[BTTB] 你不知道的 Softmax

憋说话,先上香。

这篇主要讲大家都熟悉的小伙伴 softmax,多分类概率输出全靠它。
先看 softmax 的定义
假设一个向量 ,对它求 softmax 就是对所有项加上指数函数,然后再除以总和 normalize 一下,就能获得一个新的向量 ,显然 normalize 后的向量加起来和为 1,所以我们可以将这个新向量里的值看作是概率。
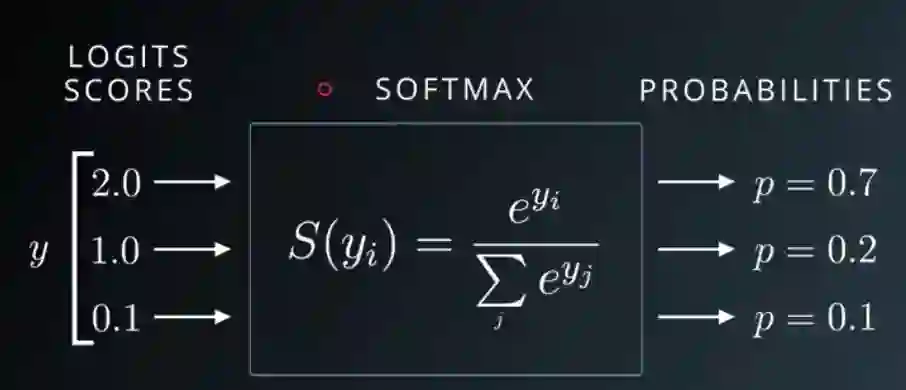
Softmax 上溢出与下溢出
先说说 softmax 应用中的问题,上溢出(Overflow)和下溢出(Underflow)。
首先是上溢出,如果 太大的话,对应的指数函数也会非常大,一旦超出当前精度可表示范围,自然就溢出了,出现的结果一般就是喜闻乐见的 nan.

然后是下溢出,如果向量 中的数都是比较大的负数,那么分母会因为下溢出而变成0,就会导致除 0 问题。
于是有个很简单的技巧一下就能解决这两个问题,加一个简单的运算就行
先找出 中的最大值,然后上下一起除
而上面这个公式与原公式是等价的
通过这个操作,最大的值变成了 ,也就不用担心上溢出了;同时因为分母里至少有一个 1,所以也就避免了下溢出导致的问题。
为什么要 LogSoftmax
之前用一些库的时候一直有一个疑惑,为什么每个框架库里都有个 logsoftmax,而我为什么不能直接 log + softmax.
到底是什么优化呢,其实和上面差不多。
这里后一项有上溢出的风险,因此同样的技巧
因为这一项叫 log-sum-exp 所以这里这个技巧又叫 log-sum-exp trick.
于是最后完整的式子就变成了
细心一点的话就会发现,其实还是对上面 softmax 的技巧直接取对数。
不过明明在介绍 softmax 为什么突然乱入 LogSoftmax,首先因为实际训练中很少直接拿 softmax 作为损失函数,而更多是使用 LogSoftmax;
第二点也是最重要的,其实到现在为止说的 softmax 并不是真正的 softmax,而真正意义上的 softmax 就在 LogSoftmax 中,也就是 log-sum-exp 项。
谁才是真正的 softmax
为什么这么说,其实仔细想想就会发现,softmax 干的根本就不是 max 干的活,它并不是找出一个向量中的最大值。
它反而和 argmax 的作用比较像,这里说的 argmax 和一般用 numpy 里的 argmax 有些细微不同,不是直接返回 index,而是一个 one-hot 向量。
比如说
返回的是一个向量,显然与 max 相比, softmax 更接近 argmax
所以现在用的 softmax 倒不如叫做 softargmax,而对于 max 函数
真正与之像反而是上面提的 log-sum-exp
首先对于 当 X 远大于 a 的时候,可以利用泰勒展开式一阶估算
因此如果 中最大项 比较大的话,通过指数函数进一步放大,那么
后一项如果相差太大可以进一步简化
所以真正 softmax 的名字可能还应该戴在 log-sum-exp 的头上,而现在 softmax 应该叫 softargmax 或者直接叫 softmax 激活函数。
当然因为习惯问题大家也不会去改了,就像历史上的很多东西一样,即使发现真相,但习惯已形成,或者说这个词汇本身的意思已经在使用中发生了变化,这也是语言的魅力所在。

至于为什么现在的 softmax 被这样叫,具体也不清楚,可能只是因为机器学习的流行,然后在机器学习领域大家都这样叫习惯了。
softmax to softmax
最后只要对 log-sum-exp 求导就可以从这个真的 softmax 变成现在这个假的 softmax.
Reference
[1] Quora: Why is softmax activate function called "softmax"?
[2] Wikipedia: LogSumExp
[3] Wikipedia: Softmax function
[4] Exp-normalize trick
[5] Analysis of Softmax Function
推荐阅读
世界读书日,我来凑个单,推荐几本NLP/推荐算法/广告系统/其他相关的新书
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。


