour 等人,2017)上做了多数字分类的延伸评估。其次,我们将多标签分类作为 MTL,并在 CelebA 数据集(Liu 等人,2015b)上进行了实验。最后,我们将本文所述方法应用于场景理解问题中。具体而言,我们在 Cityscapes 数据集(Cordts 等人,2016)上做了联合语义分割、实例分割以及深度估计。在我们的评估中,任务数量从 2 到 40 不等。我们的方法明显优于所有基线。
论文:Multi-Task Learning as Multi-Objective Optimization

论文链接:
https://arxiv.org/pdf/1810.04650v1.pdf
摘要:在多任务学习中,要联合处理多个任务,且这些任务间共享归纳偏好。多任务学习本质上是一个多目标问题,因为不同任务之间可能会产生冲突,需要进行取舍。常用的折中方法是优化代理对象(proxy objective),该对象使每个任务损失的加权线性组合最小化。但这种方法只有在任务间不存在竞争关系时才有效,而这种情况是很少发生的。在本文中,我们明确将多任务学习视为多目标优化,最终目标是找到帕累托最优解。为此,本文使用了基于梯度的多目标优化文献中开发的算法。这些算法不能直接应用于大规模学习问题中,因为随着梯度维度和任务数量的增加,算法结果会变得很差。因此我们为多目标损失提出了一个上界,实验结果表明这样可以有效对其进行优化。本文进一步证明,对这个上界进行优化可以在现实假设下得到帕累托最优解。我们将本文提出的方法应用于各种多任务深度学习任务中,包括数字分类、场景理解(联合语义分割、实例分割和深度估计)以及多标签分类,结果表明该方法产生的模型性能比多任务学习公式或单任务训练产生的模型性能更好。
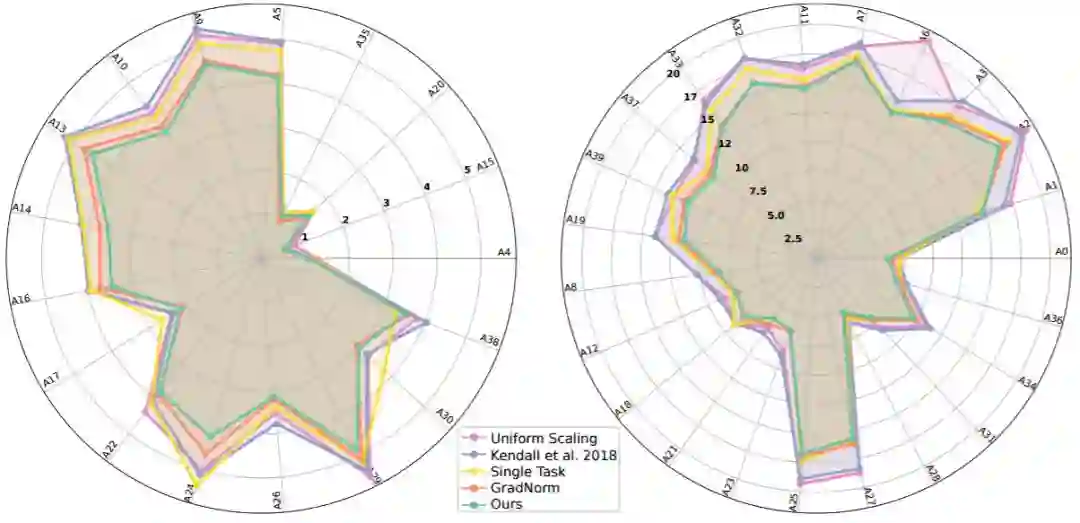
图 2:在 CelebA(Liu 等人,2015b)上得到的每个属性的百分比误差雷达图。该值越低越好。为了方便阅读,将这些属性分为两组:左图容易一些,右图难一些。可放大查看细节。
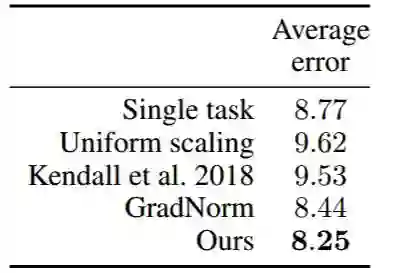
表 1:CelebA(Liu 等人,2015b)上多标签分类中每类 MTL 算法的误差均值。

表 2:MGDA-UB 近似的效果。在使用和不使用该近似的情况下本文所述模型的最终准确率和训练时间。
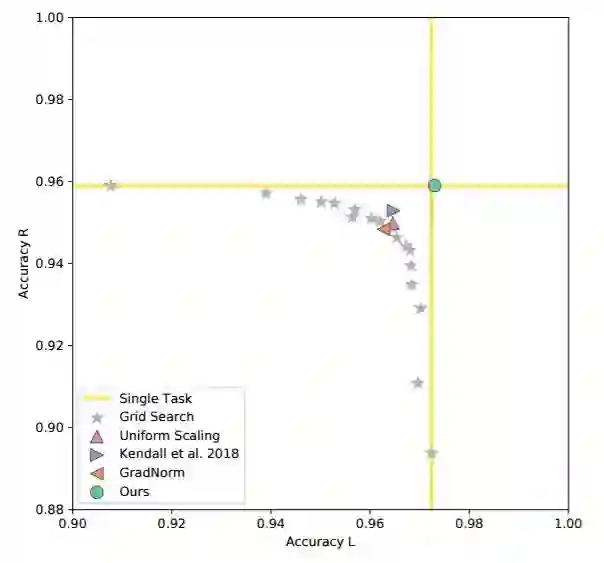
图 3:MultiMNIST 准确率概况。我们绘制了在检测所有基线左右两边数字时获得的准确率。网格搜索结果表明不同任务在竞争模型容量。我们的方法得到的结果和为每个任务单独训练模型的效果一样好。右上角区域表示结果更好。
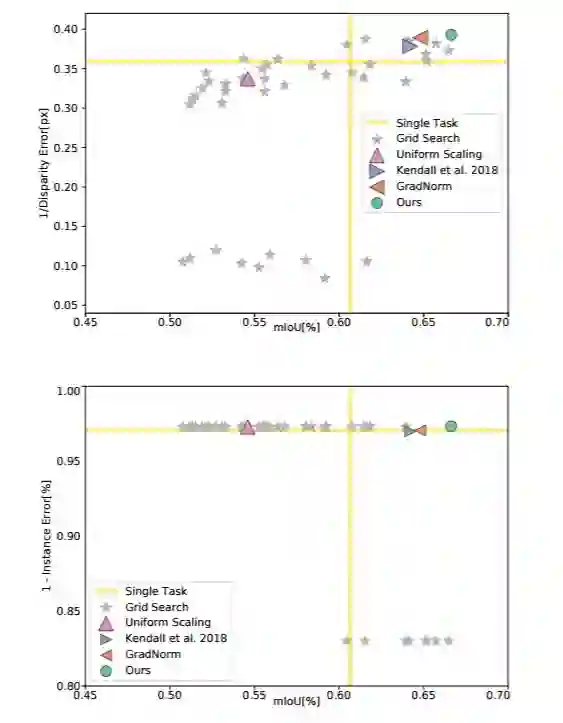
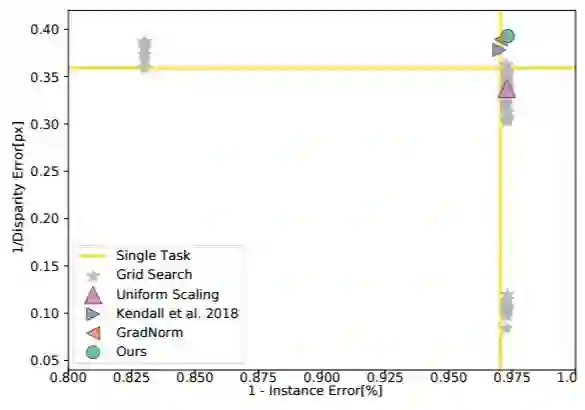
表 4:Cityscapes 性能概况。我们绘制了针对语义分割、实例分割和深度估计等任务的所有基线的性能。尽管绘制了可视化的成对投影,但是图中的每个点都处理了所有任务。右上角区域表示结果更好。
来源:机器之心
*推荐阅读*
极市干货|李骜 多任务学习及其在图像分类中的应用(视频+PPT)
NIPS 2018(oral):通过端到端几何推理发现潜在3D关键点
NIPS 2018 | 中科院自动化所两篇入选论文:高清真实图像生成领域及GAN研究在人脸识别领域的进展
杨强教授、俞扬教授等大牛嘉宾评审团,万元大奖,丰富资源,助力您的计算机视觉工程化能力认证,点击阅读原文即可报名“2018计算机视觉最具潜力开发者榜单”~





